


多维分析后台实践 7:布尔维度和二值维度
【摘要】
用实例、分步骤,详细讲解多维分析(OLAP)的实现。点击了解多维分析后台实践 7:布尔维度和二值维度
实践目标
本期目标,是在完成前几期优化的基础上(特别是上期的分支机构维度序号化),实现布尔维度和二值维度,进一步提升计算速度。
实践的步骤:
1、 准备客户表:修改前几期的代码,将客户表分支机构、职业类型转化为布尔维度,将八个标志位转化为二值维度。
2、 访问客户表:修改查询代码,提高计算速度。
验证布尔维的多维分析计算需求,用存储在 customerEnum.ctx 中的客户数据,如下图:

city 字段存储客户居住城市,取值范围是 1 到 660。
计算需求用下面 Oracle 的 SQL1 表示:
select department_id,job_id,to_char(begin_date,'yyyymm') begin_month ,sum(balance) sum,count(customer_id) count
from customer
where city in (36,37,38,39,40,60,61,62,63,64,65,66,67,68,69,640,641,642,643,644,645,646,647,648,649,650,651,652,653,654,655,656,657,658,659,660)
group by department_id,job_id,to_char(begin_date,'yyyymm') begin_month
验证二值维度的多维分析计算需求,用 SQL2 表示:
select department_id,job_id,to_char(begin_date,'yyyymm') begin_month ,sum(balance) sum,count(customer_id) count
from customer
where flag1=1 and flag2=1 and flag3=1 and flag5=1 and flag6=1 and flag8=1
group by department_id,job_id,to_char(begin_date,'yyyymm') begin_month
准备数据
布尔维度直接采用 customerEnum.ctx 存储方式即可。
二值维度要将 flag1 到 flag8 这 8 个标志位转换为一个整数的 8 个 bit 位来表示。续写 etl.splx,将上期的 customerDept.ctx 转化后,生成组表文件 customerFlag.ctx。代码示例如下:
A |
|
1 |
=file("data/customerDept.ctx").open().cursor() |
2 |
=A1.new(department_id,job_num,employee_id,begin_date,customer_id,first_name,last_name,phone_number,job_title,balance,department_name,vip_id,credit_grade,bits(flag8,flag7,flag6,flag5,flag4,flag3,flag2,flag1):flag) |
3 |
=file("data/customerFlag.ctx").create@y(#department_id,#job_num,#employee_id,#begin_date,#customer_id,first_name,last_name,phone_number,job_title,balance,department_name,vip_id,credit_grade,flag) |
4 |
=A3.append(A2) |
A1:打开 customerDept.ctx 组表文件,建立游标。
A2:生成新游标,用 bits 函数,将原有 8 个字段用一个整数的 8 个 bit 位来表示。例如:flag1 到 flag8 为 1,0,1,1,0,1,1,1,转化为十进制整数是 237。用二进制表示就是 1110 1101,8 个 bit 位从右到左依次对应 flag1 到 flag8。
数据量为一亿,导出组表文件和前期的组表文件比较如下:
期数 |
文件大小 |
说明 |
备注 |
第六期 |
2.6GB |
未做二值维度优化 |
|
第七期 |
2.4GB |
完成二值维度优化 |
从上表可以看出,完成数据类型优化之后,文件大小减少了0.2GB。二值维度的个数越多,优化之后文件变小的越显著。文件变小,能减少磁盘读取数据量,一定程度的提高性能。列存文件,计算时需要读取的字段数量减少,对提升性能帮助较大。
多维分析计算
一、布尔维度
SPL 代码由 olap.splx 和 customerEnum.splx 组成。前者是调用的入口,传入参数是 arg_table、arg_json,后者用来解析 arg_json。
arg_table 的值为 customerEnum。
arg_json 的值为:
{
aggregate:
[
{func:"sum",field:"balance",alias:"sum"},
{func:"count",field:"customer_id",alias:"count"}
],
group:
["department_id","job_id","begin_yearmonth"],
slice:
[
{dim:"city",
value:[36,37,38,39,40,60,61,62,63,64,65,66,67,68,69,640,641,642,
643,644,645,646,647,648,649,650,651,652,653,654,655,656,
657,658,659,660]
}
]
}
customerEnum.splx 代码如下:
A |
B |
C |
|
1 |
func |
||
2 |
if A1.bool!=null |
return string(A1.bool)/"("/A1.dim/")" |
|
3 |
else if A1.value==null |
return "between("/A1.dim/","/A1.interval(1)/":"/A1.interval(2)/")" |
|
4 |
else if ifa(A1.value) |
return string(A1.value)/".contain("/A1.dim/")" |
|
5 |
else if ifstring(A1.value) |
return A1.dim/"==\""/A1.value/"\"" |
|
6 |
else |
return A1.dim/"=="/A1.value |
|
7 |
=json(arg_json) |
=date("2000-01-01") |
|
8 |
=A7.aggregate.(~.func/"("/~.field/"):"/~.alias).concat@c() |
||
9 |
=A7.group.(if(~=="job_id","job_num",~)) |
||
10 |
=A9.(if(~=="begin_yearmonth","begin_date\\100:begin_yearmonth",~)).concat@c() |
||
11 |
=A7.aggregate.(field) |
=A9.(if(~=="begin_yearmonth","begin_date",~)) |
|
12 |
=(A11|C11).id().concat@c() |
||
13 |
=[] |
||
14 |
for A7.slice.derive(null:bool) |
if A14.dim=="begin_date" && A14.value!=null |
>A14.value=int(interval@m(C7,eval(A14.value))*100+day(eval(A14.value))) |
15 |
else if A14.dim=="begin_date" && A14.value==null |
=A14.interval.(~=int(interval@m(C7,eval(~))*100+day(eval(~)))) |
|
16 |
else if A14.dim=="job_id" |
>A14.dim="job_num" |
|
17 |
>A14.value=A14.value.(job.pos@b(~)) |
||
18 |
else if A14.dim=="city" |
=to(660) |
|
19 |
=C18.(A14.value.contain(#)) |
||
20 |
=A14.bool=C19 |
||
21 |
else if like(A14.dim, "flag?") |
>A14.value=int(A14.value) |
|
22 |
=[func(A1,A14)] |
>A13|=B22 |
|
23 |
=A7.group|A7.aggregate.(alias) |
=A23(A23.pos("job_id"))="job(job_num):job_id" |
|
24 |
=A23(A23.pos("begin_yearmonth"))="month@y(elapse@m(date(\""/C7/"\"),begin_yearmonth)):begin_yearmonth" |
||
25 |
=A23(A23.pos("begin_date"))="elapse@m(B4,begin_date\\100)+(begin_date%100-1):begin_date" |
||
26 |
return A12,A8,A10,A13.concat("&&"),A23.concat@c() |
||
A1 到 C6 是子程序,在调用的时候才会执行。为了方便说明,我们按照执行的顺序来讲解。
A7:将 arg_json 解析成序表。解析的结果是多层嵌套的序表,如下图:

其中的 aggregate 为:

其中的 group 为:

其中的 slice 为:

C7:定义起点日期 2000-01-01,用于参数和结果中的日期值转换。
A8:先将 aggregate 计算成冒号相连的字符串序列,再将序列用逗号连接成一个字符串:sum(balance):sum,count(customer_id):count,也就是聚合表达式。
A9:将 group 中的 job_id 替换为 job_num。
A10:将 A8 中的 begin_yearmonth 替换成表达式 begin_date\100:begin_yearmonth。再把 A8 成员用逗号连接成一个字符串 department_id,job_num,begin_date\100:begin_yearmonth,也就是分组表达式。
A11:取得 aggregate 中的 field 字段,也就是聚合表达式用到的所有字段名。
C11:将 group 中的 begin_yearmonth 替换成 begin_date,结果就是分组表达式所用到的所有字段名。
A12:将 A10、C10 合并后,用逗号连接成字符串,求得本次计算所需要的所有字段名:balance,begin_date,customer_id,department_id,job_num。
A13:定义一个空序列,准备存放切片(过滤条件)表达式序列。
A14:A7.slice 增加一个 bool 字段后循环计算,循环体是 B14 到 C22。其中:B14 到 C21 是对 slice 的 value 或者 interval 做性能优化的转换。
B14:如果 A14(当前 slice)的 dim 是 begin_date,并且 value 不为空,也就是 begin_date 等于指定日期的情况,例如:begin_date==date("2010-11-01")。此时 C14 计算出 date("2010-11-01") 的转换后的整数值,赋值给 A14 的 value。
B15:如果 A14 的 dim 是 begin_date,并且 value 为空,也就是 begin_date 在两个日期之间的情况,例如:begin_date 在 date("2002-01-01") 和 date("2020-12-31") 之间。此时 C15 计算出两个日期的转换后整数值,赋值给 A13 的 interval 的两个成员。
B16:如果 A14 的 dim 是 job_id,也就是 job_id 取枚举值的情况。例如:["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"].contain(job_id)。此时 C16 要将 A14 的 dim 改为 job_num。C17 要将 A14 的 value 枚举值转换为在全局变量 job 序列中的位置,也就是 job_num 整数序列,例如:[5,7,2,15,16]。
B18:如果 A14 的 dim 是 city,C18 生成一个长度为 city 维度个数的序列,C19 利用 A14 的 value(city 枚举值)将 C19 的相应成员赋值为 true,其他为 false。C19 就是布尔维序列,计算结果如下:
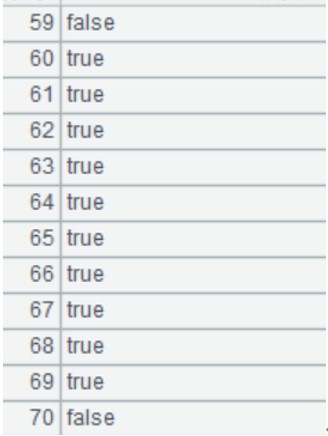
C20:将 C19 赋值给 A14 的 bool 字段。
B21:如果 A14 的 dim 是 flag1、flag2…flag8,也就是标志位等于 "1" 或者 "0" 的情况。此时 C21 要将 A14 的 value 值从字符串转化为整数。
B22:用 B14 到 C21 对 slice 的 bool、value 或者 interval 做性能优化的转换的结果作为参数,调用子程序 A1。
子程序 A1(B2 到 B6),和第二篇的 func 代码基本相同,只是增加了 B2、C2。B2 判断 bool 字段是否为空,如果不为空,那么 C2 就生成并返回布尔维度表达式。例如:[false,true,false…](city),作用是:用 city 字段的值作为序号,在布尔维序列中找对应位置的成员,如果是 true 就是符合枚举条件的记录,否则就是不符合枚举条件的记录。
C22:func A1 的返回结果追加到 A13 中。继续 A14 中的循环,到循环结束,就准备好了切片表达式的序列。
A23:从这里开始准备结果集显示值转换的表达式。将 A6.group 和 A6.aggregate.alias 序列合并,如下图:
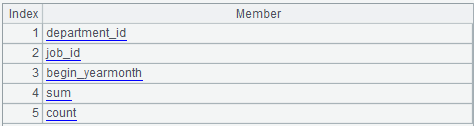
C23:将 A23 中的 job_id 替换成转换语句。语句的作用是:将结果集中的 job_num 转换为 job_id。
A24:将 A23 中的 begin_yearmonth,替换为转换语句,作用是:将分组字段中的整数值 begin_yearmonth 从整数转化为 yyyymm。
A25:将 A23 中的 begin_date,替换为转换语句,作用是:将分组字段中的整数化日期值转换为日期型。此时 A23 就是准备好的结果集显示值转换表达式:
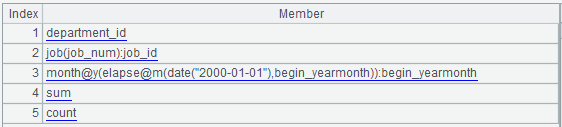
A26:返回 A12,A8,A10,A13.concat("&&"),A23.concat@c(),依次是:
本次计算用到的字段名:balance,begin_date,customer_id,department_id,job_num
聚合表达式:sum(balance):sum,count(customer_id):count
分组表达式:department_id,job_num,begin_date\100:begin_yearmonth
切片表达式:
[false,false,false,false,false,false,false,false,false,false,… false,false,true,true,true,true,
true,true,true,true,true,true,true,true,true,true,true,true,true,true,true,true,true](city)
结果集显示值转换表达式:
department_id,job(job_num):job_id,month@y(elapse@m(date("2000-01-01"),begin_yearmonth)):begin_yearmonth,sum,count
布尔维优化对 olap.splx 没有特殊的要求,代码如下:
A |
|
1 |
=call(arg_table/".splx",arg_json) |
2 |
=file("data/"/arg_table/".ctx").open() |
3 |
=A2.cursor@m(${A1(1)};${A1(4)};2) |
4 |
=A3.groups(${A1(3)};${A1(2)}) |
5 |
=A4.new(${A1(5)}) |
6 |
return A5 |
A3:实际执行的是布尔维优化之后的代码:
=A2.cursor@m(balance,begin_date,customer_id,department_id,job_num; [false,false,false,false,false,false,false,false,false,false,… false,false,true,true,true,true,
true,true,true,true,true,true,true,true,true,true,true,true,true,true,true,true,true](city);2)
作用是用 city 字段的值作为序号,在布尔维序列中找对应位置的成员,如果是 true 就是符合枚举条件的记录,否则就是不符合枚举条件的记录。
用来调用 SPL 代码的 Java 代码和上期相比没有变化,只要调整调用参数即可。
Java 代码加上后台计算返回结果总的执行时间如下:
计算方法 |
单线程 |
二线程并行 |
备注 |
无布尔维优化 |
11秒 |
6秒 |
|
布尔维优化 |
6 秒 |
4 秒 |
通过上表的对比可以看出,布尔维优化可以提高计算性能。
二、二值维度
SPL 代码由 olap.splx 和 customerFlag.splx 组成。前者是调用的入口,传入参数是 arg_table、arg_json,后者用来解析 arg_json。
arg_table 的值为 customerFlag。
arg_json 的值为:
{
aggregate:
[
{func:"sum",field:"balance",alias:"sum"},
{func:"count",field:"customer_id",alias:"count"}
],
group:
["department_id","job_id","begin_yearmonth"],
slice:
[
{dim:"flag1",value:"1"},
{dim:"flag2",value:"1"},
{dim:"flag3",value:"1"},
{dim:"flag5",value:"1"},
{dim:"flag6",value:"1"},
{dim:"flag8",value:"1"}
]
}
customerFlag.splx 代码如下:
A |
B |
C |
|
1 |
func |
||
2 |
if A1.bool!=null |
return string(A1.bool)/"("/A1.dim/")" |
|
3 |
else if A1.value==null |
return "between("/A1.dim/","/A1.interval(1)/":"/A1.interval(2)/")" |
|
4 |
else if ifa(A1.value) |
return string(A1.value)/".contain("/A1.dim/")" |
|
5 |
else if ifstring(A1.value) |
return A1.dim/"==\""/A1.value/"\"" |
|
6 |
else |
return A1.dim/"=="/A1.value |
|
7 |
=json(arg_json) |
=date("2000-01-01") |
|
8 |
=A7.aggregate.(~.func/"("/~.field/"):"/~.alias).concat@c() |
||
9 |
=A7.group.(if(~=="job_id","job_num",~)) |
||
10 |
=A9.(if(~=="begin_yearmonth","begin_date\\100:begin_yearmonth",~)).concat@c() |
||
11 |
=A7.aggregate.(field) |
=A9.(if(~=="begin_yearmonth","begin_date",~)) |
|
12 |
=(A11|C11).id().concat@c() |
||
13 |
=A7.slice.select(like(dim,"flag?")) |
=A13.derive(int(right(dim,1)):num) |
=to(8).("0") |
14 |
=B13.(C13(num)=value) |
=bits(C13.rvs()) |
="and(flag,"/B14/")=="/B14 |
15 |
=[] |
=A7.slice\A13 |
|
16 |
for B15 |
if A16.dim=="begin_date" && A16.value!=null |
>A16.value=int(interval@m(C7,eval(A16.value))*100+day(eval(A16.value))) |
17 |
else if A16.dim=="begin_date" && A16.value==null |
=A16.interval.(~=int(interval@m(C7,eval(~))*100+day(eval(~)))) |
|
18 |
else if A16.dim=="job_id" |
>A16.dim="job_num" |
|
19 |
=A16.value.(job.pos@b(~)) |
||
20 |
=[func(A1,A16)] |
>A15|=B20 |
|
21 |
=A7.group|A7.aggregate.(alias) |
=A21(A21.pos("job_id"))="job(job_num):job_id" |
|
22 |
=A21(A21.pos("begin_yearmonth"))="month@y(elapse@m(date(\""/C7/"\"),begin_yearmonth)):begin_yearmonth" |
||
23 |
=A21(A21.pos("begin_date"))="elapse@m(B4,begin_date\\100)+(begin_date%100-1):begin_date" |
||
24 |
return A12,A8,A10,(A15|C14).concat("&&"),A21.concat@c() |
||
A1 到 A12 与 customerEnum.splx 相比没有变化。
A13:将切片过滤条件 A7.slice 中 flag 开头的 dim 过滤出来,如下图:
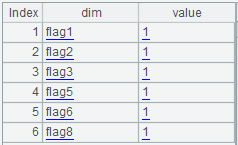
B13:A13 增加一列 num,取 dim 的最后一个数字,转为整数:
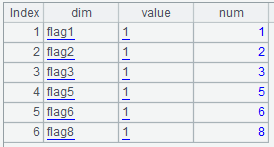
C13:创建一个长度为 8 的序列,每一个成员都是字符串 "0"。
A14:对 B13 循环计算,将 C13 对应位置设置成 value 的值 "1":
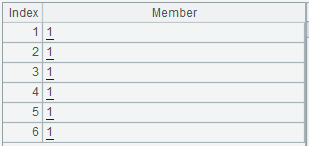
B14:将 C13 成员顺序反转,再用 bits 函数计算对应的整数值:237,写成二进制数就是:1011 0111。从右向左对应原有的 flag1-flag8 的值。
C14:用 B14 做字符串拼接,生成按位与计算的表达式:and(flag,237)==237。后续将作为过滤表达式的一部分。
A15:定义一个空序列,准备存放切片(过滤条件)表达式序列。
B15:A7.slice 中去掉 A13,得到 flag1-flag8 之外的切片条件。
A16:对 B15 开始循环,循环中处理 flag1-flag8 之外的切片条件。
A16-A23:代码和 customerEnum.splx 没有差别。
A24:返回 A12,A8,A10,A13.concat("&&"),A23.concat@c(),依次是:
本次计算用到的字段名:balance,begin_date,customer_id,department_id,job_num
聚合表达式:sum(balance):sum,count(customer_id):count
分组表达式:department_id,job_num,begin_date\100:begin_yearmonth
切片表达式:and(flag,237)==237
结果集显示值转换表达式:
department_id,job(job_num):job_id,month@y(elapse@m(date("2000-01-01"),begin_yearmonth)):begin_yearmonth,sum,count
二值维优化对 olap.splx 也没有特殊的要求,代码如下:
A |
|
1 |
=call(arg_table/".splx",arg_json) |
2 |
=file("data/"/arg_table/".ctx").open() |
3 |
=A2.cursor@m(${A1(1)};${A1(4)};2) |
4 |
=A3.groups(${A1(3)};${A1(2)}) |
5 |
=A4.new(${A1(5)}) |
6 |
return A5 |
A3:实际执行的是二值维优化之后的代码:
=A2.cursor@m(balance,begin_date,customer_id,department_id,job_num;and(flag,237)==237;2) 作用是用 flag 字段的值与 237 按位与,如果结果是 237 就是符合枚举条件的记录,否则就是不符合二值维条件的记录。
用来调用 SPL 代码的 Java 代码和上期相比没有变化,只要调整调用参数即可。
Java 代码加上后台计算返回结果总的执行时间如下:
计算方法 |
单线程 |
二线程并行 |
备注 |
无二值维优化 |
16秒 |
9秒 |
|
二值维优化 |
7 秒 |
4 秒 |
通过上表的对比可以看出,二值维优化也可以提高计算性能。


英文版