


【程序设计】8.1 [表一表] 结构化数据
8.1 结构化数据
从这一章起,我们开始学习在日常工作中天天都要打交道的表格数据及其处理手段。
在前面合并 Excel 文件的例子中,其实我们已经见识过这种表格了:
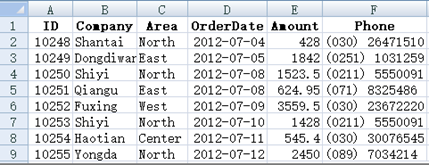
第一行是标题,解释每一列存了什么东西。每一行是一条数据,可能对应一个人、一个机构、一个订单、一个事件、…。
这种数据有个专业的术语,叫结构化数据。这是现代数据处理中最常见的数据类型。
整个表格的数据统称为一个数据表,其中的每一行(除了标题)称为一条记录,列称为字段,标题中的字符串称为字段名。上面这个表中能看见的部分有 9 条记录,对应着这个 Excel 的第 2 到第 10 行;还有 6 个字段,字段名分别是 ID、Company、 Area、OrderDate、Amount、Phone。字段名互不相同,可以唯一地标识某个列。这些字段(包括名称和次序),称为数据表的数据结构,简称结构。
结构化数据也就是有数据结构的数据。
表格中 A2:F9 部分就是数据表里的数据了。我们会说某条记录的某个字段的取值是什么。比如这里第 2 条记录的 ID 字段取值为 10248,第 8 条记录的 Area 字段取值为 Center。数据表中每条记录的每个字段都会有一个取值。
注意,数据表中只有字段有名称,记录没有名称。我们后面会讲用什么办法来标识和区分记录。
可以有各种各样的数据表,不同数据表的数据结构当然可以不同。一个数据表一定要有一套数据结构,而且也只能有一套。有时我们也会说到记录的结构,意思就是指记录所在的数据表的结构。
因为结构化数据经常会以这种行列式表格的形式呈现,我们也会直观地把记录和字段称为行和列,这是数据库界的通行术语,并不是本书发明的通俗说法。甚至,有时候数据表呈现出来时已经没有明显的行和列了(马上要讲到这样的例子),人们仍然会用行和列这些术语来表示记录和字段。
以表格形式存在的结构化数据在现实中很常见,大部分读者都会有这种经验。看着一个表格去理解记录、字段等概念并不会困难,我们这里就不再多举例了。
但是,结构化数据并不是总以上面的表格形式呈现,还可能是别的样子。
比如这样的:
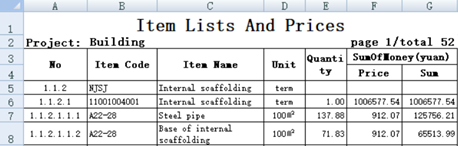
从第 5 行的数据可以看成是一个数据表,但字段是什么呢?看起来在第 3、4 行的内容是字段名,但 Item Code 这种中间有空格的字符串通常并不适合作为字段名(其实 SPL 是支持的,但很少用,本书也不打算涉及),而且右边的 F 列和 G 列的字段名也说不清是不是 F4 和 G4 的内容。
其实,这里的第 3、4 行的内容只能认为是字段的一种描述,其真正的数据结构(主要是字段名)并不一定是表格上看到的标题行内容,还可以另行说明和设定。
还有这种形式的:
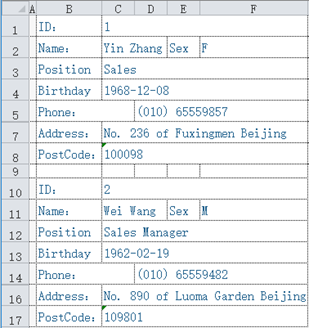
这已经不是行列表格形式了,但仍然可以构成一个有 2 条记录的数据表。字段可以是 ID、Name、Sex、Position、Birthday、Phone、Address、PostCode 这几个。
那么,到底什么才是结构化数据和数据表呢?
再观察上面这几个例子。同一个 Excel 里的数据都在描述同一类事物,比如一个人、一个订单等。这些事物有相同的属性,比如人都有 Name、Sex、Birthday 等共同的属性,订单也都有客户、日期、金额等共同属性。每一件事物就是一条记录,而这些属性就是字段,一批多个相同属性的事物就构成一个数据表,也就是数据表有多条记录和多个字段。
数据表、记录、字段都是些抽象的概念,本质上对应着某种事物及其属性,和看到的 Excel 表格并不是一回事。数据表也没有必须遵守的固定呈现样式,只是为了让人们容易辨识,通常会呈现成行列式表格,并在标题中填入字段名。
对于 Excel 表格中的数据,只要能提取用于描述某类事物的属性,并且如果对应了多个同类事物,它们的属性是相同的,这时候就可以认为是结构化数据了。至于表格中的标题内容是什么、以及有没有标题、甚至表格是不是行列式的,都不是重要的因素了。关键仅在于是否描述了有(共同)属性的一类事物。
再看一个表格:
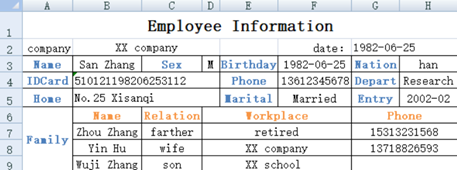
从这里能找出结构化数据吗?也就是说能不能提取出用属性描述的事物?
可以的,但这里有两个数据表。一个在上半部分,描述雇员的基础信息,字段有 Name、Sex、Birthday、Nation、IDCard、…等等;另一个在下半部分,描述雇员的家庭成员,有 Name、Relation、Workplace、Phone 这些字段。雇员本人和家庭成员是两种不同的事物,有不同的属性。一个数据表只能有一套数据结构,也只能描述一类事物。要完整描述一个雇员的信息就需要两个数据表(本人和家庭成员)。
还有这种情况:
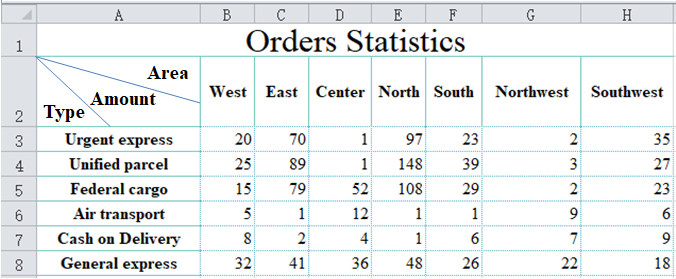
这看起来是个行式表格,应该很容易提取出结构化数据。但是,数据结构是什么样的呢?
简单来看,可以把每一列作为字段名,也就是 Type,West,East,…这些。这确实是一种办法,但并不方便。结构化数据在行和列(记录和字段)方向上的计算能力是不同的,当我们要统计各个地区的合计时,要把字段一个个列出来,很麻烦,而在记录上的统计就容易得多。
为了方便统计,对于这种交叉表格,我们通常会设计成三个字段的数据表:Type、Area、Amount,这样两个方向的统计都会比较简单,而且必要时也可以把这个表格换一种方式显示,比如把 Area 放在行上,而 Type 放在列上,这并不影响数据结构。
但是,这种结构设计也不是必然,要根据下一步的计算目标来决定,有时候仍然设计成 Type,West,East,…这种会更方便。
从纷乱的表格中找出结构化数据,我们称这件工作为结构化解析,它并不是一件非常明显而轻松的事情,需要因地制宜、根据目标设计合理的数据结构。结构化解析也是个非常重要的工作,数据不做结构化就很难实施进一步的计算,而不能计算的数据是没有意义的。
结构化数据当然不一定总是存储成 Excel 文件(反过来,Excel 存的数据当然也不总是结构化数据),事实上最多的结构化数据是存储在数据库中的。不过数据库的知识过于专业,本书不打算涉及。
在日常工作中,除了 Excel 文件外,文本文件也常用于存储结构化数据,常见的格式有 txt 和 csv 两种。文本文件通常都是每行对应一条记录,通常第一行会是标题,通常就是字段名。txt 文件的列之间用制表符 \t 分隔,而 csv 文件则以逗号分隔。
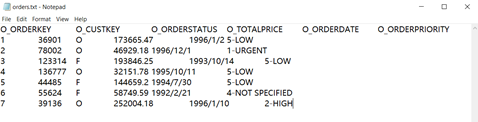
用制表符分隔的 txt 文件

用逗号分隔的 csv 文件
文本文件在显示时显然没有 Excel 那么整齐,但并不会导致记录的字段错位。

