


【程序设计】8.2 [表一表] 序表与排列
8.2 序表与排列
有了结构化数据的基本概念后,我们来学习如何处理这种数据,也就是在前言中说的本书的后半部分内容。
用于处理结构化数据的程序语言中,当前应用最广的是 SQL。SQL 全称是 Structured Query Language,本意就是专门用于结构化数据查询的语言,是关系数据库的通行语言。
除了 SQL 相关的资料外,大多数程序设计书籍并不会讲到结构化数据,讲完相当于本书前半部分的内容后,就开始转向更高级的面向对象等内容,对于非专业人员来讲,这本书可以说已经结束了。但是,学到这个程度,除了会做一些中小学的数学题(就如同前面举过的例子)来练练脑筋外,对日常工作并不会有什么实质性的帮助。只有学习了结构化数据的知识和技能之后,才可能真正用编程来提高工作效率,这也是本书的重要目标。
不过,本书不打算讲 SQL。这方面资料很多,有兴趣可以自己去学。SQL 通常只能使用于数据库中,而安装和管理数据库的技能要求有点高,不适合本书设计的读者人群。
我们继续使用 SPL。和 SQL 相比,SPL 有丰富得多的结构化数据处理能力,大多数情况的代码都要比 SQL 更为简洁,而且使用环境也不依赖于数据库,更适合非专业人员。
事实上,SPL 全称是 Structured Process Language,也是为对付结构化数据而发明的。结构化数据实在是太常见了,日常工作中绝大多数数据处理任务都是和结构化数据相关的,有必要发明更高效的程序语言。
其实,在集算器中允许针对文件数据使用 SQL。基本的 SQL 功能被作为 SPL 的一种特殊语句而实现了,用集算器也可以学习 SQL 而不必安装数据库。
言归正传,我们先来看如何创建一个数据表。
A |
|
1 |
=create(name,sex,weight,height) |
create 函数创建空的数据表,数据表必须要有数据结构,也就是字段名,依次填入 create 函数的参数即可。刚创建出来的数据表没有记录,查看数据时会看到右边只有个表头。

我们把代码写完整一些,加一些数据进来。
A |
B |
C |
D |
|
1 |
Zhang San |
Male |
80 |
1.75 |
2 |
Li Si |
Male |
60 |
1.68 |
3 |
Wang Hua |
Female |
51 |
1.64 |
4 |
Zhao Ting |
Female |
49 |
1.6 |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
在 A5 创建数据表,然后在 C5 中用 record 函数将数据填入,其中 [A1:D4] 的写法我们在前面讲过。record 函数的作用就是把作为参数的序列的成员依次填入数据表中作为字段取值,序列成员将按数据结构中的字段次序依次填入,填完一条记录如果还有剩余序列成员,则会为数据表创建一条新记录用于继续填入剩下的序列成员。
现在再查看数据(record 函数仍然返回那个数据表,看 A5 和 C5 是一样的)。
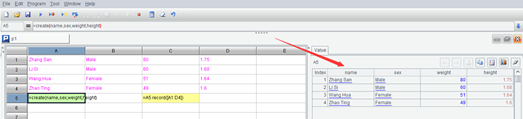
这个看起来和序列值很象,只不过序列显示出来是一列,而数据表显示成多列,并且每个列还多了一个名字(字段名),集算器也都会在左边自动显示一个 Index 列方便计数,似乎就是个更复杂的序列?
确实是这样,我们现在可以先把 SPL 中的数据表理解成以记录为成员的序列(等下会讲还是有点不同)。事实上,SPL 中对数据表的正式名称就是叫序表,原因是 SPL 会非常强调表中记录之间的次序。对于用惯了 Excel 的人来讲,记录(也就是行)有次序是天经地义的;但对于数据库程序员来讲,数据表中的记录是没有次序的。SPL 要强调次序以示和 SQL 区分。
数据表称为序表,不过记录还是记录,字段也是字段。
既然序表是记录构成的序列,那么是不是可以用序列引用成员的方法得到记录呢?
是可以的,我们接着刚才的代码继续写
A |
B |
C |
D |
|
… |
… |
… |
… |
… |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
6 |
=A5(1) |
=A5(3) |
=A5.m(-1) |
=A5.len() |
执行后再看 A6 的值:

还是显示成了一个有标题的表格,但只有一条数据,而且没有了左边的 Index 列。
这就是记录,它有数据结构(即所在序表的数据结构),也就是字段。它的每个字段有个取值,都列在上面了。
A5 确实像个序列,它可以正确执行 A5.m(-1) 这样的代码,A5.len() 也没问题。
我们再来研究记录,能不能取出记录的字段值参与运算呢?继续写:
A |
B |
C |
D |
|
… |
… |
|||
6 |
=A5(1) |
=A5(3) |
=A5.m(-1) |
|
7 |
=A6.weight/A6.height*A6.height |
|||
8 |
>output(if(B6.height>C6.height,B6.name,C6.name) + "is taller") |
|||
使用. 操作符后面加字段名就可以取出字段值了。A7 中计算了第 1 个人 Zhang San 的 BMI 指数,A8 中比较了第 3 个人和第 4 个人的身高,并显示出高者的名字。
能不能再改变字段值呢?也可以。
A |
B |
C |
D |
|
… |
… |
|||
6 |
=A5(1) |
=A5(3) |
=A5.m(-1) |
|
7 |
=A6.weight/A6.height*A6.height |
|||
8 |
>output(if(B6.height>C6.height,B6.name,C6.name) + "is taller") |
|||
9 |
=C6.height=1.8 |
=A5(4).name="NewZhaoTing" |
||
10 |
>output(if(B6.height>C6.height,B6.name,C6.name) + "is taller") |
|||
使用取出来的记录变量(C6)和直接用序表成员(A5(4))都可以引用和修改字段值。
对于记录 r 的字段 F,r.F 就相当于一个命名稍微复杂的变量,可以随意地在表达式中引用,也可以被赋值。
我们看到,在 SPL 中我们可以把记录从序表中取出来单独查看和运算。不要觉得这是理所当然的,这在 SQL 中是不可以的,SQL 的记录不能游离在数据表外独立运算。
回顾我们以前讲过的对象概念。复杂的数据类型不会直接存储在变量中,而是只存储了一个地址。一条记录有多个字段,看起来也有点复杂,那么它是不是也是这样呢?
A |
B |
C |
D |
|
… |
… |
|||
6 |
=A5(1) |
=A6 |
=A5(1) |
|
7 |
>A6.name="Test" |
=B6.name |
=C6.name |
|
做做实验就知道了,记录确实也是对象。不仅记录变量中只存储了记录的地址,在序表中也是存储的地址而没有复制记录值。修改记录的字段值,会导致之后所有引用这条记录字段的代码都受到影响。
至于序表,那显然更是个对象了。
而且,记录还有更特殊的地方:
A |
B |
C |
D |
|
1 |
Zhang San |
Male |
80 |
1.75 |
2 |
Li Si |
Male |
60 |
1.68 |
3 |
Wang Hua |
Female |
51 |
1.64 |
4 |
Li Si |
Male |
60 |
1.68 |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
6 |
=A5(1)>A5(2) |
=A5(2)==A5(4) |
=A5(2)>A5(4) |
|
我们故意把第 4 行和第 2 行的数据填成完全一样,然后观察第 6 行的三个逻辑表达式的计算结果。
A6 和 C6 的结果不可预测,多次执行可能得到不同的结果。B6 则永远是 false。
这是怎么回事?
记录的字段并不像序列的成员那样常常是同一类的东西,把字段的次序用于比较大小通常是没有业务意义的,比如这里 name 字段在 sex 之前,但 name 在比较时要优先于 sex 则没什么道理可言。但是,返回一个错误也没必要,于是 SPL 就规定记录比较时使用了内部的地址值,所以 A6 和 C6 会得到不可捉摸的结果,而同一序表内的两条记录,即使内容完全一样,也会分别分配空间存储,其地址值也是不同的,所以两条不同的记录永远不相等。
那么,如果我们就是想比较两条记录的字段值是不是对应相等,或者我们就是希望按照字段次序来比较出记录的大小,又该怎么办?
SPL 提供了专门的函数来做这样的比较:
A |
B |
C |
D |
|
1 |
Zhang San |
Male |
80 |
1.75 |
2 |
Li Si |
Male |
60 |
1.68 |
3 |
Wang Hua |
Female |
51 |
1.64 |
4 |
Li Si |
Male |
60 |
1.68 |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
6 |
=cmp(A5(1),A5(2)) |
=cmp(A5(2),A5(4)) |
||
现在就会得到确定的结果了。所不同的是,cmp 函数返回的不是 true 和 false,而是一个整数,相等则返回 0,前者小返回 -1,前者大返回 +1,一次比较中要分出三种情况。
为什么 SPL 不把记录的比较直接约定成 cmp 函数的计算结果呢?
按 cmp 函数的规则来比较记录的大小,并不是常见运算,稍麻烦一点不要紧。而比较记录变量中存储的地址是不是相同(以确定是否在物理上就是同一条记录)却是相对常见的运算,还经常会隐含地执行(比如后面要讲到的分组运算)。如果把记录比较都被约定成 cmp 运算结果,比较地址的动作就会麻烦很多或者效率低很多。所以,SPL 约定成现在的规则,是权衡运算效率和代码麻烦度之后的结果。
序表就像记录构成的序列,那么是不是能像序列一样使用 insert 和 delete 函数增加删除成员呢?
delete 没问题,但 insert 就不同了,这就是序列和序表的重点差异。
我们说过,一个数据表只有一套数据结构,在序表中增加记录时必须是同样数据结构的记录,如果允许随便抓一条记录插入到序表中,那就要做详细的检查才能避免这种情况。而且,这可能导致一条记录从属于两个不同的序表,当其中某个序表出于某种原因调整数据结构时,又可能导致另一个序表中记录的数据结构不一致的现象。这太麻烦了,严重影响程序效率。
所以,SPL 规定,记录必须从属于某个序表产生,而且也不可以插入到别的序表中。这样,某序表的记录全部在该序表掌控之中,不会有跑到别的序表中的记录,也不会从别外拿一条记录过来。于是,我们会发现,SPL 提供了函数创来建序表,但却没有函数来创建单独的记录。记录创建出来后可以游离于序表之外参与其它运算,但创建时必须依附于一个序表。创建的单独记录,本质上是一个只有一条记录的序表中的记录,这个序表还能继续插入新记录。
这也可以解释上面说过的:不同的记录永远不会相等。
序表的 insert 函就被做成了这样:
A |
B |
C |
D |
|
… |
… |
… |
… |
… |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
6 |
>A5.insert(0,"Mary","Female",55,1.7) |
|||
7 |
>A5.insert(2,"John","Male",75,1.8) |
|||
insert 的第 1 个位置参数,意思和序列的 insert 是一样的,可以在中间插入,也可以在最后追加。然后要在剩余的参数中写上要插入记录的每个字段值,SPL 会在这个序表的合适位置创建一条新记录,把字段值填入。
把成员拼成一个序列,也就是集合,是为了方便一起运算处理,比如可以使用前面讲过的循环函数。如果序表的记录必须存在于序表内,那么还能把不同序表的记录拼起来一起运算吗?而且,就算是同一个序表,可能某次参与运算的也不是全部,序列也有取出子序列的方法,这对于序表还有效吗?
这些操作,在 SPL 中都是允许的。记录只是在创建时依附于序表以保证其数据结构的一致性,一旦创建出来之后,就和普通数据一样,可以随意引用和组合了。
由一批不同序表的记录构成的序列,或者一个序表的部分记录构成的序列,都是很常见的情况。这种序列在 SPL 中有个专门的名字叫做排列。注意这不是中学数学课中的排列组合中的排列了(在汉语中是同一个词,英语能区分)。
排列当然也是个对象。
针对序表和排列的循环函数,我们后面再讲,现在先手工制造几个排列出来:
A |
B |
C |
D |
|
… |
… |
… |
… |
… |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
6 |
=A5.to(2,) |
=[A6(1),A5(4),A5.m(-1)] |
=A5.step(2,2) |
|
7 |
=A6.len() |
=B6(2)==B6(3) |
=C6(1)==A6(1) |
|
目前手头还只有一个序表,只能造出由这个序表的记录构成的排列。注意 B6,排列的成员可以引自其它排列,不一定直接从序表来。而且,其成员是可以重复的,B7 将算出 true;序表的成员因为每次都是新造的,互相不可能相等;不同排列当然可以由相同的记录构成,C7 也会计算出 true。
排列可以理解为常规的序列,因为可能有相同的成员,集合运算也有意义:
A |
B |
C |
D |
|
… |
… |
… |
… |
… |
5 |
=create(name,sex,weight,height) |
=A5.record([A1:D4]) |
||
6 |
=A5.to(2,) |
=[A6(1),A5(4),A5.m(-1)] |
=A5.step(2,2) |
|
7 |
=A6&B6 |
=A6^C6 |
=A5\C6 |
|
这些集合运算的结果仍然是个排列,而且序表本身也可以看成是个由其所有记录构成的排列,也可以参与这些集合运算,但是计算结果将不再是序表而只是个排列了。
现在我们把之前合并 Excel 的问题再做一遍,不过还没学会改变数据结构时,要减少一个要求:只把数据合并起来而不再最后增加文件名。
A |
B |
|
1 |
=directory@p("data/*.xlsx") |
|
2 |
for A1 |
=file(A2).xlsimport@t() |
3 |
=@|B2 |
|
4 |
=file("all.xlsx").xlsexport@t(B3) |
|
A1 已经理解了。这一次 B2 使用了没有 @w 的 xlsimport 函数,它将把文件读成一个序表,@t 表示以这个文件的第一行作为序表的字段名。循环体内的 B3 把每次读出来的序表拼接起来,这会形成一个由多个序表中记录合并出来的序列,也就是一个多序表记录构成的排列。拼完之后在 A4 中用 xlsexport 函数写出去就行了,@t 同样表示把字段名写到第一行作为标题。
这个代码比之前用字符串处理时要简单很多,不需要再处理费劲处理标题的拆开装配工作了。其实,使用循环函数还能更简单:
A |
|
1 |
=directory@p("data/*.xlsx").(file(~).xlsimport@t()).conj() |
2 |
>file("all.xlsx").xlsexport@t(A1) |
多个排列也可以再构成二层序列,然后使用 conj 函数拼接成一个。
这段代码要求被合并的 Excel 文件是相同数据结构的(即有相同的列)。其实,排列并不要求所有成员记录的数据结构相同,只有引用字段时不出错就不会有问题,但这种情况事实上很罕见,我们也就不再举例说明了。

