




开源SPL缩短石化集团多维多层叉乘报表开发周期120倍
问题背景
B 石化集团经常需要查询一种特殊的中间表,比如以物料维度、时间维度、指标名为参数进行查询,如果时间参数输入年、月、日、空中的任意一种,结果应当输出对应层级的指标。由于维度是多个,各维度的层级不固定,维度之间要事先进行动态叉乘汇总,所以这种中间表又叫“多维度多层动态叉乘中间表”。
报表样式如下:
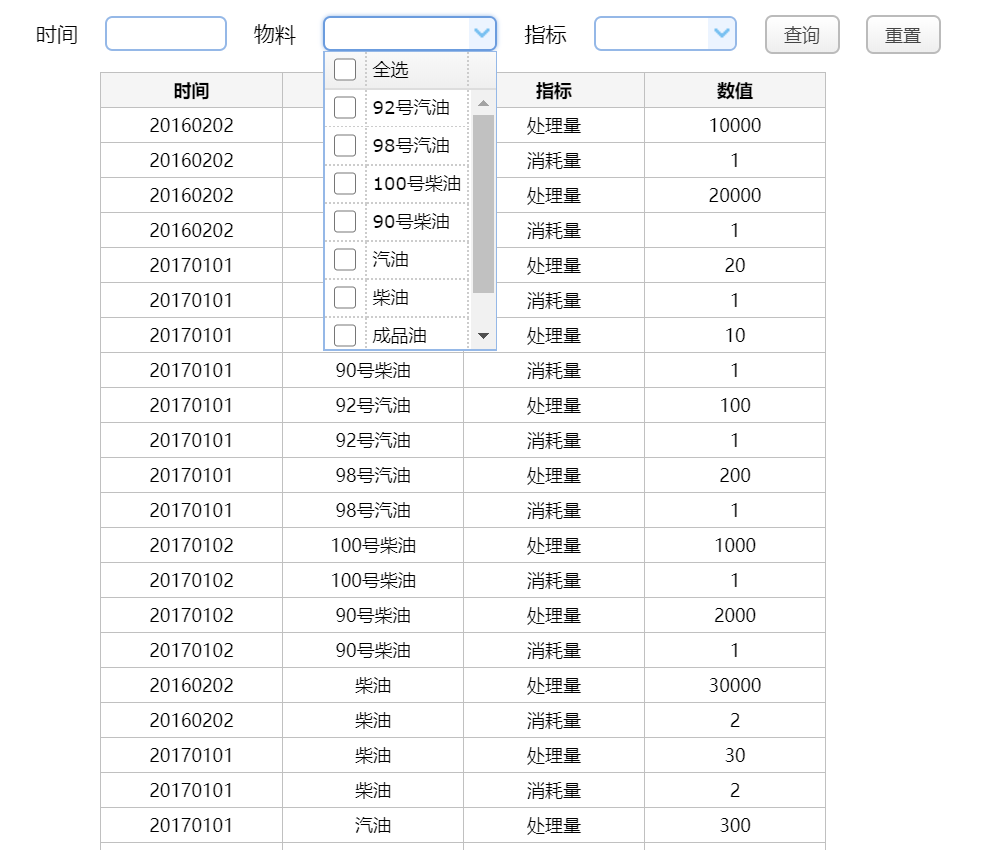
其数据形式如下:
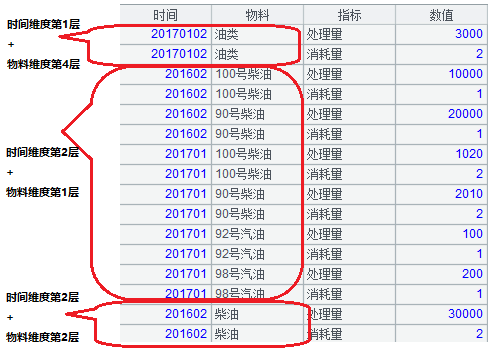
用 SQL(存储过程)很难生成此类中间表,结果往往是开发周期过长,执行效率过低,维护成本居高不下。
源数据结构
源数据的维度和层级较多,为描述清楚起见,特简化为 3 张表(视图),其中事实表一张,称为原始表;维度表两张:物料维度、空间维度。
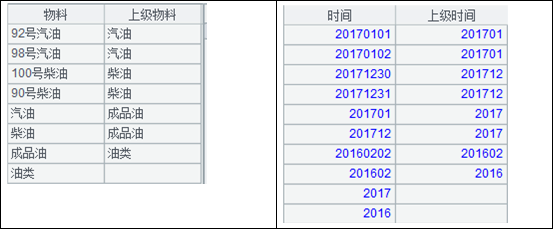
两张维度表的结构都一样,用“编号 - 上级编号”这样的双字段来表示上下级关系,上级编号为空,则表示本条数据为顶级。需要注意的是:维度层数事先未知,每次计算都可能不同。 比如下面示意数据中:时间维度表为 3 层,第一层为 20170101、20170102、20171230、20171231、20160202,第 2 层为 201701、201712,第 3 层为 2016、2017。物料维度表为 4 层,层级如图。
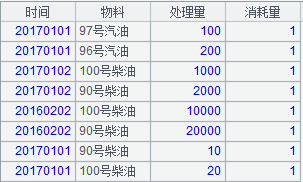
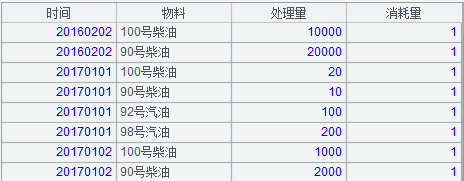
原始表(事实表)由维度和指标组成,其中维度字段对应各维度表的叶子节点;指标字段有多个,为描述清晰起见,特简化为处理量和消耗量这 2 个指标,如下:
算法描述
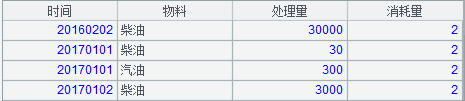
先将原始表各维度的各层级进行叉乘分组汇总,对每种组合的处理量和消耗量进行求和汇总,如物料为 4 层时间为 3 层,则需进行 12 次分组汇总,分别是:
1:时间第 1 层 + 物料第 1 层。数据同原始表,形如:
2:时间第 1 层 + 物料第 2 层。形如:
……
11:时间第 3 层 + 物料第 3 层。形如:

12:时间第 3 层 + 物料第 4 层。形如:

将上述 12 种组合合并在一起,之后进行行列转换,即将处理量和消耗量的字段名作为“指标”字段的值,将处理量和消耗量的字段值,作为“数值”字段的字段值。也可以先转换再合并,并不影响结果。其最终结果即“多维度多层动态叉乘中间表”,也就是本文开头的图片。
问题分析
原来通过硬写 SQL(存储过程)的方式实现,存在如下问题:
1. 难以简化
本算法需要将各维度各层级按一定规律组合叉乘起来,共 12 种叉乘。按理说有规律的算法都可以简化,比如用循环语句自动组合出 12 种叉乘。但使用 SQL/ 存储过程时,却不能这样简化,这是因为:
SQL/ 存储过程无法用直观的方式表达层级关系,必须用复杂的嵌套语句或难懂的多级关联来表达,比如时间第 3 层 + 物料第 3 层时,就需要分别写出 9 个子查询拼起来,语句很长。如此复杂的 12 个 SQL 语句,单独写出来就已经困难重重,要自动生成基本是妄想。所以项目组只能手工写出每个叉乘 SQL,用上千行代码才实现本算法。
难以简化代码,本质上是因为 SQL/ 存储过程表达能力弱,无法用简单的方式表达动态层级维度。
2. 工作量大
既然难以简化,就只能老老实实依次写出叉乘语句,但实际业务采用了 3 个维度,每个维度多达 5 层,这样每个运算会由 125 个子查询构成!SQL 本身又很难调试,结果项目组用了 4 个人月才实现数据准备的算法!
而类似的算法有 300 多个!
3. 性能差
在 SQL 语句中,每层个子查询都是个隐藏的临时表,都要耗费一定的时间,而本算法有上千个子查询,每次都要重复遍历,一次算法跑完要 30 多分钟,难以接受。
4. 难以维护
该算法最终要交给集团下属软件公司去维护,但该算法代码太长太复杂,多个维护人员都表示无法顺利解读,将来的维护隐患极大。
5. 难以优化
可以看到,本算法的每种叉乘,都是对原始表进行计算的,原始表数据量较大,性能自然比较差。事实上计算时间第 3 层 + 物料第 3 层时,完全可以在中间层(时间第 3 层 + 物料第 2 层)的基础上计算,而中间层数据已经过汇总,数据量比原始表小得多,性能也可以大幅优化。
但使用 SQL/ 存储过程时,却很难这样优化,这是因为优化就意味着用工作量换执行效率,而原本算法的工作量已经很大了,项目组没有精力再花几倍的时间去优化。
解决方案
最终,这个问题采用开源集算器 SPL 得到了解决。SPL 提供了针对不确定层级叉乘的简单表达方法,使用对象属性化的方式可以引用各个层级的数据。
SPL 算法
SPL 只需 12 行即可实现本算法: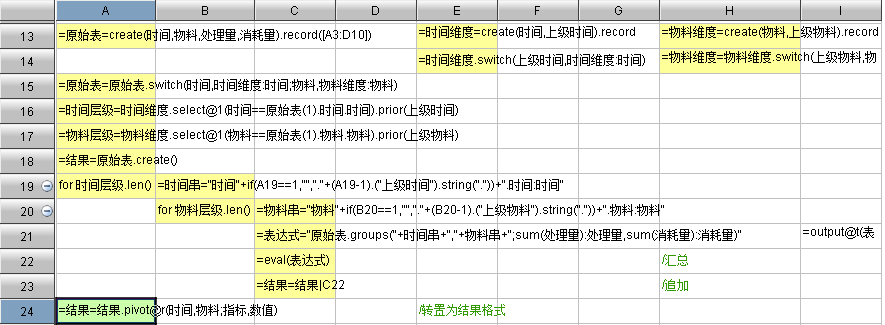
可以看到,SPL 支持对象方式访问关联表,时间第 2 层可表示为“时间维度. 上级时间. 时间”,第 3 层可以表示为“时间维度. 上级时间. 上级时间. 时间”,这就很容易用循环语句拼出表达式,最复杂的表达式不过如此:
原始表.groups(时间. 上级时间. 上级时间. 时间: 时间, 物料. 上级物料. 上级物料. 上级物料. 物料: 物料;sum( 处理量): 处理量,sum(消耗量): 消耗量 )
代码很精简。
而且,SPL 支持动态生成语句,可以在循环中生成代码来执行,多个维度多个层级只要一套循环语句就全部搞定。
SPL 还很方便调试,开发该算法只花了 1 天。
除此之外,该算法还可进一步优化,在中间层的基础上再计算,而不是每次都用原始表,如下:
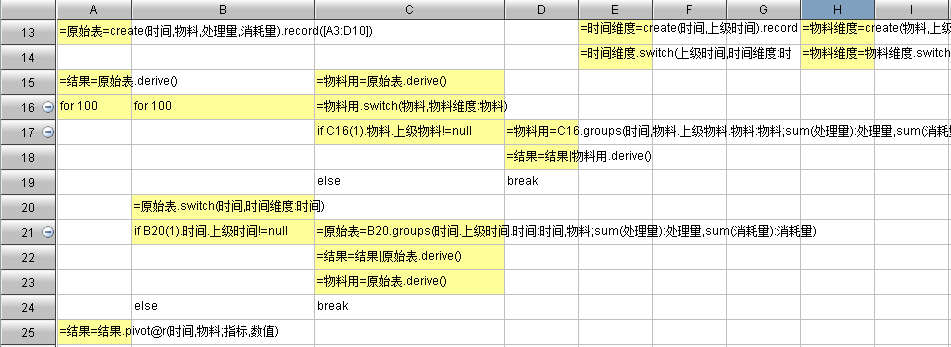
运算时间最后被优化成 40 秒,提高了 45 倍之多。
方案效果
采用 SPL 以后,无论从编码效率还是可维护性等方面都获得了非常大的提升。这里对比一下效果:
指标 |
存储过程 |
SPL |
提升 |
代码量 |
1212 行 |
12 行 |
100 倍 |
工作量 |
120 人天 |
1 人天 |
120倍 |
执行性能 |
1800 秒 |
40 秒 |
45 倍 |
可维护性 |
无 |
容易 |
质变 |
可优化性 |
无 |
容易 |
质变 |
代码量少,编码效率就高这里我们看到获得了120 倍的提升;同时可维护性变得极强。
总结
在成熟报表工具的支持下,报表格式开发的工作量已经不大,工作量已经从呈现阶段转到数据准备阶段了,这部分开发量占比远远大于报表布局那些事。而目前大多数报表工具都没有这种能力,大家只能采用原始硬编码的方式实现,开发效率非常低下。
SPL 的出现很好地解决了这个问题。SPL 提供了丰富的计算类库可以满足各类复杂计算的需要,过程化脚本编辑使得算法实现也更简单,从而进一步提升报表开发效率。
在本例中,SPL 提供的外键指针式关联方式以可以很好处理自关联运算,动态表达式又可以应付任意复杂的表达式拼接,这两个能力是解决问题的关键。
对 SPL 感兴趣可以参考 敏捷数据计算引擎,在《SPL COOK》中有大量 SPL 敏捷计算的例子。
其它相关案例:
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

