


多维分析后台实践 1:基础宽表
【摘要】
用实例、分步骤,详细讲解多维分析(OLAP)的实现。点击了解多维分析后台实践 1:基础宽表
实践目标
本期目标是练习如何搭建多维分析后台的基础宽表,并通过 SPL 和 SQL 访问基础宽表。
实践的步骤:
1、 准备基础宽表:将基础宽表数据从数据库中取出,存成组表文件。
2、 访问基础宽表:用 SPL 或者 SQL 语句访问。
本期样例宽表为 customer 表。从 Oracle 数据库中取出宽表数据的 SQL 语句是 select * from customer。执行结果如下图:

其中字段包括:
CUSTOMER_ID NUMBER(10,0), 客户编号
FIRST_NAME VARCHAR2(20), 名
LAST_NAME VARCHAR2(25), 姓
PHONE_NUMBER VARCHAR2(20), 电话号码
BEGIN_DATE DATE, 开户日期
JOB_ID VARCHAR2(10), 职业编号
JOB_TITLE VARCHAR2(32), 职业名称
BALANCE NUMBER(8,2), 余额
EMPLOYEE_ID NUMBER(4,0), 开户雇员编号
DEPARTMENT_ID NUMBER(4,0), 分支机构编号
DEPARTMENT_NAME VARCHAR2(32), 分支结构名称
FLAG1 CHAR(1), 标记 1
FLAG2 CHAR(1), 标记 2
FLAG3 CHAR(1), 标记 3
FLAG4 CHAR(1), 标记 4
FLAG5 CHAR(1), 标记 5
FLAG6 CHAR(1), 标记 6
FLAG7 CHAR(1), 标记 7
FLAG8 CHAR(1), 标记 8
多维分析计算的目标可以用下面 Oracle 的 SQL 语句表示:
select department_id,job_id,to_char(begin_date,'yyyymm') begin_month ,sum(balance) sum,count(customer_id) count
from customer
where department_id in (10,20,50,60,70,80)
and job_id in ('AD_VP','FI_MGR','AC_MGR','SA_MAN','SA_REP')
and begin_date>=to_date('2002-01-01','yyyy-mm-dd')
and begin_date<=to_date('2020-12-31','yyyy-mm-dd')
and flag1='1' and flag8='1'
group by department_id,job_id,to_char(begin_date,'yyyymm')
准备宽表
编写 etl.splx,从数据库中取出数据生成组表文件 customer.ctx,即存储为宽表。代码示例如下:
A |
B |
|
1 |
=connect@l("oracle") |
=A1.cursor("select * from customer") |
2 |
=file("data/customer.ctx").create@y(customer_id,first_name,last_name,phone_number,begin_date,job_id,job_title,balance,employee_id,department_id,department_name,flag1,flag2,flag3,flag4,flag5,flag6,flag7,flag8) |
|
3 |
=A2.append(B1) |
>A2.close(),A1.close() |
A1:连接预先配置好的数据库 oracle。@l 选项是将字段名处理成小写,l 是字母 L 的小写,不是数字 1。
B1:建立数据库游标,准备取出 customer 表的数据。customer 是事实表,实际应用中一般都比较大,所以用游标的方式,避免内存溢出。
A2:定义列存组表文件。字段名和 B1 完全一致。
A3:边取出游标 B1,边输出到组表文件中。
B3:关闭组表文件和数据库连接。
当宽表数据量有一亿行时,导出组表文件约 3.5GB。
部署集算服务器
按照教程部署好集算器节点机。将 meta.txt 放入主目录中,文件内容是表名和文件名的对应关系,如下:
Table File Column Type
customer data/customer.ctx
文件名是相对于主目录的,假如节点机主目录是 d:/esproc/,那么完整的文件名就是 d:/esproc/data/customer.ctx。
访问宽表
多维分析后台需要被通用的前端所调用。调用的方式有两种,第一种是使用 SQL;第二种是执行脚本,提交过滤条件、分组字段等参数给后台执行。
一、SQL
我们先来看第一种,以 Java 调用集算器 JDBC 为例来说明。Java 示例代码如下:
public void testOlapServer(){
Connection con = null;
java.sql.Statement st;
try{
// 建立连接
Class.forName("com.esproc.jdbc.InternalDriver");
// 根据 url 获取连接
con= DriverManager.getConnection("jdbc:esproc:local://?onlyServer=true&sqlfirst=plus");
st = con.createStatement();
// 直接执行 SQL+ 语句,获取结果集
ResultSet rs = st.executeQuery("select department_id,job_id,year(begin_date)*100+month(begin_date) begin_month ,sum(balance) sum,count(customer_id) count from customer where department_id in (10,20,50,60,70,80) and job_id in ('AD_VP','FI_MGR','AC_MGR','SA_MAN','SA_REP') and (begin_date between timestamp('2002-01-01 00:00:00') and timestamp('2020-12-31 23:59:59')) and flag1='1'and flag8='1'group by department_id,job_id,year(begin_date)*100+month(begin_date)");
// 继续处理结果集,将结果集展现出来
}
catch(Exception e){
out.println(e);
}
finally{
// 关闭连接
if (con!=null) {
try {con.close();}
catch(Exception e) {out.println(e); }
}
}
}
这里的 customer.ctx 会被完全读入内存,不适合大数据量的情况。对于大数据量,可以在表名前面加 /*+ external*/,组表会被处理成游标。或者也可以采用下面执行脚本的方法。
加上 /*+ external*/ 之后的 SQL 如下:
select department_id,job_id, string(begin_date,'yyyyMM'),sum(balance) sum,count(customer_id) count
from /*+ external*/ customer
where department_id in (10,20,50,60,70,80) and job_id in ('AD_VP','FI_MGR','AC_MGR','SA_MAN','SA_REP') and begin_date>=date('2002-01-01','yyyy-mm-dd') and begin_date<=date('2020-12-31','yyyy-mm-dd') and flag1='1' and flag8='1'
group by department_id,job_id, string(begin_date,'yyyyMM')
用游标时,Java 程序执行的总时间是 88 秒。
需要说明的是,这里的执行时间绝对数值并不重要。记录执行时间是为了后面的实践中采用多种优化方法时,可以将时间缩短多少。
我们可以用多线程并行的方式执行 SQL,方法是给表名加上/*+parallel (n) */。2 线程并行完整的 SQL 如下:
select department_id,job_id,year(begin_date)*100+month(begin_date) begin_month ,sum(balance) sum,count(customer_id) count
from /*+ external*/ /*+parallel (2) */ customer
where department_id in (10,20,50,60,70,80) and job_id in ('AD_VP','FI_MGR','AC_MGR','SA_MAN','SA_REP')
and (begin_date between timestamp('2002-01-01 00:00:00') and timestamp('2020-12-31 23:59:59'))
and flag1='1' and flag8='1'
group by department_id,job_id,year(begin_date)*100+month(begin_date)"
2 线程并行时,Java 程序执行的总时间是 46 秒。
二、执行脚本
多维分析前端要调用的入口是 olap.splx,用 SPL 代码访问宽表并进行过滤和分组汇总计算。
调用入口时,前端要通过网格参数将宽表名称 customer 和其他必须的信息传给 olap.splx。SPL 代码中,需要对前端传入的参数分拆,分别进行处理、转换,以获得更好的性能。因此,除了宽表名称单独传入之外,我们采用比较容易分拆解析的 json 字符串的方式传入其他参数。而且前端将参数动态拼写成 json 字符串也比较容易。
第一步:编写 customer.splx,解析参数 json 串。
编写 olap.splx 之前,先要编写 customer.splx,用来解析传入参数 json 串。因为每个宽表的参数和处理方式都不一样,所以每个宽表要对应一个 json 串解析的 splx 文件,文件名称和宽表名称相同,例如:customer.splx。
定义网格参数 arg_json,将部门编号、工作编号、标志位、日期范围、分组字段、聚合表达式整合在 arg_json 中传给 SPL。参数设置窗口如下:
arg_json 参数值样例:
{
aggregate:
[
{
func:"sum",
field:"balance",
alias:"sum"
},
{
func:"count",
field:"customer_id",
alias:"count"
}
],
group:
[
"department_id",
"job_id",
"begin_yearmonth"
],
slice:
[
{
dim:"department_id",
value:[10,20,50,60,70,80]
},
{
dim:"job_id",
value:["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"]
},
{
dim:"begin_date",
interval:[date("2002-01-01"),date("2020-12-31")]
},
{
dim:"flag1",
value:"1"
},
{
dim:"flag8",
value:"1"
}
]
}
说明:
1、 组表名称作为单独参数传递,不放入 json 串中。
2、 aggregate 是聚合表达式数组,每个成员包含聚合的字段名 field、聚合函数 func 和别名 alias。
3、 group 是分组字段数组。如果成员是 begin_date 则按照日期分组,如果是 begin_yearmonth 则按照年月分组。对于多维分析前端来说,可以认为是两个不同的字段。
4、 slice 是切片表达式数组。每个成员包含切片的维度 dim、切片的值(数组或单值)或者 between 的范围 interval。切片表达式之间都是与(and)关系。
customter.splx 的返回结果是四个字符串,依次是“本次计算所用到的字段名”、聚合表达式、分组表达式和切片(过滤条件)表达式。其中,字符串“本次计算所用到的字段”包括聚合表达式、分组表达式中用到的所有字段,不包括切片表达式用到的字段。这个字符串用于给游标规定取出的字段,字段取出的越少,性能越好。SPL 代码示例如下:
A |
B |
C |
|
1 |
func |
||
2 |
if A1.value==null |
return "between("/A1.dim/","/A1.interval(1)/":"/A1.interval(2)/")" |
|
3 |
else if ifa(A1.value) |
return string(A1.value)/".contain("/A1.dim/")" |
|
4 |
else if ifstring(A1.value) |
return A1.dim/"==\""/A1.value/"\"" |
|
5 |
else |
return A1.dim/"=="/A1.value |
|
6 |
=json(arg_json) |
||
7 |
=A6.aggregate.(~.func/"("/~.field/"):"/~.alias).concat@c() |
||
8 |
=A6.group.(if(~=="begin_yearmonth","year(begin_date)*100+month(begin_date):begin_yearmonth",~)).concat@c() |
||
9 |
=A6.aggregate.(field) |
=A6.group.(if(~=="begin_yearmonth","begin_date",~)) |
|
10 |
=(A9|C9).id().concat@c() |
||
11 |
=[] |
||
12 |
for A6.slice |
=[func(A1,A12)] |
>A11|=B12 |
13 |
return A10,A7,A8,A11.concat(" &&") |
||
A1 到 C5 是子程序,在调用的时候才会执行。为了方便说明,我们按照执行的顺序来讲解。
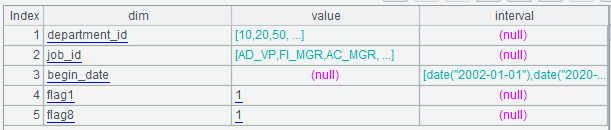
A6:将 arg_json 解析成序表。解析的结果是多层嵌套的序表,如下图:

其中的 aggregate 为:

其中的 group 为:

其中的 slice 为:
A7:先将 aggregate 计算成冒号相连的字符串序列,如下图:

再将序列用逗号连接成一个字符串:sum(balance):sum,count(customer_id):count。
A8:将 group 中的 begin_yearmonth 替换成表达式 year(begin_date)*100+month(begin_date):begin_yearmonth。再把 group 成员用逗号连接成一个字符串 department_id,job_id, year(begin_date)*100+month(begin_date):begin_yearmonth。
A9:取得 aggregate 中的 field 字段,也就是聚合表达式用到的所有字段名。
C9:将 group 中的 begin_yearmonth 替换成 begin_date,结果就是分组表达式所用到的所有字段名。
A10:将 A9、C9 合并后,用逗号连接成字符串,求得本次计算所需要的所有字段名:balance,begin_date,customer_id,department_id,job_id。
A11:定义一个空序列,准备存放切片(过滤条件)表达式序列。
A12:循环计算 slice,循环体是 B12、C12。
B12:用 A12(当前 slice)作为参数,调用子程序 A1。
B2:如果当前 slice 的 value 为空,那么就是 between 计算。此时 C2 计算并返回结果为 between(begin_date,date("2002-01-01"):date("2020-12-31"))。
B3:如果当前的 slice 的 value 是序列,那么就是 contain 计算。此时 C3 计算并返回结果为 [10,20,50,60,70,80].contain(department_id),或者 ["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"].contain(job_id) 。
B4:如果当前的 slice 是字符串,那就是字符串等值计算。此时 C4 计算并返回结果为 flag1=="1" 或者 flag8=="1"。
B5:如果上述都不是,那就是数值型的等值计算。当前的 slice 没有此计算,其他的例子比如:employee_id==2。
到此为止子程序结束。
C12:A1 的返回结果追加到 A11 中。继续 A12 中的循环,到循环结束。
A13:返回 A10,A7,A8,A11.concat("&&"),依次是:
本次计算用到的字段名:balance,begin_date,customer_id,department_id,job_id
聚合表达式:sum(balance):sum,count(customer_id):count
分组表达式:department_id,job_id,string(begin_date,"yyyyMM"):begin_yearmonth
切片表达式:
[10,20,50,60,70,80].contain(department_id) && ["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"].contain(job_id) && between(begin_date,date("2002-01-01"):date("2020-12-31")) && flag1=="1" && flag8=="1"
说明:这里的计算包括了 OLAP 切片所有的情况,只是参数写法略有不同。其他情况包括:
1、 数值型的 between 计算,例如 employee_id 在 100 和 200 之间。arg_json 的 slice 中要增加:
{
dim:"employee_id",
interval:[100,200]
},
func A1 计算之后为: between(employee_id,100:200)。
2、 日期型或者数值型的大于等于,或者小于等于计算,例如 begin_date>= date("2002-01-01")。arg_json 的 slice 中增加:
{
dim:"begin_date",
interval:[date("2002-01-01"),]
},
func A1 计算之后为:between(begin_date,date("2002-01-01"):)。
再如,employee_id<=200。arg_json 的 slice 中增加:
{
dim:"employee_id",
interval:[,200]
},
func A1 计算之后为:between(employee_id,: 200)。
第二步:编写 olap.splx,实现多维分析计算。
在 olap.splx 中调用 customer.splx 解析 json 串之后做 OLAP 计算。olap.splx 参数是 arg_table 和 arg_json:
SPL 代码如下:
A |
|
1 |
=call(arg_table/".splx",arg_json) |
2 |
=file("data/"/arg_table/".ctx").open() |
3 |
=A2.cursor@m(${A1(1)};${A1(4)};2) |
4 |
=A3.groups(${A1(3)};${A1(2)}) |
5 |
return A4 |
A1:根据 arg_table 参数的值调用 customer.splx,调用参数是 arg_json,返回值是前面提到过的一个字段名集合和三个表达式字符串。
A2:根据 arg_table 参数,打开组表对象 customer.ctx。
A3:建立带条件的 2 线程并行游标,条件是一个宏。实际执行的语句是:
=A2.cursor@m(balance,begin_date,customer_id,department_id,job_id;[10,20,50,60,70,80].contain(department_id) && ["AD_VP","FI_MGR","AC_MGR","SA_MAN","SA_REP"].contain(job_id) && between(begin_date,date("2002-01-01"):date("2020-12-31")) && flag1=="1" && flag8=="1";2)
A4:对 A3 做小分组汇总。实际执行的语句是:
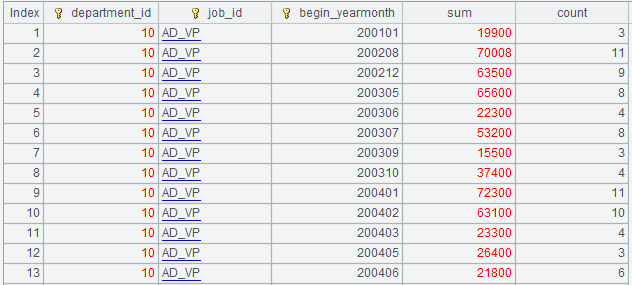
=A3.groups(department_id,job_id,string(begin_date,"yyyyMM"):begin_yearmonth }; sum(balance):sum,count(customer_id):count)
执行结果如下图:
A5:返回 A4 结果集。
第三步:前端调用。
olap.splx 编写好之后,要在多维分析中作为存储过程调用,Java 代码如下:
public void testOlapServer(){
Connection con = null;
java.sql.PreparedStatement st;
try{
// 建立连接
Class.forName("com.esproc.jdbc.InternalDriver");
// 根据 url 获取连接
con= DriverManager.getConnection("jdbc:esproc:local://?onlyServer=true&sqlfirst=plus");
// 调用存储过程,其中 olap 是 splx 的文件名
st =con.prepareCall("call olap(?,?)");
st.setObject(1, "customer");
st.setObject(2, "{aggregate: [{func:\"sum\",field:\"balance\",alias:\"sum\"},{func:\"count\",field:\"customer_id\",alias:\"count\"}],group:[\"department_id\",\"job_id\",\"begin_yearmonth\"],slice:[{dim:\"department_id\",value:[10,20,50,60,70,80]},{dim:\"job_id\",value:[\"AD_VP\",\"FI_MGR\",\"AC_MGR\",\"SA_MAN\",\"SA_REP\"]},{dim:\"begin_date\",interval:[date(\"2002-01-01\"),date(\"2020-12-31\")]},{dim:\"flag1\",value:\"1\"},{dim:\"flag8\",value:\"1\"}]}");//arg_json
// 执行存储过程
st.execute();
// 获取结果集
ResultSet rs = st.getResultSet();
// 继续处理结果集,将结果集展现出来
}
catch(Exception e){
out.println(e);
}
finally{
// 关闭连接
if (con!=null) {
try {con.close();}
catch(Exception e) {out.println(e); }
}
}
}
说明:arg_json 参数的值,需要多维分析前端预先拼字符串生成好。
此时,我们是采用 2 线程进行的计算。可以将 olap.splx 改为单线程计算如下:
A3 去掉了 @m 和最后一个参数 2,其他不变。
A |
|
1 |
=call(arg_table/".splx",arg_json) |
2 |
=file("data/"/arg_table/".ctx").open() |
3 |
=A2.cursor(${A1(1)};${A1(4)}) |
4 |
=A3.groups(${A1(3)};${A1(2)}) |
5 |
return A4 |
单线程时,一亿条数据,Java 程序加后台 SPL 执行的总时间是 84 秒。
2 线程时,Java 程序加后台 SPL 执行的总时间是 42 秒。
新增数据
客户表每天都会有新增数据,需要每天定时添加到组表文件中。我们可以编写 etlAppend.splx,网格参数如下:
SPL 代码如下:
A |
|
1 |
=connect@l("oracle") |
2 |
=A1.cursor("select * from customer where begin_date=?",today) |
3 |
=file("data/customer.ctx").open().append(A2) |
4 |
>A3.close(),A1.close() |
A1:连接 oracle 数据库。
A2:建立游标,取当天数据。
A3:将今天新增数据追加到组表文件的末尾。
A4:关闭文件和数据库连接。
etlAppend.splx 需要每天定时执行。执行的方法是用 ETL 工具或者操作系统定时任务,通过命令行调用集算器脚本。
例如:
C:\Program Files\raqsoft\esProc\bin>esprocx d:\olap\etlAppend.splx


英文版