


【性能优化】3.9 [外存查找] 全文检索
3.9 全文检索
在结构化数据查询时常常会查找某字符串字段是否含有某确定子串的记录。如果是形如 like(X,“abc*”) 的条件,即子串会位于待查找字段的前部,则可以利用该字段的索引来快速定位。因为满足条件 like(X,“abc*”) 的记录在 X 的排序索引中一定是连接存储的,用子串 abc 就可以迅速定位到第一条(也可能一条都不存在,也能迅速判断出来),然后继续遍历直到原条件不再满足为止。SPL 中实现了这个机制,发现这种条件时就会检查 X 是否有排序索引并加以利用。
如果子串位于待查找字段的中间,即形如 like(X,“abc”) 的条件,就没法再利用前面讲过的各种索引了,而且需要建立针对文字的索引。
面向搜索的全文检索当然能够解决这个问题,但其索引过于庞大(因为也是面向更为庞大的数据量),而且还可能涉及到很专业的自然语言理解和分词技术,不太适合在结构化数据计算任务中引入。
结构化数据的规模本来也远小于搜索面临的网页,查找范围一般也会限定在某个字段内,这样涉及数据量会更小一点。而且作为字段内容的字符串通常也就是几个字符到一句文字,很少会像网页那样是一整篇文章,这种时候可以采用简单一点的技术。
把字段(字符串类型)的字符拆开出来,取出其中所有出现过的两个(或三个)字符的组合情况,比如从串 abcd 可以取出 ab,bc,cd 这三种组合。然后对这些提取出来的组合建立排序索引,被查找键值就是这些字符组合,对应出现过该字符组合的字段所在的记录。
用这种办法建出来的索引不会很大。常用字符大概有几千个(汉字和英文字符),如果只取两个字符,这种组合数最多也就是几千乘几千个,大概百万到千万级,并不是很大。如果是取到三个字符,大概会几十亿到百亿规模,现代好一点的服务器也都能支撑住。
我们再来看如何查找,以两个字符组合为例,延用上一节的符号。
很容易证明 S(like(X,“abc”))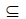 (like(X,“ab”))
(like(X,“ab”))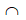 (like(X,“bc”)),而利用这种索引,我们很容易找到 S(like(X,“ab”)) 和 S(like(X,“bc”)),再使用上一节的索引归并技术就可以找出 S(like(X,“ab”))
(like(X,“bc”)),而利用这种索引,我们很容易找到 S(like(X,“ab”)) 和 S(like(X,“bc”)),再使用上一节的索引归并技术就可以找出 S(like(X,“ab”))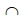 (like(X,“bc”)),然后还要在这个集合中进一步检查条件 like(X,“abc”) 是否成立才能找出最终的目标值(只能证明目标值包含于这个集合,并不一定相等)。但无论如何,这已经能让计算量比硬遍历少了非常多,而并不需要高成本的全文检索技术。
(like(X,“bc”)),然后还要在这个集合中进一步检查条件 like(X,“abc”) 是否成立才能找出最终的目标值(只能证明目标值包含于这个集合,并不一定相等)。但无论如何,这已经能让计算量比硬遍历少了非常多,而并不需要高成本的全文检索技术。
SPL 中实现这种简化的全文索引:
| A | |
| 1 | =file("data.ctx").open() |
| 2 | =file("data.idx") |
| 3 | =A1.index@w(A2;X) |
| 4 | =A1.icursor(;like(X,"*abc*");A2) |
使用 index@w 即会建立这种索引,目前使用的是两字符方案,在很多场景也够用。在查找时就直接使用 like 作为条件即可。

