




国内主流 BI 产品关联分析能力对比
基于单表(宽表、CUBE)的多维分析有一整套标准体系,各大BI产品在这方面的差异主要也是体现在界面风格上,在查询功能方面几乎没有差别,并没有多少对比的必要。但多表关联时的多维分析情况就很不一样了,各厂家都对JOIN操作进行了界面可视化,希望业务人员自己拖拖拽拽就能搞定,进而减少具体业务需求对技术人员的依赖。但生成宽表的过程并没有一套业界通行的规范,各个厂家有自己的实现方法,结果会导致查询功能和可用性产生较大的差异,本文将对比国内主流几款BI产品在这方面的不同。
BI中的关联需求
下面以一个很常见的进销存系统的数据为例,看BI系统中可能出现的数据关联类型。
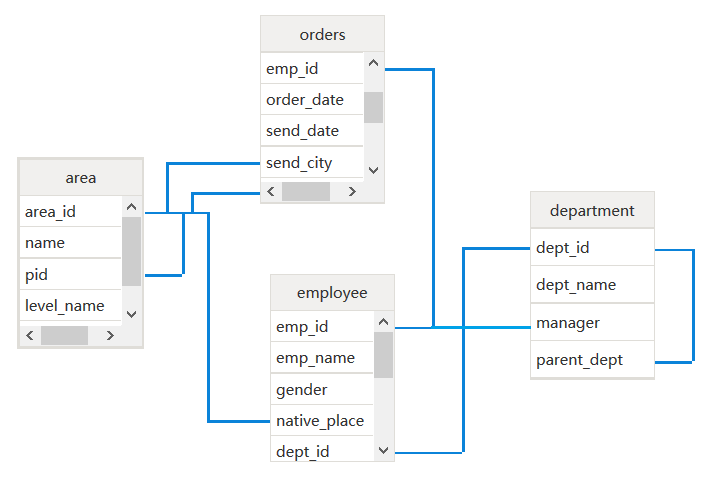
四个有关联的表:订单表orders、(销售)员工表employee、部门表department、区域表area,归类表间的关联,我们能观察到这几类:
1、常规的多级外键关联,如orders.emp_id = employee.emp_id、employee.dept_id = department.dept_id,订单表关联到员工表,员工表关联到部门表;
2、自关联表,如area.pid=area.area_id,department.parent_detp=department.dept_id,这种表的用处是把多级父子关系的同类数据存到一起。
3、互关联表,employee.dept_id = department.dept_id,同时employee.emp_id = department.manager,员工关联到部门,部门经理又反向关联到员工(因为经理也是一种员工)。
4、两表有多个关联,如orders.send_city=area.area_id,orders.recieve_city=area.area_id,订单表里的发货城市、收货城市都指向区域表area。
通常由技术人员事先生成已经关联好的宽表,以避免业务人员理解关联。这存在明显不足,常规多级关联能好点,但也有字段太多难以命名的问题,有重复表的多关联命名时就更容易混淆。自关联和互关联理论上会有无穷多字段,根本就没办法先做出宽表。所以事先生成大宽表的方法不可取,只能是跟随业务需求,有针对性的生成相关宽表。如果这个过程继续依赖于技术人员,就会导致在线分析无法“在线”,所以最好是能让业务人员自己独立完成宽表生成的工作,避免事事都求助技术人员。
基于上面这套数据,我们在一些实际业务需求中观察下不同种类的关联,同时给出相应的SQL。
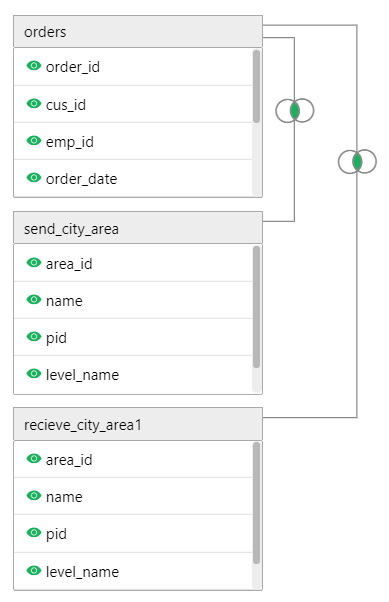
1、 分析各个销售部门的订单情况。这需要常规的多级关联,订单表关联到员工表,员工表在关联到部门表。这种容易理解,思维是线性的,把需要的表逐级关联起来即可。SQL1:
select
orders.*,employee.*,department.*
from
orders
join employee on orders.emp_id=employee.emp_id
join department on employee.dept_id= department.dept_id
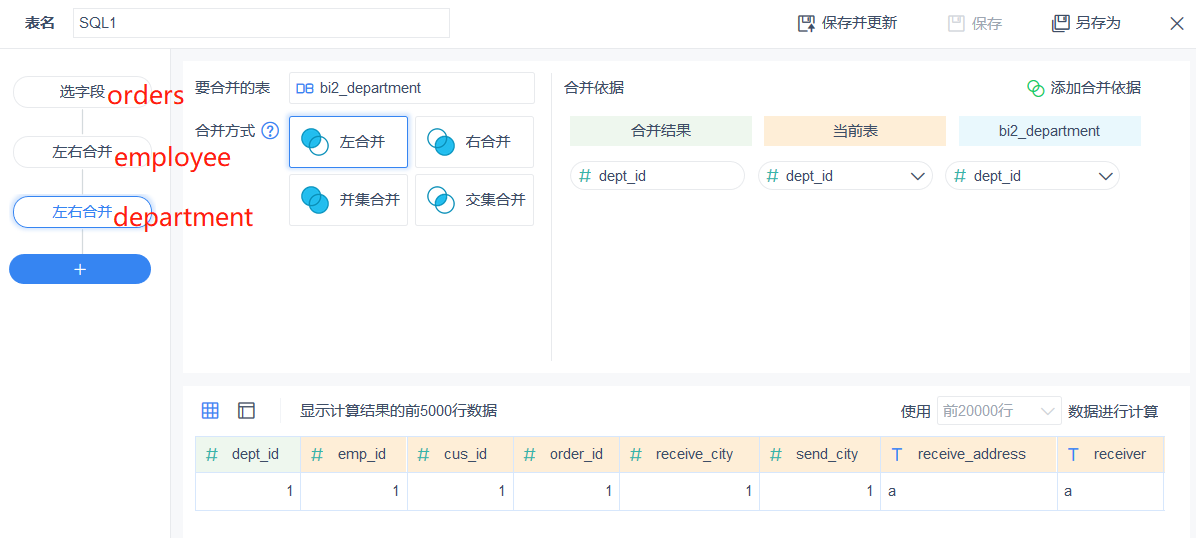
2、 分析不同地区下各个城市的销售情况。地区、省份、城市都存在区域表(area)中,要生成待分析cube,需要选出area表三次,它们之间用本表的pid和area_id关联,分别代表三种级别的区域。这种物理表和查询过程中的逻辑表,不是简单的一对一关系,需要比较清晰的思路才能关联正确。SQL2:
select orders.*,region.*, province.*,city.*
from
orders
join area city on orders.send_city=city.area_id
join area province on city.pid=province.area_id
join area region on province.pid=region_area_id
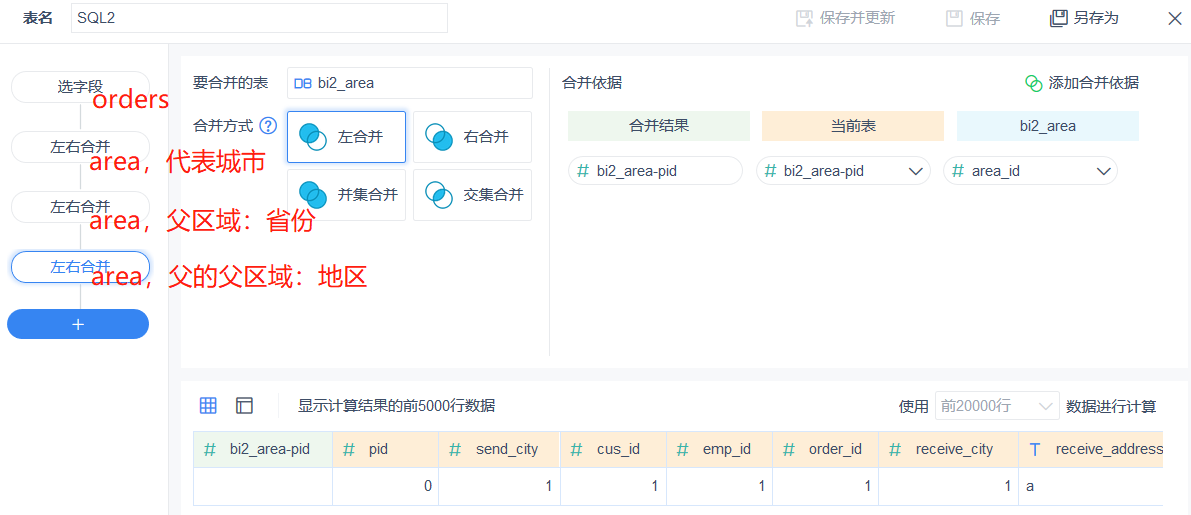
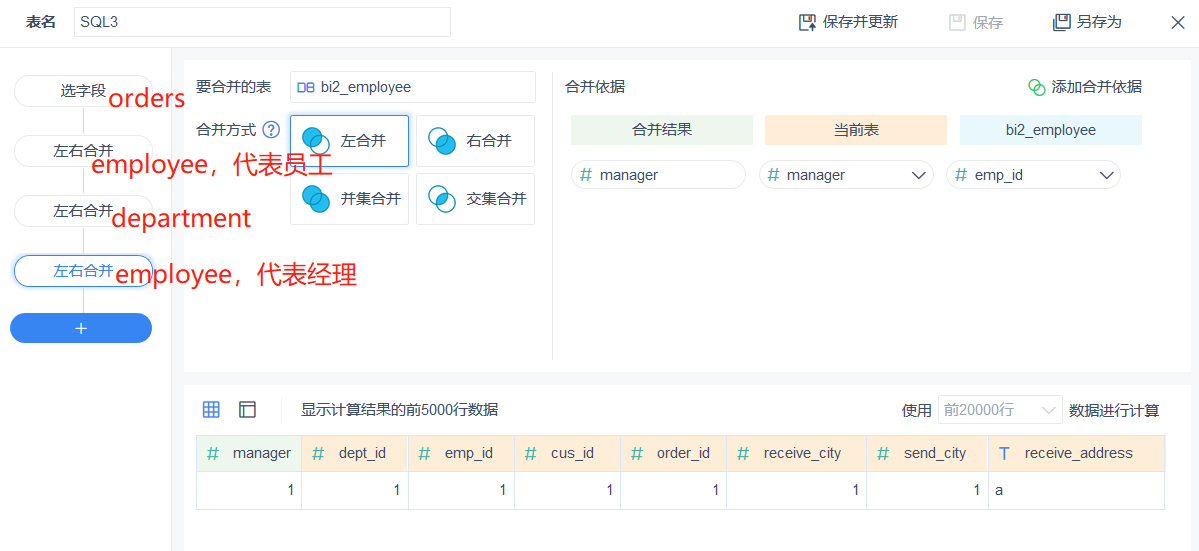
3、 分析各部门销售情况时,把部门经理的信息也纳入进来,比如要考察男性/女性经理所带领的部门有什么销售特点。员工表关联到部门表后,通过经理字段再关联回员工表。前后两个员工表代表逻辑上的员工、经理。SQL3:
select
orders.*,employee.*,department.*,managerTable.*
from
orders
join employee on orders.emp_id=employee.emp_id
join department on employee.dept_id= department.dept_id
join employee managerTable on department.manager=managerTable.emp_id
4、 订单表中有发货城市、收货城市,如果要找同城的订单,就需要订单表分别两次关联区域表(area),根据外键字段的不同含义得到发货城市、收货城市两个逻辑表。
SQL4:
select
orders.*,sendCity.*,recieveCity.*
from
orders
join area sendCity on orders.send_city=sendCity.area_id
join area recieveCity on orders.recieve_city= recieveCity.area_id
实际项目中的一个分析主题,往往不只出现一种关联,混合在一起,繁度比较大,会增大关联的难度。但为了考察功能,我们采用简单示例,下面考察下各种BI产品在界面上怎么实现不同类型的关联。
永洪BI
永洪BI制作组合数据集就是对以上各种关联的等效实现,把SQL中逻辑表都选出来,正确设置表关系就得到宽表了。
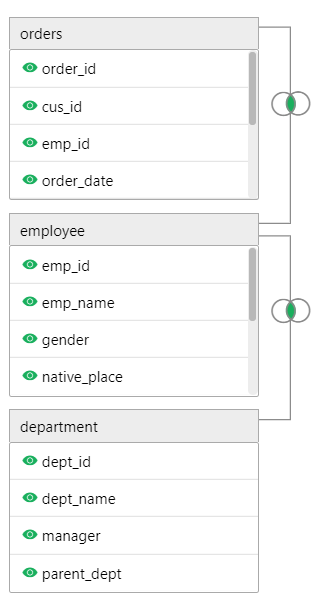
常规多级关联(SQL1)
订单表关联员工表,员工表关联部门表:
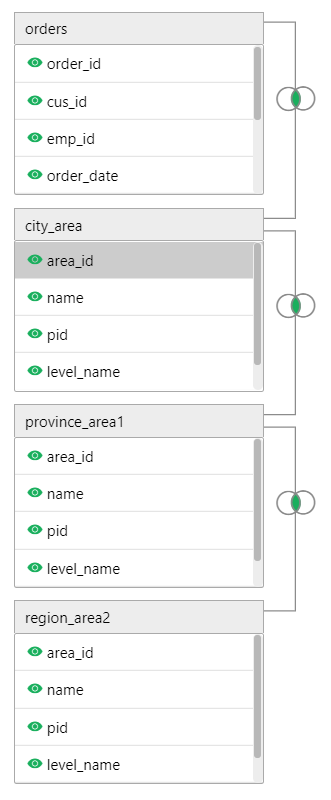
自关联(SQL2)
订单表关联到城市表,城市表通过pid关联本表找到省份,省份表通过pid关联本表找到地区:
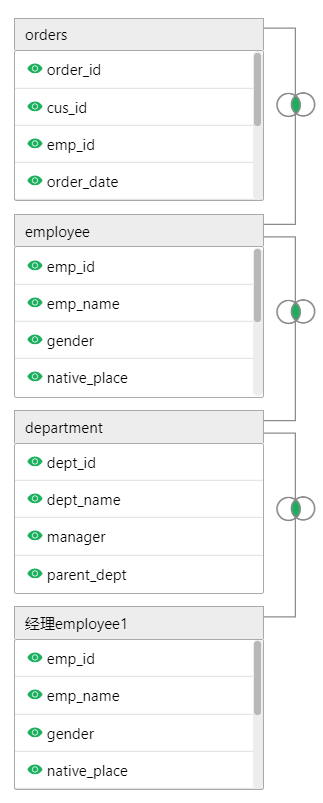
互关联(SQL3)
员工表关联部门表,部门表又关联回员工表(代表经理):
两表多关联(SQL4)
订单表两次关联到区域表area,分别代表发货城市、收货城市:
永洪BI能顺利完成各种类型的关联,选出的所有逻辑表的关联关系也粗略的进行了图示(整体图上有表的关联,但没有精确到字段)。如果读者是理解SQL的技术人员,看上面这些可视化的关联视图会感觉到很顺畅,也很形象,和自己写的JOIN语句完全一一对应。但如果是业务人员,则还是会有较大的障碍。用户必须了解这些表之间是如何关联的(通过哪些字段关联),并理解JOIN运算,而这是设计数据结构的技术人员才能掌握的技能。在情况简单时还不容易错,表多了关联多了,常常是一团乱麻。可视化界面能提供选表、选字段的便利,但不会降低对操作人员技能要求。
期望通过实现JOIN可视化,把技术人员负责的关联查询转嫁到业务人员身上,效果不理想。因为困难主要是理解力不够造成的,而不是界面不方便性。
帆软BI
帆软BI也是宽表方式。
常规多级关联(SQL1)
第一步是选出orders表,然后通过两个“左右合并”操作把employee、department表关联起来。
自关联(SQL2)
互关联(SQL3)
两表多关联(SQL4)
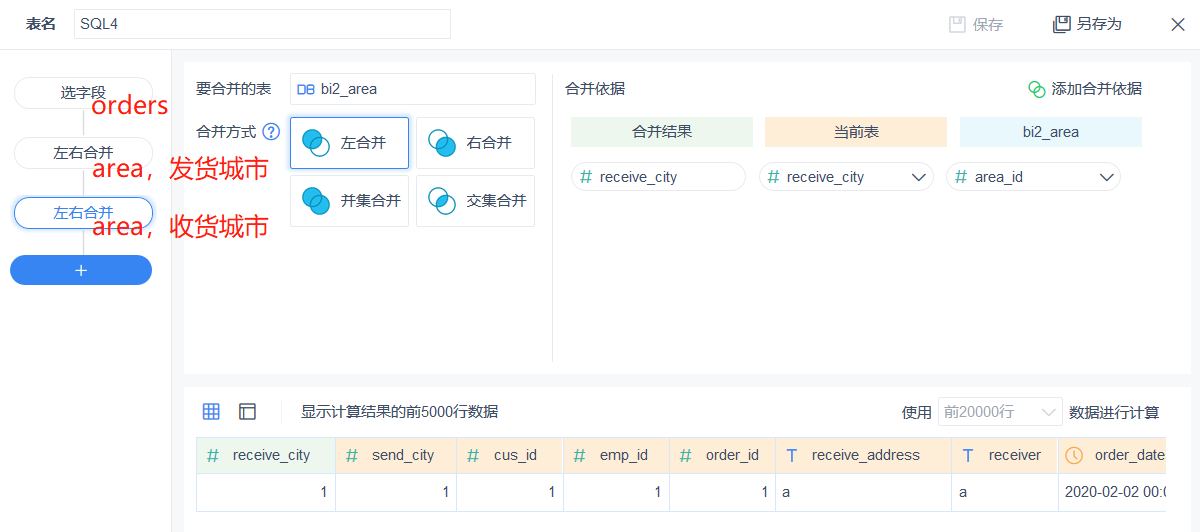
帆软BI也能实现各种类型的关联,对比永洪BI,少了几个逻辑表的整体视图,而是顺序的把逻辑表逐个关联进来。界面看起来差异很大,但关联能力可以认为是等效的,仍然是SQL JOIN的可视化路线。也就同样存在因为业务人员欠缺技能的硬伤,业务人员难以独立的完成自制宽表、自助分析整个流程。
SmartBI
SmartBI也是宽表模式。
常规多级关联(SQL1)
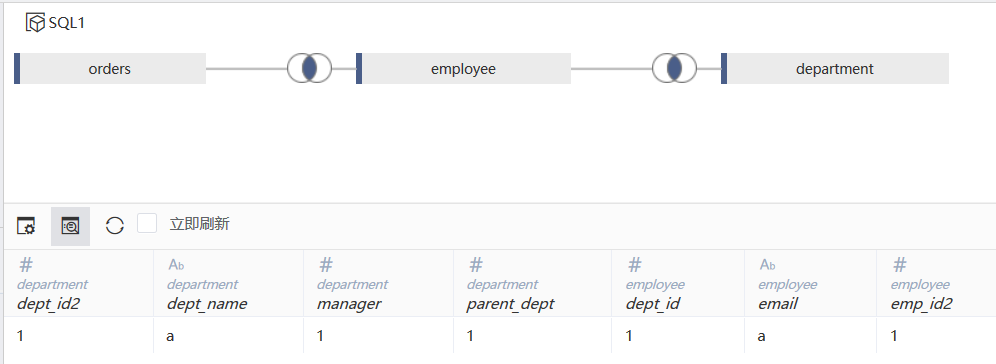
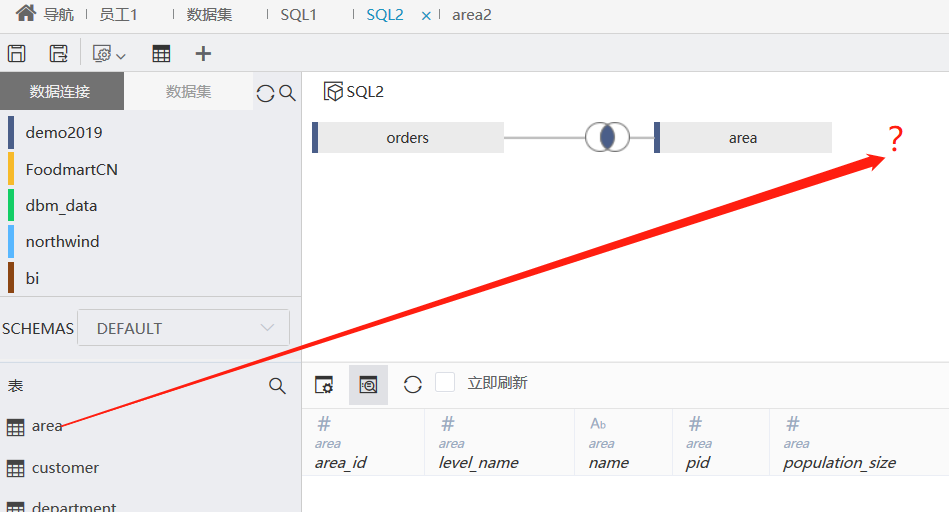
自关联(SQL2)
自关联时,还遇到了问题,不支持一个表重复选出,而我们这个需求需要把area表重复选出三次:
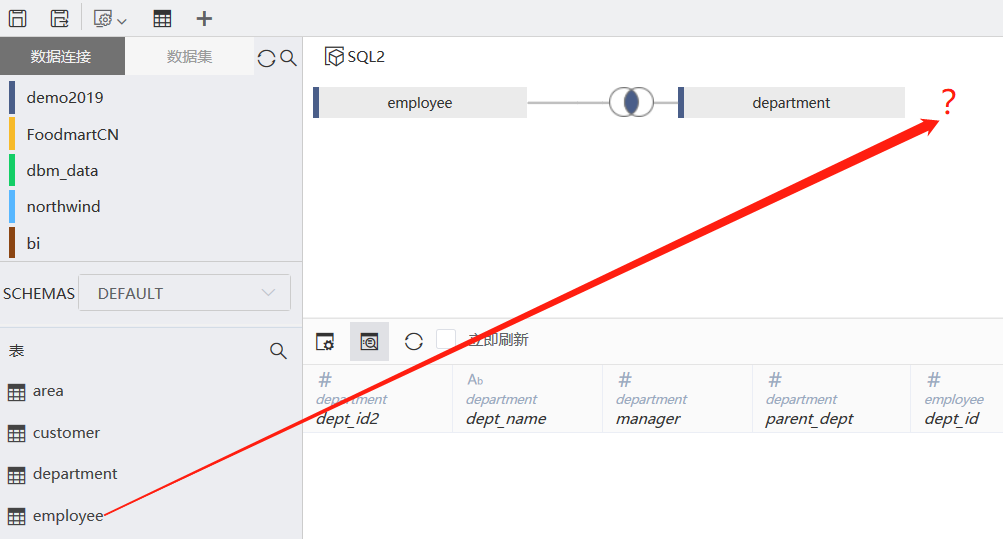
互关联(SQL3)
需要employee表选出两次,无法支持:
两表多关联(SQL4)
需要area表选出两次,无法支持:
SmartBI因为限制一个物理表只能选出一次,缩小了功能的实现范围,只能实现常规的多级表关联。对比前两家产品,前述缺陷仍然存在,还有更多的功能缺失。
润乾报表
润乾报表没有采用宽表的做法,但对数据的处理也是分成两个主要阶段。第一个阶段只定义物理表的关联关系,对整个数据库建模型,不涉及具体的查询业务,这个阶段完全是技术人员负责。无论哪种类型关联,都是定义物理表的外键关系,如下图区域表通过pid关联到自身的area_id:
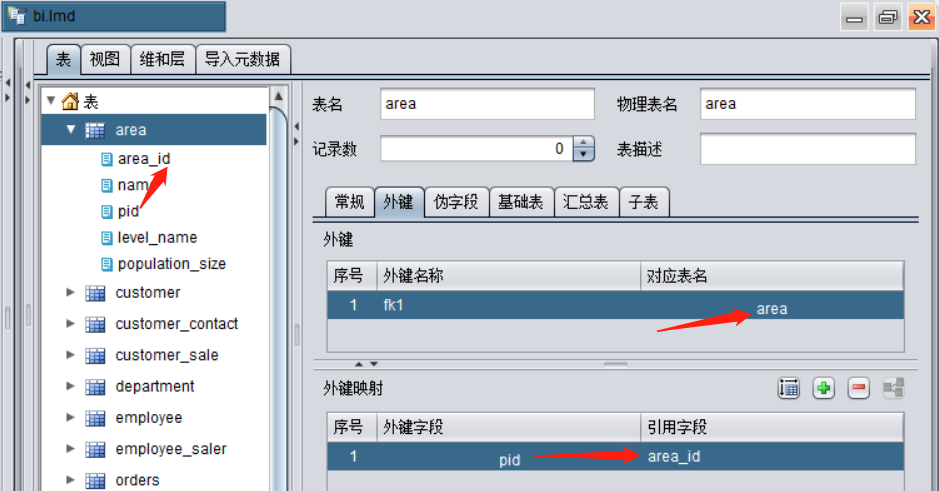
整个数据库的外键关系定义完成后,分析页面就可以自动生成所有表的多层元数据树,业务人员直接基于元数据树进行分析,分析的过程中通过选择不同层级的字段,自动实现之前各种关联。这和宽表有较大区别,下面看具体的操作。
常规多级关联(SQL1)
订单表里的外键emp_id展开后是employee表,代表该订单的销售;销售表里的dept_id再展开department表,代表该销售所在的部门。不管所需数据在任何层级,业务人员直接拖选出使用就可以。
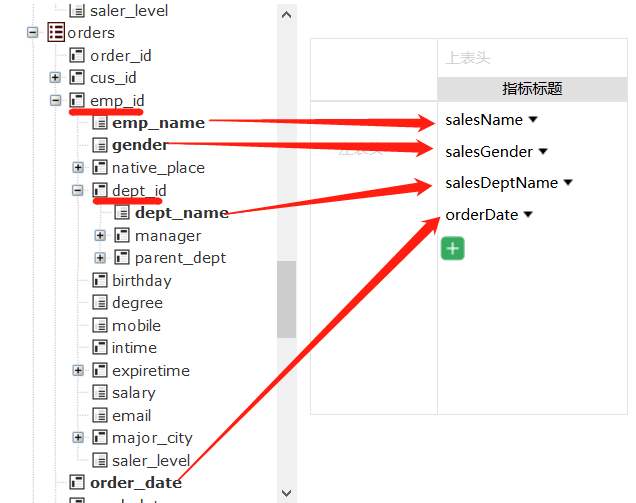
拖选之后会自动生成一种叫做DQL的查询语句:
select
orders.emp_id.emp_name salesName,
orders.emp_id.gender salesGender,
orders.emp_id.dept_id.dept_name salesDeptName,
orders.order_date orderDate
from orders
这个DQL语句通过jdbc方式提交给DQLServer执行,就查询出数据了(可以把DQLServer理解成一种数据库,实际上它做的动作是根据之前定义的元数据文件*.lmd,把DQL语句翻译成原始数据库的SQL,然后再去原始库执行,查询出数据)。
自关联(SQL2)
订单表展开发货城市,发货城市再展开父区域就是它所在的省份、父区域的父区域就是地区。
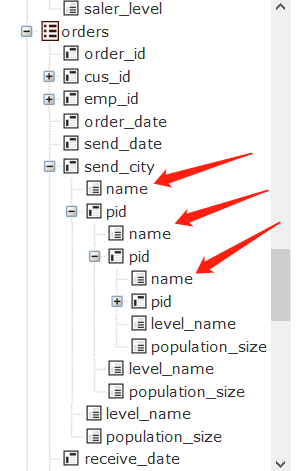
对应的DQL:
select
orders.send_city.name city,
orders.send_city.pid.name province,
orders.send_city.pid.pid.name region
from orders
互关联(SQL3)
第一层和第三层都是employee表,和第二层department表形成了互相关联。业务人员不用刻意理解互关连,这都是根据外键展开出外键表,能清晰的知道第一层是员工,第三层是经理就可以了。
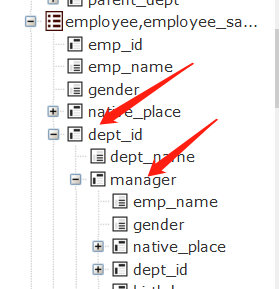
查出员工和经理姓名的DQL:
select
employee.emp_name employeeName,
employee.dept_id.manager. emp_name managerName
from employee
两表多关联(SQL4)
一个表中可以有多个外键字段,不用刻意区分是否外键到了相同的物理表,根据所展开的外键就知道一个是发货城市,另外一个是收货城市。
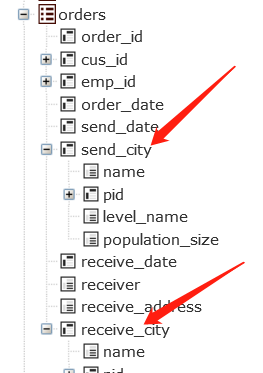
查发货和收货城市的DQL:
select
orders.send_city.name sendCity,
orders.receive_city.name receiveCity
from orders
润乾报表的DQL模式对传统BI中的分工做了新的调整,技术人员只负责描述物理表的关联关系,不参与具体业务;业务人员做分析时,根据选出信息自动生成关联查询语句。这种调整对系统中的技术人员、业务人员都有利,业务需求的频繁变动减少了对技术人员的依赖;业务人员理解树状结构并不比线状结构要难多少(人类一向以树状结构来理解事务),反而因为树状结构的丰富数据获得了更灵活的分析能力。
从上述四个例子对应的DQL也能看出来,语句中已经没有JOIN,这样感受起来是个单表(实际上是多表关联查询),关联关系被隐藏在增强的字段表达式中了,这样业务人员完全可以掌握。
而且,由于实质的关联关系是技术人员事先定义的,业务人员无论如何操作也不可能做出错误的关联。而之前的可视化JOIN方案,如果业务人员对表间关联了解不足,就很可能拖拽出错误的查询。
总结
永洪BI、帆软BI能实现所有类型的关联;SmartBI只能实现无重复逻辑表的关联; 这三家都实现了SQL JOIN技术的可视化。可视化的本意是要降低难度,给业务人员提供做关联查询的能力,但把技术思维和概念原封不动的搬上可视化界面,无助于提高业务人员的技术能力,对原本就熟悉SQL的技术人员帮助也不大。
润乾报表的DQL模式中,把多表关联查询转换成树状字段的单表查询,业务人员延用习惯的单表查询技能就可以完成非常复杂的关联查询。只要物理表结构不变,就不需要技术人员重建数据模型,这使得业务人员的灵活查询能力大大加强了,真正实现了全面的“在线”分析。
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

