




开源SPL缩短制造业库龄计算报表开发周期7.5倍
企业为了提高供应链的整体效率,通常都会把库龄查询作为常用的报表使用。通过全局范围的库龄分析,及时了解热销商品和滞销商品及其分布情况,合理地进行库存调度和市场促销,可以大大提高库存周转率,促进销售的同时降低库存资金积压风险!
问题背景
库龄查询报表涉及的计算逻辑较复杂,在使用 SQL 实施时开发效率低下,且不易维护。下面是库龄计算规则。
该计算涉及两张表:现有量和事务处理。
《现有量》存的是 20160930 某组织某子库某物料的库存数。
《事务处理》存的是 20160801~20160930 这个时间段某组织某子库某物料的入库记录。
两张表的关联字段为组织、子库和物料。
最后要形成的数据格式如下:
时间 |
组织 |
子库 |
物料 |
库存量 |
库龄(天) |
20160927 |
A |
A |
A |
200 |
3 |
库龄的计算方法为:由 20160930 里 A 组织 A 子库 A 物料的库存量去反推,找到《事务处理》里 A 组织 A 子库 A 物料的按日期从大到小排列的入库记录,一直算到入库记录相加大于等于库存量。
例如:20160930 里 A 组织 A 子库 A 物料的库存量为 1000,找到《事务处理》里 A 组织 A 子库 A 物料对应的记录有 3 条
时间 |
组织 |
子库 |
物料 |
入库量 |
20160927 |
A |
A |
A |
200 |
20160917 |
A |
A |
A |
200 |
20160907 |
A |
A |
A |
200 |
那么我们针对这个 A 组织 A 子库 A 物料要生成的数据为:
时间 |
组织 |
子库 |
物料 |
库存量 |
库龄(天) |
20160927 |
A |
A |
A |
200 |
3 |
20160917 |
A |
A |
A |
200 |
13 |
20160907 |
A |
A |
A |
200 |
23 |
20160701 |
A |
A |
A |
400 |
60 天以上 |
如果《事务处理》里A 组织 A 子库 A 物料的所有入库量的和(600)还小于《现有量》库存量(1000),那么就需要有这样一条记录,时间为《现有量》的时间减去
60 天,库存量为《现有量》的库存量(1000)- 《事务处理》所有入库量的和(600),库龄为 "60 天以上"
还有一种情况:20160930 里 A 组织 A 子库 A 物料的库存量为 300,找到《事务处理》里 A 组织 A 子库 A 物料对应的记录有 3 条。
时间 |
组织 |
子库 |
物料 |
入库量 |
20160927 |
A |
A |
A |
200 |
20160917 |
A |
A |
A |
200 |
20160907 |
A |
A |
A |
200 |
那么我们针对这个 A 组织 A 子库 A 物料要生成的数据为:
时间 |
组织 |
子库 |
物料 |
库存量 |
库龄(天) |
20160927 |
A |
A |
A |
200 |
3 |
20160917 |
A |
A |
A |
100 |
13 |
如果《事务处理》里A 组织 A 子库 A 物料的所有入库量的和(600)还大于《现有量》库存量(300),那么就会出现这样的情况,当到《事务处理》的入库
量累计 (到 20160917 已经为 400) 大于《现有量》库存量(300)的时候,最后一条记录的库存量得为 100。
原方案在数据库 HIVE 上用 SQL 实现计算过程生成结果表,报表再读取中间表数据进行查询。SQL 分为 4 段,共计 140 行,虽然行数并不是很多,但要理清计算逻辑并实现并不容易;而且由于 Hive 缺少集合运算函数,还要额外用 Java 编写 UDF(用户自定义函数)才能完成,实现难度和工作量都较大。这导致消耗了 15 人天才完成报表的数据准备工作,而且这样写出来的代码,维护工作也很麻烦,难以做到热切换。
解决方案
我们最后使用开源集算器 SPL 进行改进优化,SPL 基于 Hive 取数计算,实时加工数据并将计算后结果输出给前端报表进行呈现,整个开发过程只用 2 人天完成。
具体实现脚本:
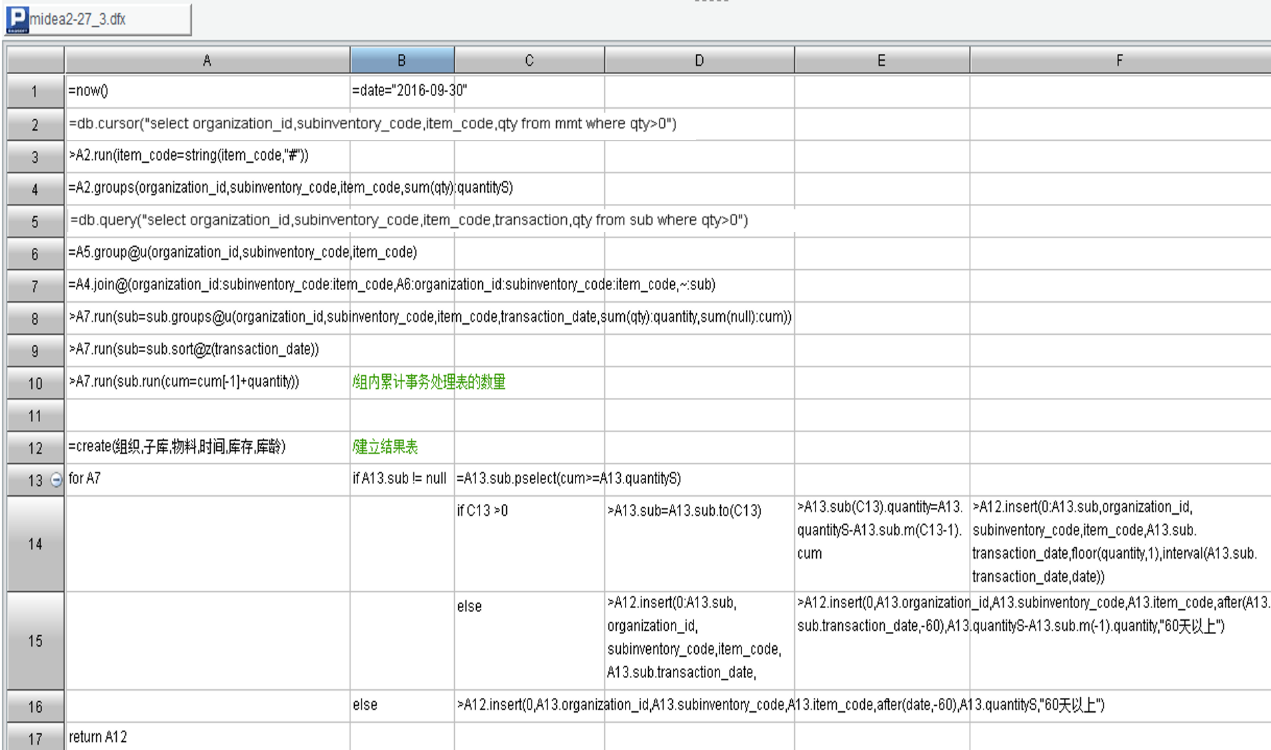
可以看到,原来需要 140 行实现的算法,这里通过 17 行“分步”的方式就实现了。整个过程按照人的自然思维实现的算法。
造目标表
for 事务处理.sort(时间:-1).group(组织, 子库, 物料)
找出现有量(可先建索引表)
for 分组成员
往目标表里插入记录;现有量减法,减到 0 break
现有量还不是 0,再插入一条 60 天以上的…
一方面代码简化能够减少维护工作量,另一方面解释执行的 SPL 代码也可以支持热切换,不像原来写 UDF 时,一旦有改动就需要重启数据库,而 SPL 脚本只要重新上载就可以了。
方案效果
使用 SPL 后,库龄查询报表的开发周期缩短了 7.5 倍。具体如下:
指标 |
SQL |
SPL(SPL) |
提升 |
代码量 |
140 行 |
17 行 |
8.2 倍 |
工作量 |
15 人天 |
2 人天 |
7.5倍 |
维护性 |
较差 |
好 |
易管理、热切换 |
耦合性 |
高 |
低 |
模块化、工具化 |
总结
在成熟报表工具的支持下,报表格式开发的工作量已经不大,工作量已经从呈现阶段转到数据准备阶段了(本例仅给出报表数据准备算法,省略了报表的制作过程),这部分开发量占比远远大于报表布局那些事。而目前大多数报表工具都没有这种能力,大家只能采用原始硬编码的方式实现,而有时又受限于数据源自身的计算能力(如本例中的 HIVE 对窗口函数等支持较弱经常要写 UDF 进一步增加难度),开发效率十分低下。
SPL 的出现很好地解决了这些问题。SPL 提供了丰富的计算类库可以满足各类复杂计算的需要,过程化脚本编辑使得算法实现也更简单,从而进一步提升报表开发效率。
除了开发效率,在性能和应用结构方面 SPL 也有很大优势。对 SPL 感兴趣可以再参考 敏捷数据计算引擎,在《SPL COOK》中还有大量 SPL 敏捷计算的例子。
其它相关案例:
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

