


多维分析后台实践 5:小事实表关联小维表
【摘要】
用实例、分步骤,详细讲解多维分析(OLAP)的实现。点击了解多维分析后台实践 5:小事实表关联小维表
实践目标
本期目标是在前面几期基础上,将客户宽表中最近一天的新客户数据与分支机构等多个维表关联,并通过维表字段进行切片和分组计算。
实践的步骤:
1、 准备分支机构等维表:将分支机构表等数据从数据库中取出,存成集文件。
2、 关联宽表新客户数据和维表,并计算切片和分组:用 Java 代码调用 SPL 实现。
各个维表和客户表的关联关系如下图:
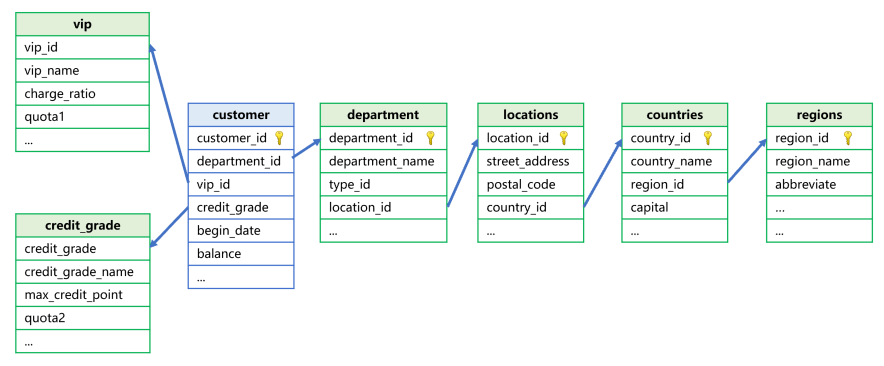
维表包括:
1、 分支机构表 department
从 Oracle 数据库中取出维表数据的 SQL 语句是 select * from department。执行结果如下图:

其中字段包括:
DEPARTMENT_ID NUMBER(4,0) 分支机构编号
DEPARTMENT_NAME VARCHAR2(32) 分支结构名称
MANAGER_ID NUMBER(6,0) 经理编号
LOCATION_ID NUMBER(4,0) 地址编号
TYPE_ID NUMBER(6,0) 类型编号
APPLAUSE_RATE NUMBER(3,0) 好评率
OPENING_DATE DATE 开业日期
STAR NUMBER(1,0) 星级
ENTERPRISE_TYPE_ID NUMBER(6,0) 企业资质
MAIN_BUSINESS NUMBER(6,0) 主营业务
2、 地址表 locations
字段包括:
LOCATION_ID NUMBER(4,0) 地址编号
STREET_ADDRESS VARCHAR2(40) 街道地址
POSTAL_CODE VARCHAR2(12) 邮政编码
CITY VARCHAR2(30) 城市
STATE_PROVINCE VARCHAR2(25) 州或者省
COUNTRY_ID CHAR(2) 国家编号
3、 国家表 countries
COUNTRY_ID CHAR(2) 国家编号
COUNTRY_NAME VARCHAR2(40) 国家名称
REGION_ID NUMBER 区域编号
CAPITAL VARCHAR2(40) 首都
4、 区域表 regions
REGION_ID NUMBER 区域编号
REGION_ID_NAME VARCHAR2(40) 区域名称
abbreviate VARCHAR2(10) 名称缩写
5、 贵宾表 vip
VIP_ID NUMBER(4,0)VIP 级别
VIP_NAME VARCHAR2(30) VIP 级别名称
MAX_POINT NUMBER(6,0) 最高积分
MIN_POINT NUMBER(6,0) 最低积分
CHARGE_RATIO NUMBER(4,0) 服务费比例(3-10)
INTEREST_RATE1 NUMBER(4,0) 取现手续费率(8-15)
QUOTA1 NUMBER(8,0) 快速取现额度(1000-8000)
QUOTA2 NUMBER(8,0) 免费还款额度(10000-160000)
NUMBER1 NUMBER(2,0) 月快捷登机次数(0-3)
NUMBER2 NUMBER(2,0) 月高铁贵宾厅次数(0-3)
6、 信用评级表 credit_grade
CREDIT_GRADE NUMBER(4,0) 信用评级
CREDIT_GRADE_NAME VARCHAR2(30) 信用评级名称
MAX_CREDIT_POINT NUMBER(6,0) 信用评分最高值
MIN_CREDIT_POINT NUMBER(6,0) 信用评分最低值
QUOTA1 NUMBER(8,0) 支付额度(10000-90000)
QUOTA2 NUMBER(8,0) 取现额度(10000-90000)
QUOTA3 NUMBER(8,0) 免密支付额度(1000-9000)
多维分析计算的目标可以用下面 Oracle 的 SQL 语句表示:
select v.interest_rate1,ct.country_id,c.job_id,sum(c.balance) sum,count(c.customer_id) count
from customer c
left join department d on c.department_id=d.department_id
left join locations l on d.location_id=l.location_id
left join countries ct on l.country_id=ct.country_id
left join regions r on r.region_id=ct.region_id
left join vip v on c.vip_id=v.vip_id
left join credit_grade cg on c.credit_grade=cg.credit_grade
where d.applause_rate between 5 and 95
and r.region_name in ('Asia','Europe','Americas')
and v.charge_ratio between 9 and 11
and cg.quota2 between 50000 and 80000
and c.job_id in ('AD_VP','FI_MGR','AC_MGR','SA_MAN','SA_REP')
and c.flag1='1' and c.flag8='1'
group by v.interest_rate1,ct.country_id,c.job_id
准备维表
续写 etl.splx,分别从数据库中取出分支机构表等维表生成集文件。代码示例如下:
A |
B |
C |
|
1 |
=connect@l("oracle") |
||
2 |
=A1.query@d("select * from department order by department_id") |
=A2.new(int(department_id):department_id,department_name,int(manager_id):manager_id,int(location_id):location_id,int(type_id):type_id,int(applause_rate):applause_rate,opening_date,int(star):star,int(enterprise_type_id):enterprise_type_id,int(main_business):main_business) |
=file("data/department.btx").export@z(B2) |
3 |
=A1.query@d("select * from vip order by vip_id") |
=A3.new(int(vip_id):vip_id,vip_name,int(max_point):max_point,int(min_point):min_point,int(charge_ratio):charge_ratio,int(interest_rate1):interest_rate1,int(quota1):quota1,int(quota2):quota2,int(number1):number1,int(number2):number2) |
=file("data/vip.btx").export@z(B3) |
4 |
=A1.query@d("select * from credit_grade order by credit_grade") |
=A4.new(int(credit_grade):credit_grade,credit_grade_name,int(max_credit_point):max_credit_point,int(min_credit_point):min_credit_point,int(quota1):quota1,int(quota2):quota2,int(quota3):quota3) |
=file("data/credit_grade.btx").export@z(B4) |
5 |
=A1.query@d("select * from locations") |
=A5.new(int(location_id):location_id,street_address,postal_code,city,state_province,country_id) |
=file("data/locations.btx").export@z(B5) |
6 |
=A1.query@d("select * from countries") |
=A6.new(country_id,country_name,int(region_id):region_id) |
=file("data/countries.btx").export@z(B6) |
7 |
=A1.query@d("select * from regions") |
=A7.new(int(region_id):region_id,region_name) |
=file("data/regions.btx").export@z(B7) |
A1:连接预先配置好的数据库 oracle。@l 选项是将字段名处理成小写,l 是字母 L 的小写,不是数字 1。
A2:取出 department 表的数据。department 是维表,实际应用中一般都比较小,可以全部装入内存。
B2:尽可能的将字段小整数化,减小内存占用。
C2:转化后的数据存入集文件。
A3-C3,读取、处理、存储 vip 表数据。
A4-C4,读取、处理、存储 credit_grade 表数据。
A5-C5,读取、处理、存储 locations 表数据。
A6-C6,读取、处理、存储 countries 表数据。
A7-C7,读取、处理、存储 regions 表数据。
数据预处理
一天的新客户数据并不是很多,能够全部装入内存。我们可以续写 init.splx,在内存中加载新客户和各个维表数据,网格参数是 today(当天日期)。
代码如下:
A |
B |
|
1 |
=file("data/job.btx").import@ib() |
>env(job,A1) |
2 |
=file("data/department.btx").import@b().keys(department_id) |
=file("data/vip.btx").import@b().keys(vip_id) |
3 |
=file("data/credit_grade.btx").import@b().keys(credit_grade) |
=file("data/locations.btx").import@b().keys(location_id) |
4 |
=file("data/countries.btx").import@b().keys(country_id) |
=file("data/regions.btx").import@b().keys(region_id) |
5 |
=A2.switch(location_id,B3.switch(country_id,A4.switch(region_id,B4))) |
|
6 |
=file("data/customer_begin_date.ctx").open().cursor(department_id,job_num,employee_id,customer_id,first_name,last_name,phone_number,job_title,balance,department_name,flag1,flag2,flag3,flag4,flag5,flag6,flag7,flag8,vip_id,credit_grade;begin_date==if(ifdate(today),today,now())).fetch() |
|
7 |
=A6.join(department_id,A2,~:department_detail;vip_id,B2,~:vip_detail;credit_grade,A3,~:credit_grade_detail) |
|
8 |
>env(newCustomer,A7) |
|
A1:取出集文件中的职业类型数据,@i 表示只有一列时读成序列。
B1:存入全局变量 job。
A2-B4:分别取出集文件中的分支机构、vip、信用评级、地址、国家、区域数据,建立主键。
A5:把 department、locations、contries 和 regions 表按照层次关联起来。
A6:从 customer_begin_date.ctx 组表中取出当天的新客户数据,不取出 begin_date 字段。如果 today 不是日期型参数(或者为空),就用当前日期代替。
A7:将新客户数据 department_id 字段复制为 department_detail,并关联全局变量 department。对 vip 和 credite_grade 同样处理。
A8:将关联好的新客户数据存入全局变量 newCustomer。
写好的 init.splx 要放入节点机主目录,启动或重启节点机时会被自动调用。
init.splx 还需要在每天新增客户表数据时执行,用来更新 newCustomer。方法是续写 etlAppend.splx。再用 ETL 工具或者操作系统定时任务,通过命令行调用这个 etlAppend.splx。
例如:
C:\Program Files\raqsoft\esProc\bin>esprocx etlAppend.splx
etlAppend.splx 网格参数和代码如下:
A |
|
1 |
=connect@l("oracle") |
2 |
=A1.cursor("select * from customer where begin_date=?",today) |
3 |
=file("data/customer_begin_date.ctx").open().append(A2) |
4 |
>A3.close(),A1.close() |
5 |
>callx("init.splx",today;["localhost:8281"]) |
A1-A4 不变。
A5:调用节点机上的 init.splx,网格参数是 today。
关联计算
由于内外存计算写法不同,所以不能直接使用前面几期的 olap.splx,要另外写一个 olapMem.splx。
输入参数也是两个:表名 arg_table 值为 newCustomer,其他参数采用 json 格式,arg_json 样例如下:
{
aggregate:
[
{
func:"sum",
field:"balance",
alias:"sum"
},
{
func:"count",
field:"customer_id",
alias:"count"
}
],
group:
[
"vip_detail.interest_rate1:vip_detail_interest_rate1",
"department_detail.location_id.country_id.country_id:department_detail_location_id_country_id",
"job_id"
],
slice:
[
{
dim:"department_detail.applause_rate",
interval:[10,95]
},
{
dim:"department_detail.location_id.country_id.region_id.region_name",
value:["Asia","Europe","Americas"]
},
{
dim:"vip_detail.charge_ratio",
interval:[9,11]
},
{
dim:"credit_grade_detail.quota2",
interval:[50000,80000]
},
{
dim:"job_id",
value:["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"]
},
{
dim:"flag1",
value:"1"
},
{
dim:"flag8",
value:"1"
}
]
}
其中,group 和 slice 中出现了 department_detail.location_id 和 department_detail.applause_rate 等,是因为前面数据预处理采用了外键属性化,所以可以直接用 department_detail 来点取分支机构的不同属性。
department_detail.location_id.country_id.country_id:department_detail_location_id_country_id 中的冒号是给外键属性化字段取一个别名,用做最后结果的字段名。字段中之所以出现 country_id.country_id,是因为第一个 country_id 已经外键属性化了,也就是变成了一个引用,不能直接返回给前端。第二个是单值,就可以直接返回给前端了。
第一步:编写 newCustomer.splx。
在编写 olapMem.splx 之前,先将 customer.splx 改写为 newCustomer.splx 处理 arg_json 参数,SPL 代码如下:
A |
B |
C |
|
1 |
func |
||
2 |
if A1.value==null |
return "between("/A1.dim/","/A1.interval(1)/":"/A1.interval(2)/")" |
|
3 |
else if ifa(A1.value) |
return string(A1.value)/".contain("/A1.dim/")" |
|
4 |
else if ifstring(A1.value) |
return A1.dim/"==\""/A1.value/"\"" |
|
5 |
else |
return A1.dim/"=="/A1.value |
|
6 |
=json(arg_json) |
||
7 |
=A6.aggregate.(~.func/"("/~.field/"):"/~.alias).concat@c() |
||
8 |
=A6.group.(if(~=="job_id","job_num",~)).concat@c() |
||
9 |
=[] |
||
10 |
for A6.slice |
if A10.dim=="job_id" |
>A10.dim="job_num" |
11 |
>A10.value=A10.value.(job.pos@b(~)) |
||
12 |
else if like(A10.dim, "flag?") |
>A10.value=int(A10.value) |
|
13 |
=[func(A1,A10)] |
>A9|=B13 |
|
14 |
=A6.group.(~.split(":")).(~=~.m(-1))|A6.aggregate.(alias) |
=A14(A14.pos("job_id"))="job(job_num):job_id" |
|
15 |
return A7,A8,A9.concat("&&"),A14.concat@c() |
||
A1 到 C5 是子程序,在调用的时候才会执行。代码与 customer.splx 完全一致,没有改变。
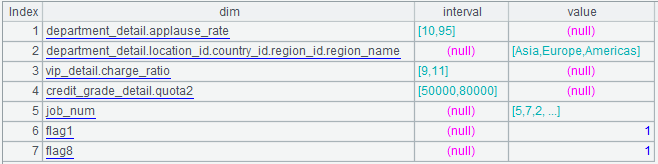
A6:将 arg_json 解析成序表。解析的结果是多层嵌套的序表,如下图:

其中的 aggregate 为:

其中的 group 为:

其中的 slice 为:
A7:先将 aggregate 计算成冒号相连的字符串序列,再将序列用逗号连接成一个字符串:sum(balance):sum,count(customer_id):count,也就是聚合表达式。
A8:将 group 中的 job_id 替换为 job_num。
A9:定义一个空序列,准备存放切片(过滤条件)表达式。
A10:循环计算 slice,循环体是 B10 到 C13。其中:B10 到 C12 是对 slice 的 value 或者 interval 做性能优化的转换。
B10:如果 A10 的 dim 是 job_id,也就是 job_id 取枚举值的情况。例如:["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"].contain(job_id)。此时 C10 要将 A10 的 dim 改为 job_num。C11 要将 A10 的 value 枚举值转换为在全局变量 job 序列中的位置,也就是 job_num 整数序列,例如:[5,7,2,15,16]。
B12:如果 A10 的 dim 是 flag1、flag2…flag8,也就是标志位等于 "1" 或者 "0" 的情况。此时 C12 要将 A10 的 value 值从字符串转化为整数。
B13:用 B10 到 C13 对 slice 的 value 或者 interval 做性能优化转换结果作为参数,调用子程序 A1。
子程序 A1(B2 到 B5),和第一篇 customer.splx 的 func 代码相同,不再赘述。
C13:func A1 的返回结果追加到 A9 中。继续 A10 中的循环,到循环结束,就准备好了切片表达式的序列。
A14:准备结果集显示值转换的表达式。将 A6.group.(~.split(":")).(~=~.m(-1)) 和 A6.aggregate.alias 序列合并,如下图:
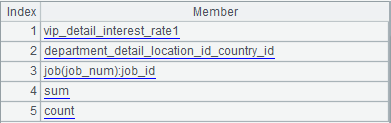
A6.group.(~.split(":")).(~=~.m(-1)) 是将 group 中有冒号的,取冒号后面的别名,否则直接用 group 的值。
C14:将 A19 中的 job_id 替换成转换语句。语句的作用是:将结果集中的 job_num 转换为 job_id。
A15:返回 A7,A8,A9.concat("&&"),A14.concat@c(),依次是:
聚合表达式:sum(balance):sum,count(customer_id):count
分组表达式:
vip_detail.interest_rate1:vip_detail_interest_rate1,
department_detail.location_id.country_id:department_detail_location_id_ country_id,
job_num
切片表达式:
between(department_detail.applause_rate ,10:95)
&&["Asia","Europe","Americas"].contain(department_detail.location_id.country_id.region_id.region_name)
&& between(vip_detail.charge_ratio,9:11)
&& between(credit_grade_detail.quota2,50000:80000)
&& [5,7,2,15,16].contain(job_num)
&& flag1==1 && flag8==1
结果集显示值转换表达式:
vip_detail_interest_rate1,department_detail_location_id_country_id,job(job_num):job_id,sum,count
第二步:编写 olapMem.splx。
网格参数是 arg_table(值为 newCustomer)和 arg_json。SPL 代码如下:
A |
|
1 |
=call(arg_table/".splx",arg_json) |
2 |
=${arg_table}.select(${A1(3)}) |
3 |
=A2.groups(${A1(2)};${A1(1)}).new(${A1(4)}) |
4 |
return A3 |
A1:根据 arg_table 参数的值调用 newCustomer.splx,调用参数是 arg_json,返回值是 newCustomer 返回的四个表达式字符串。
A2:根据 arg_table 参数,对全局变量 newCustomer 序表计算切片表达式完成数据过滤。实际执行的 SPL 语句是:newCustomer.select(between(department_detail.applause_rate ,10:95) && ["Asia","Europe","Americas"].contain(department_detail.location_id.country_id.region_id.region_name) && between(vip_detail.charge_ratio,9:11) && between(credit_grade_detail.quota2,50000:80000) && [5,7,2,15,16].contain(job_num) && flag1==1 && flag8==1)
A3:对 A2 做分组汇总,结果按照别名重新命名。实际执行的语句是:
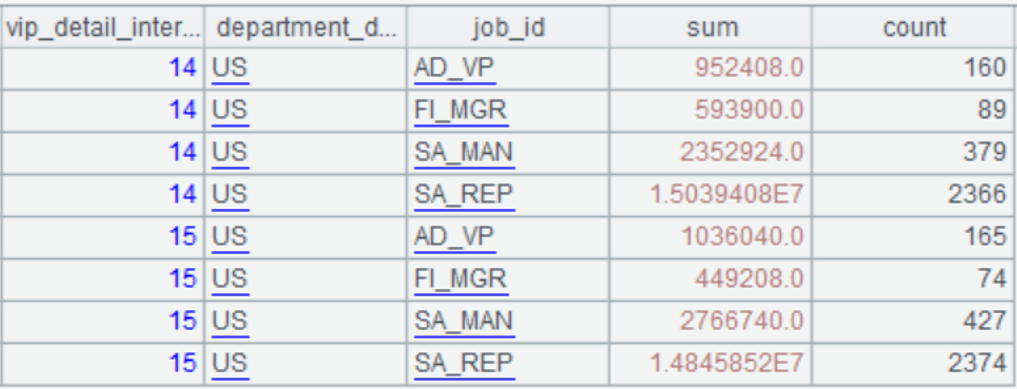
=A2.groups(vip_detail.interest_rate1:vip_detail_interest_rate1,department_detail.location_id.country_id.country_id:department_detail_location_id_country_id,job_num; sum(balance):sum,count(customer_id):count).new(vip_detail_interest_rate1,department_detail_location_id_country_id,job(job_num):job_id,sum,count)
执行结果如下图:
第三步:用 Java 代码调用
olapMem.splx 编写好之后,可以在多维分析中作为存储过程调用,Java 代码和前面几期大部分相同,只是 splx 文件名称、arg_table 和 arg_json 值不同。Java 代码如下:
public void testOlapServer(){
Connection con = null;
java.sql.PreparedStatement st;
try{
// 建立连接
Class.forName("com.esproc.jdbc.InternalDriver");
// 根据 url 获取连接
con= DriverManager.getConnection("jdbc:esproc:local://?onlyServer=true&sqlfirst=plus");
// 调用存储过程,其中 olap 是 splx 的文件名
st =con.prepareCall("call olapMem(?,?)");
st.setObject(1, "newCustomer");
st.setObject(2, "{aggregate:[{func:\"sum\",field:\"balance\",alias:\"sum\"},{func:\"count\",field:\"customer_id\",alias:\"count\"}],group:[\"vip_detail.interest_rate1:vip_detail_interest_rate1\",\"department_detail.location_id.country_id:department_detail_location_id_country_id\",\"job_id\"],slice:[{dim:\"department_detail.applause_rate\",interval:[10,95]},{dim:\"department_detail.location_id.country_id.region_id.region_name\",value:[\"Asia\",\"Europe\",\"Americas\"]},{dim:\"vip_detail.charge_ratio\",interval:[9,11]},{dim:\"credit_grade_detail.quota2\",interval:[50000,80000]},{dim:\"job_id\",value:[\"AD_VP\",\"FI_MGR\",\"AC_MGR\",\"SA_MAN\",\"SA_REP\"]},{dim:\"flag1\",value:\"1\"},{dim:\"flag8\",value:\"1\"}]}");//arg_json
// 执行存储过程
st.execute();
// 获取结果集
ResultSet rs = st.getResultSet();
// 继续处理结果集,将结果集展现出来
}
catch(Exception e){
out.println(e);
}
finally{
// 关闭连接
if (con!=null) {
try {con.close();}
catch(Exception e) {out.println(e); }
}
}
}
Java 代码和 SPL 执行的总时间是 0.3 秒。


英文版