


SPL:调用 Python 程序
【摘要】
集算器 SPL 集成了对 python 程序的调用,也提供对建模算法接口支持。具体开发要求、使用详细情况,请前往乾学院:SPL:调用 Python 程序!
集算器是强大的数据计算引擎,但目前对于机器学习算法的提供还不够丰富。而 python 中有许多此类算法。借助 YM 外部库,就可以让集算器 SPL 调用 python 写的代码,从而弥补这一不足。
下面具体说明:
1.SPL 与 python 环境配置2.python 模块开发规范要求
3.ym_exec 接口调用
4.建模算法模块使用
SPL、python、接口关系示意图:

SPL 中调用 ym_exec 接口,将参数传递给 python 下的 apply() 接口,apply 调用 python 程序处理后返回结果给 SPL。
1. SPL 与 python 环境配置
为了 SPL 与 python 之间能通信,实现相互访问,需要进行有关的设置。
下面以在 win10 下,python3.9+SPL 为例来说明如何设置的。
本接口依赖集算器 SPL 外部库 Ymodel。 Ymodel 与 python 通过 userconfig.xml 关联。
A、安装 Python 软件:
下载 python3 软件安装包,安装位置如 c:\Program Files\raqsoft\ymodel\Python39。
B:外部库安装:
参考集算器连接外部库,在集算器的外部库设置中勾选 Ymodel 项让其生效。( 通过建模下载能找到 Ymodel jar 依赖包 )
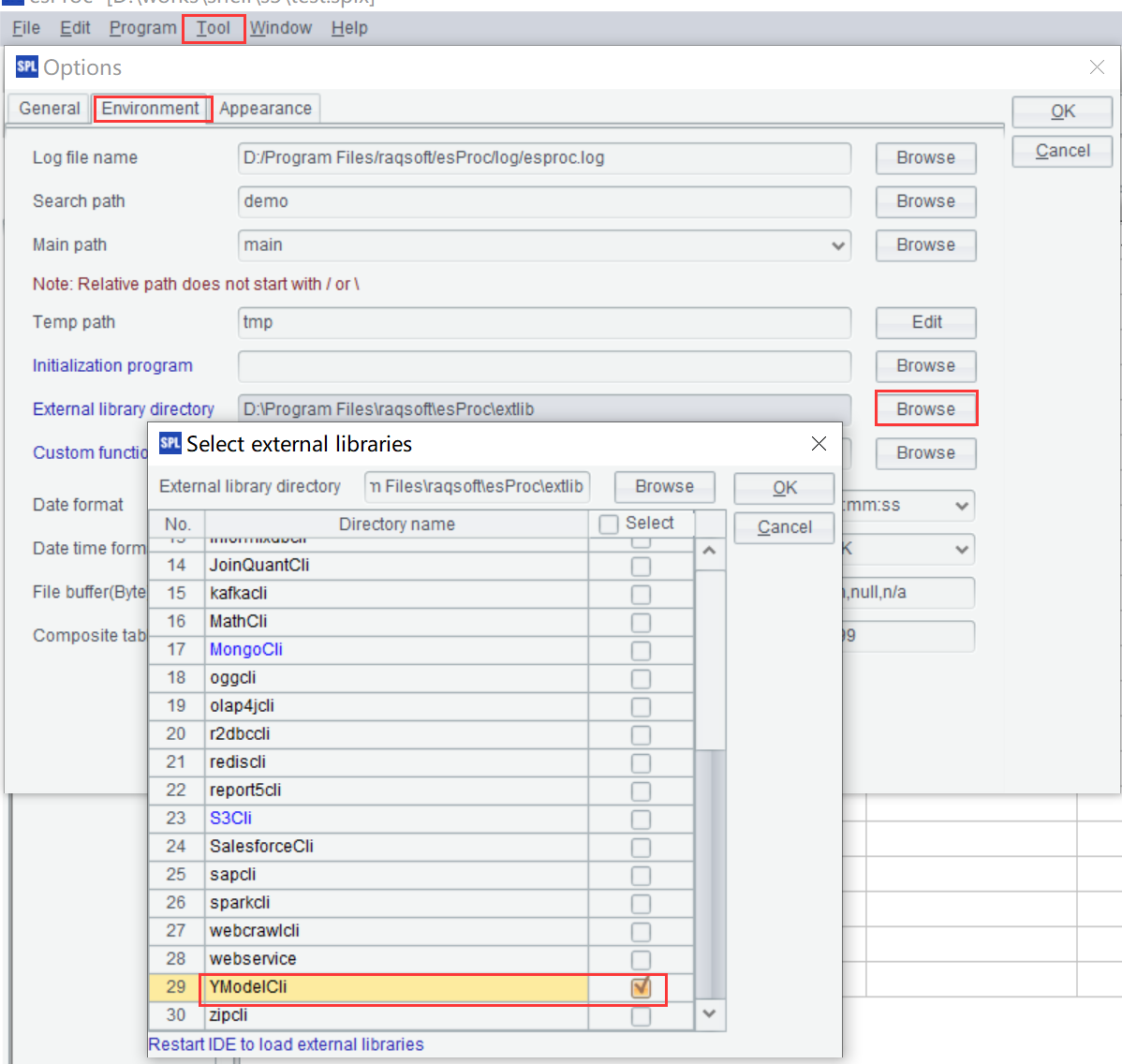
C、 配置文件: 在外部库目录 esProc\extlib\ymodel\userconfig.xml 文件中设置参数,参数如下:
| 选项 | 名称 | 说明 |
| sAppHome | C:\Program Files\raqsoft\ymodel | 应用程序目录 |
| sPythonHome | c:\Program Files\raqsoft\ymodel\ Python39\python.exe |
Python文件 |
| sPythonHost | localhost | 网络 IP |
| iPythonScriptPort | 8512 | 网络端口 |
D、服务端程序应用程序指提供的 python 服务端程序:
以上配置完成之后,重启集算器后就可以使用 ym_exec() 接口。
2. python 模块开发规范要求
A、def apply(ls) 接口,python 程序的对外接口,实现与 SPL 交互处理。
B、参数 ls 为 list 数据类型,它类似于 java 中的入口函数 void main(string argv[]) 中的 argv 参数。
C、返回值,返回 dataframe 结构数据存放在 list 类型的变量中, 可在 SPL 中显示。
D、样例说明:demo.py
import pandas as pd
import sys
def apply(lists):
cols = [<em>"value"</em>]
ls = []
for x in lists:
ls.append("{}".format(x))
df = pd.DataFrame(ls, columns=cols)
lls=[]
lls.append(df)
return lls
if __name__ == "__main__":
res = apply(sys.argv[1:])
print('res={}'.format(res))
运行:python demo.py “AAA” “BBB” 1000
输出:res=[ value
0 AA
1 BBB
2 1000]
本程序 apply()接口,实现将传递的参数加入到变量列表 ls 中,然后 ls 放入 dataframe 结构里,dataframe 再放入要返回的变量列表 lls 里。开发中,先在 python 下测试 apply() 接口正常后,就可以在 SPL 中调用了。
需要注意的是,由于 dataframe 是通过 msgpack 编码后返回的数据,因此要求 dataframe 中同一列的数据类型一致,否则 msgpack 编码时出错,SPL 中收不到 dataframe 数据.
3.ym_exec 接口调用
格式:ym_exec(pyfile, p1,p2,…)。
调用pyfile文件并运行它,后面跟传入的参数 p1,p2 等。参数个数不定, 只要与接口 apply() 对应。
| A | |
| 1 | =ym_env() |
| 2 | =ym_exec("d:/demo.py", false, 12345, 10737418240, 123.45, decimal(1234567890123456), "aaa 123") |
| 3 | >ym_close(A1) |
| value | |
| 1 | False |
| 2 | 12345 |
| 3 | 10737418240 |
| 4 | 123.45 |
| 5 | 1234567890123456 |
| 6 | aaa 123 |
4. 建模算法模块使用
下面再演示一下如何在集算器调用 python 实现偏最小二乘算法(PLS,目前集算器本身未提供)。在运行它之前,需要安装易明建模库,配置设置参考《SPL实现自动建模和预测》。
由于 PLS 算法的参数较为复杂,我们将调用格式约定为:
ym_exec(pyfile, data, jsonstr)
SPL中调用pyfile文件并运行它,data 为需要建模的数据(序表),将 PLS 算法众多参数写成 json 串。同样地,需要与 pyfile 中 apply() 处理对应起来,才能正确解析各参数值。
data:data为预表或带头文件的数据文件名。数据中包括目标变量 target 所在的列。
jsonstr: json字符串,例如:
{target:0,n_components:3,deflation_mode:'regression',
mode:'A',norm_y_weights:False,
scale:False,algorithm:'nipals',
max_iter:500,tol:0.000001,copy:True}
其中 target 指定目标变量所在的列,不可缺少。
SPL脚本pls_demo.splx:
| A | B | |
| 1 | =ym_env() | |
| 2 | ="d:/script/pls_demo.py" | |
| 3 | =file("d:/script/data_test.csv").import@cqt() | // 数据 |
| 4 | {target:0,n_components:3,deflation_mode:'regression', mode:'A',norm_y_weights:False} | // 首列为目标变量, 使用 json 字符串为参数 |
| 5 | =ym_exec(A2, A3, A4) | |
| 6 | >ym_close(A2) |
首行为target的数据data_test.csv:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 181.6 | -0.00182 | -0.00796 | -0.00748 | -0.00286 | 0.004846 | 0.016245 | 0.028104 | 0.039865 |
| 154.5 | -0.00102 | -0.00789 | -0.00795 | -0.00361 | 0.003765 | 0.015062 | 0.028321 | 0.041063 |
| 195 | 0.001206 | -0.00464 | -0.00374 | 0.000681 | 0.008794 | 0.020834 | 0.036321 | 0.051656 |
| 150.8 | -0.00154 | -0.00802 | -0.00768 | -0.0028 | 0.00624 | 0.01712 | 0.03772 | 0.043453 |
| … |
pls_demo.py文件,针对python模块算法使用参考
from scipy.linalg import pinv2
import numpy as np
import pandas as pd
import demjson
#算法类pls_demo:
class pls_demo():
. . . . . . .
Pass
#接口实现
def apply(lists):
if len(lists)<2:
return None
data = lists[0] #数据参数
val = lists[1] #jsonstr串参数
if (type(data).name=="str"):
data = pd.read_csv(data)
#1. 对json字符串中特定值处理
#print(val)
val = val.lower().replace("false", "'False'")
val = val.replace("true", "'True'")
val = val.replace("none", "'None'")
dic = demjson.decode(val)
if dic.contains('target') ==False:
print("param target is not set")
return
#2. 对target参数的处理,它可能为列数,也可能为名称
targ = dic['target']
if type(targ).__name__ == "int":
col = data.columns
colname = col.tolist()[targ]
else:
colname = targ
Y = data[colname]
X = data.drop(colname, axis=1)
#3.模型参数处理,没有传递的参数需要设定缺省值.
if dic.contains('n_components') :n_components=dic['n_components']
else: n_components=15
if dic.contains('deflation_mode'):deflation_mode=dic['deflation_mode']
else: deflation_mode="regression"
if dic.contains('mode'):mode=dic['mode']
else: mode="A"
…….
#4.模型算法加载
#print("n_components={}".format( n_components))
pls_model = pls_demo(n_components,
deflation_mode,
mode,…)
# 训练数据
pls_model.fit(X, Y)
# 预测
y_pred = pls_model.predict(X)
#5. 填充返回值
f = ["value"]
df = pd.DataFrame(y_pred, columns=f)
#print(y_pred)
lls=[]
lls.append(df)
return lls
#6. 测试
if __name__ == '__main__':
ls = []<br>
ls.append("a2ef764c53ec1fbc_X.new.csv")<br>
val = "{target:0,n_components:3,deflation_mode:'regression'," \
" mode:'a',norm_y_weights:False," \
" scale:False,algorithm:'nipals'," \
" max_iter:500,tol:0.000001,copy:True}"
ls.append(val)
apply(ls)
开发过程中,先在 python 下通过 main 函数测试 apply() 接口正常后,就可以在 SPL 中调用了。


英文版