


【性能优化】4.3 [遍历技术] 并行遍历
4.3 并行遍历
我们在第二章讲过外存数据集分段的方法,它不仅可以用于二分法查找,更重要的是可以用于分段并行。让多个 CPU 分担计算量,经常可能获得接近于线性增长的性能提升。
SPL 提供了很方便并行计算语法:
A |
B |
|
1 |
=file("orders.txt") |
|
2 |
fork to(4) |
=A1.cursor@t(area,amount;A2:4) |
3 |
return B2.groups(area;sum(amount):amount) |
|
4 |
=A2.conj().groups(area;sum(amount)) |
|
fork 语句将启动多个线程并行执行自己的代码块,线程的数量由 fork 后参数序列的长度决定,fork 同时会将这些参数依次分配给每个线程,代码块中引用 fork 所在格值即可得到。当所有线程执行完毕之后,每个线程的计算结果,也就是代码块中 return 的值,将被收集到 fork 所在格中,按线程的次序拼成一个序列。然后代码继续执行。
本例中, A2 会产生 4 个线程,每个线程分别得到 1、2、3、4 作为参数,在 B2 中可以生成相应的分段游标并进行分组汇总计算,4 个线程都结束后,每个线程的返回值(都是一个序表)会收集在 fork 格,也就是 A2 中,然后再把这些序表合并起来再做一次汇总就得到了针对原数据表的分组汇总结果。
除了分段数据表外,还可以使用多文件上的并行。比如订单放到了 12 个文件中,每个月放一个文件,我们来计算各地区金额在 50 以上的订单数量:
A |
B |
|
1 |
fork to(12) |
=file("orders"\A2\".txt") |
2 |
=B1.cursor@t(area,amount;A2:4) |
|
3 |
=B2.select(amount>=50) |
|
4 |
return B2.groups(area;count(1):quantity) |
|
5 |
=A1.conj().groups(area;sum(quantity)) |
|
这时会启动 12 个线程计算。注意,在线程中用 count 计数后,在线程外要用 sum 来合计,而不能再用 count。
SPL 简化了并行计算的机制,假定各线程都是同时启动,并且等待所有线程都结束才完成整个任务。这样无法用于处理系统级的复杂并行任务,但可以语法代码简单很多,对于大多数结构化数据计算已经够用了。
并行执行时,要先设置集算器选项中的并行数:
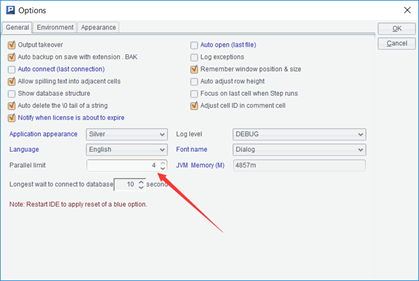
设置之后,SPL 将物理上最多会生成这个数量的线程。如果 fork 后的参数序列更长,则会强制串行执行。比如刚才的例子中,fork 的参数序列长度为 12,而这里设置的并行数是 4,SPL 实际上只会启动 4 个线程,依次将 fork 的前 4 个任务放进去线程中执行,有某个线程执行完出现空闲时,再把某个还未执行的任务填进去,依此规则反复,直到所有任务都执行完。这样,逻辑上看起来有 12 个线程,实际上只有 4 个线程。
在这种机制下,把任务拆碎一些会有好处。因为每个任务实际的执行时候不一定总是一样长,如果物理上每个线程只执行一个任务,执行快的线程结束之后就只能等待其它慢线程。如果任务拆碎了,快的线程可以多执行一些任务,总的等待量会更少,负载更为均衡,总体性能也会更好。坏处在于会增加更多的内存用于存储线程的返回结果,而且线程切换调度也有成本,所以并不是拆得越碎就越好,具体数值要看实际情况来确定。
通常,每个线程会对应由一个 CPU 执行,如果产生的线程数超过了 CPU 的数量,操作系统就会使用分时技术,在 CPU 上切换不同的线程,而这些机制都会消耗 CPU 和内存资源,导致总体性能反而会下降。所以,设置最大并行数时不宜超过 CPU 数量,通常要略少一点,因为某些 CPU 还需要负担操作系统事务等其它任务。
有些服务器的 CPU 很多,可能多达几十个,但我们有时会发现把并行数量设置更多,也不会获得更好的性能。这一方面是因为线程多了调度成本会上升,更可能的原因是硬盘并没有同样的并行能力。多个线程会共享同一套硬盘,涉及外存计算时都要从硬盘中读取数据,而硬盘总的吞吐能力是确定的,如果已经达到极限,那也没办法跑得更快,这时候就会发生 CPU 闲置等待硬盘的现象。特别是对于机械硬盘,并行读取时还会造成较严重的磁头跳动现象,导致硬盘性能严重下降,极有可能出现并行数量越多性能越差的结果。
服务器的 CPU 和硬盘配置要均衡以适应计算任务,有些服务器把 CPU 配得很多很强,又为了容量大而配置了低速的机械硬盘,结果常常发挥不了 CPU 的效能,造成浪费。如果把购买 CPU 的钱花到内存或高速固态硬盘上,很可能成本更低而得到更好的性能。


关于并行数的设置,如果叠加并发,是不是就无所谓超不超过 CPU 数量了?这方面基础不太好,请教并发多任务时 CPU 是否也会把所有核都用上?还是只会用到其中一个?如果是前者,看来就不用关心并行数设置不超过 CPU 数量了。
还有,注意到 SPL 似乎没有并发数的配置(只有并行数设置),那如何应对多并发内存不够用的情况呢?
并发时,CPU 当然会使用多个核。
并发和并行的目标不同。并行是一个任务,尽量快地完成,并行数超过 CPU 核数时反而会更慢。而并发是多个任务,通常目标是希望每个任务的延时体检都不要太差,并行数超过 CPU 核数时时,可能导致所有任务完成的总时间更慢,但单任务的体验会略好,这时候设置更大的并行数是有意义的。
SPL 是被调用的,并发多少任务是在主程序控制的(比如 WebServer 后的应用),SPL 这个环节不再控制了。这时候需要应用开发者来管理控制,通常 WebServer 也都可以控制同时在线 session 数。
SPL 作为服务器(集算服务器)运算 时是可以控制并发数量的,但 IDE 和嵌入的 JDBC 都不可以,也没必要。
内存不够的问题很复杂,可以控制同时在线数,但也未必够。要做得细致,要在代码中再判断是不是出错了。进一步,还可以使用容器或虚拟机来限定资源。