


Python 如何处理大文件
Python作为一门程序设计语言,在易读、易维护方面有独特优势,越来越多的人使用 Python 进行数据分析和处理,而 Pandas 正是为了解决数据分析任务而创建的,其包含大量能便捷处理数据的函数和方法,使得数据处理变得容易,它也是使 Python 成为强大而高效的数据分析环境的重要因素之一。
但是 Pandas 是个内存的类库,用于处理小数据(能放入内存)没问题,对于大数据(内存放不下)就没有那么方便了。而我们平时工作中却能经常碰到这种较大的文件(从数据库或网站下载出来的数据),Pandas 无能为力,我们就只能自己想办法,本文就来讨论这个问题。
本文所说的大数据,并不是那种 TB、PB 级别的需要分布式处理的大数据,而是指普通 PC 机内存放不下,但可以存在硬盘内的 GB 级别的文件数据,这也是很常见的情况。
由于此类文件不可以一次性读入内存,所以在数据处理的时候,通常需要采用逐行或者分块读取的方式进行处理,虽然 Python 和 pandas 在读取文件时支持这种方式,但因为没有游标系统,使得一些函数和方法需要分段使用或者函数和方法本身都需要自己写代码来完成,下面我们就最常见的几类问题来进行介绍,并写出代码示例供读者参考和感受。
一、 聚合
简单聚合只要遍历一遍数据,按照聚合目标将聚合列计算一遍即可。如:求和(sum),遍历数据时对读取的数据进行累加;计数(count),遍历数据时,记录遍历数即可;平均(mean),遍历时同时记录累计和和遍历数,最后相除即可。这里以求和问题为例进行介绍。
设有如下文件,数据片段如下:

现在需要计算销售总额(amount 列)
(一)逐行读取
total=0 with open("orders.txt",'r') as f: line=f.readline() while True: line = f.readline() if not line: break total += float(line.split("\t")[4]) print(total) |
打开文件 标题行
逐行读入 读不到内容时结束
累加 |
(二)pandas分块读取
使用 pandas 可以分块读取了,工作逻辑结构如下图:
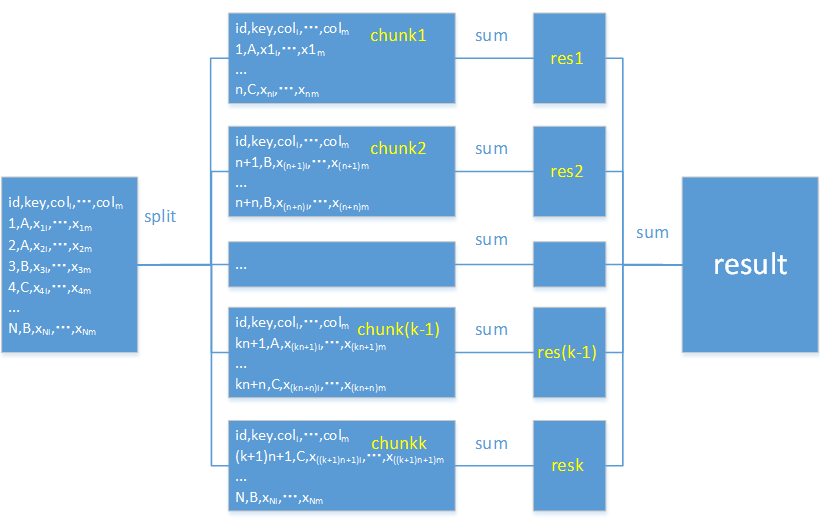
import pandas as pd chunk_data = pd.read_csv("orders.txt",sep="\t",chunksize=100000) total=0 for chunk in chunk_data: total+=chunk['amount'].sum() print(total) |
分段读取文件,每段 10 万行
累加各段的销售额
|
pandas更擅长以大段读取的方式进行计算,理论上 chunksize 越大,计算速度越快,但要注意内存的限制。如果 chunksize 设置成 1,就成了逐行读取,速度会非常非常慢,因此不建议使用 pandas 逐行读取文件来完成此类任务。
二、 过滤
过滤流程图:
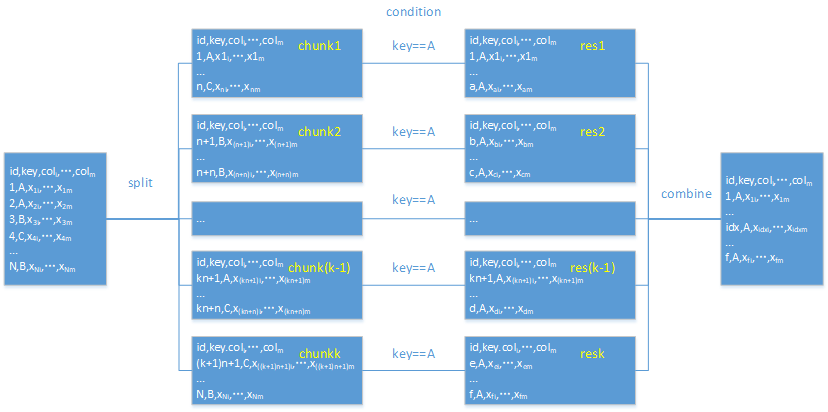
过滤和聚合差不多,将大文件分成 n 段,对各段进行过滤,最后将每一段的结果进行合并即可。
继续以上面数据为例,过滤出纽约州的销售信息
(一)小结果集
import pandas as pd chunk_data = pd.read_csv("orders.txt",sep="\t",chunksize=100000) chunk_list = []
for chunk in chunk_data: chunk_list.append(chunk[chunk.state=="New York"]) res = pd.concat(chunk_list) print(res) |
定义空列表存放结果
分段过滤
合并结果 |
(二)大结果集
import pandas as pd chunk_data = pd.read_csv("orders.txt",sep="\t",chunksize=100000) n=0 for chunk in chunk_data: need_data = chunk[chunk.state=='New York'] if n == 0: need_data.to_csv("orders_filter.txt",index=None) n+=1 else: need_data.to_csv("orders_filter.txt",index=None,mode='a',header=None) |
第一段,写入文件,保留表头,不保留索引
其他段,追加写入不保留表头和索引 |
大文件聚合和过滤运算的逻辑相对简单,但因为 Python 没有直接提供游标数据类型,代码也要写很多行。
三、 排序
排序流程图:
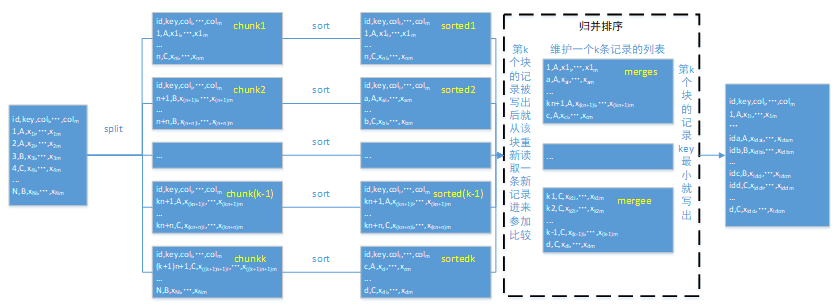
排序要麻烦得多,如上图所示:
1. 分段读取数据;
2. 对每一段进行排序;
3. 将每一段的排序结果写出至临时文件;
4. 维护一个 k 个元素的列表(k 等于分段数),每个临时文件将一行数据放入该列表;
5. 将列表中的记录的按排序的字段的排序 (与第二步的排序方式相同,升序都升序,降序都降序);
6. 将列表的最小或最大记录写出至结果文件 (升序时最小,降序时最大);
7. 从写出记录的临时文件中再读取一行放入列表;
8. 重复 6.7 步,直至所有记录写出至结果文件。
继续以上面数据为例,用 Python 写一段完整的外存排序算法,将文件中的数据按订单金额升序排序
import pandas as pd import os import time import shutil import uuid import traceback
def parse_type(s): if s.isdigit(): return int(s) try: res = float(s) return res except: return s
def pos_by(by,head,sep): by_num = 0 for col in head.split(sep): if col.strip()==by: break else: by_num+=1 return by_num
def merge_sort(directory,ofile,by,ascending=True,sep=","):
with open(ofile,'w') as outfile:
file_list = os.listdir(directory)
file_chunk = [open(directory+"/"+file,'r') for file in file_list] k_row = [file_chunk[i].readline()for i in range(len(file_chunk))] by = pos_by(by,k_row[0],sep)
outfile.write(k_row[0]) k_row = [file_chunk[i].readline()for i in range(len(file_chunk))] k_by = [parse_type(k_row[i].split(sep)[by].strip())for i in range(len(file_chunk))]
with open(ofile,'a') as outfile:
while True: for i in range(len(k_by)): if i >= len(k_by): break
sorted_k_by = sorted(k_by) if ascending else sorted(k_by,reverse=True) if k_by[i] == sorted_k_by[0]: outfile.write(k_row[i]) k_row[i] = file_chunk[i].readline() if not k_row[i]: file_chunk[i].close() del(file_chunk[i]) del(k_row[i]) del(k_by[i]) else: k_by[i] = parse_type(k_row[i].split(sep)[by].strip()) if len(k_by)==0: break
def external_sort(file_path,by,ofile,tmp_dir,ascending=True,chunksize=50000,sep=',',usecols=None,index_col=None): os.makedirs(tmp_dir,exist_ok=True)
try: data_chunk = pd.read_csv(file_path,sep=sep,usecols=usecols,index_col=index_col,chunksize=chunksize) for chunk in data_chunk: chunk = chunk.sort_values(by,ascending=ascending) chunk.to_csv(tmp_dir+"/"+"chunk"+str(int(time.time()*10**7))+str(uuid.uuid4())+".csv",index=None,sep=sep) merge_sort(tmp_dir,ofile=ofile,by=by,ascending=ascending,sep=sep) except Exception: print(traceback.format_exc()) finally: shutil.rmtree(tmp_dir, ignore_errors=True)
if __name__ == "__main__": infile = "D:/python_question_data/orders.txt" ofile = "D:/python_question_data/extra_sort_res_py.txt" tmp = "D:/python_question_data/tmp" external_sort(infile,'amount',ofile,tmp,ascending=True,chunksize=1000000,sep='\t') |
函数 解析字符串的数据类型
函数 计算要排序的列名在表头中的位置
函数 外存归并排序
列出临时文件
打开临时文件
读取表头
计算要排序的列在表头的位置 写出表头 读取正文第一行
维护一个 k 个元素的列表,存放 k 个排序列值
排序,维护的列表升序正向,降序反向 写出最小值对应的行 读完一个文件处理一个
如果文件没读完 更新维护的列表循环计算 所有文件读完结束
函数 外存排序
创建临时文件目录
分段读取需排序的文件
分段排序
写出排好序的文件
外存归并排序
删除临时目录
主程序
调用外存排序函数
|
这里是用逐行归并写出的方式完成外存排序的,由于 pandas 逐行读取的方式效率非常低,所以没有借助 pandas 完成逐行归并排序。读者感兴趣的话可以尝试使用 pandas 按块归并,比较下两者的效率。
相比于聚合和过滤,这个代码相当复杂了,对于很多非专业程序员来讲已经是不太可能实现的任务了,而且它的运算效率也不高。
以上代码也仅处理了规范的结构化文件和单列排序。如果文件结构不规范比如不带表头、各行的分隔符数量不同、排序列是不规范的日期格式或者按照多列排序等等情况,代码还会进一步复杂化。
四、 分组
大文件的分组汇总也很麻烦,一个容易想到的办法是先将文件按分组列排序,然后再遍历有序文件,如果分组列值和前一行相同则汇总在同一组内,和前一行不同则新建一组继续汇总。如果结果集过大,还要看情况把计算好的分组结果及时写出。
这个算法相对简单,但性能很差,需要经过大排序的过程。一般数据库会使用 Hash 分组的方案,能够有效地提高速度,但代码复杂度要高出几倍。普通非专业人员基本上没有可能写出来了。这里也就不再列出代码了。
通过以上介绍,我们知道,Python 处理大文件还是非常费劲的,这主要是因为它没有提供为大数据服务的游标类型及相关运算,只能自己写代码,不仅繁琐而且运算效率低。
Python不方便,那么还有什么工具适合非专业程序员来处理大文件呢?
esProc SPL在这方面要要比 Python 方便得多,SPL 是专业的结构化数据处理语言,提供了比 pandas 更丰富的运算,内置有游标数据类型,解决大文件的运算就非常简单。比如上面这些例子都可以很容易完成。
一、 聚合
A |
|
1 |
=file(file_path).cursor@tc() |
2 |
=A1.total(sum(col)) |
二、 过滤
A |
B |
|
1 |
=file(file_path).cursor@tc() |
|
2 |
=A1.select(key==condition) |
|
3 |
=A2.fetch() |
/小结果集直接读出 |
4 |
=file(out_file).export@tc(A2) |
/大结果集可写入文件 |
三、 排序
A |
|
1 |
=file(file_path).cursor@tc() |
2 |
=A1.sortx(key) |
3 |
=file(out_file).export@tc(A2) |
四、 分组
A |
B |
|
1 |
=file(file_path).cursor@tc() |
|
2 |
=A1.groups(key;sum(coli):total) |
/小结果集直接返回 |
3 |
=A1.groupx(key;sum(coli):total) |
|
4 |
=file(out_file).export@tc(A3) |
/大结果集写入文件 |
特别指出,SPL 的分组汇总就是采用前面说过的数据库中常用的 HASH 算法,效率很高。
SPL中还内置了并行计算,现在多核 CPU 很常见,使用并行计算可以大幅度提高性能,比如分组汇总,只多加一个 @m 就可以变成并行计算。
A |
|
1 |
=file(file_path).cursor@mtc() |
2 |
=A1.groups(key;sum(coli):total) |
而 Python 写并行计算的程序就太困难了,网上说啥的都有,就是找不到一个简单的办法。

