


10 行代码解决漏斗转换计算之性能优化
【摘要】
庖丁解牛,给人的深刻印象是技艺酷炫!然而酷炫并非是庖丁的原意追求。本质上是对一个复杂的结构进行大量练习后,把细节融入了自己的身体,成为一种本能;流畅自然的动作给观赏者造成酷炫的感受,是一个副产品。
数据处理的描述计算、性能优化也是类似的事情。成为数据界的庖丁同样需要两个必要条件:1、大量待解的牛 (复杂的需求和运行环境); 2、专业的解牛刀具 ( 是集算器的 SPL 语言吗?!)。让我们一起去乾学院看个究竟吧:10 行代码解决漏斗转换计算之性能优化!
大话数据计算性能优化
大数据分析的性能优化,说道底,就优化一个事情:针对确定的一个计算任务(数据确定,结果确定),以最经济的方案得到结果。
这个最经济的方案主要考量三个成本:时间成本、硬件成本、软件成本。
- 时间成本:根据计算任务的特点,能容忍的最长时间各不相同。那些 T+0 的计算任务,实时性要求就比较高,T+1 再算出结果就失去了意义。
- 硬件成本:可以使用的硬件资源,对一个公司来说一般不是经常变化的,机器配置、可集群数量就那么多。即便使用云计算产品,也只是多了扩容的灵活性,成本是少不掉的。
- 软件成本:编写出这个计算算法的人工费 + 软件环境的成本。这个成本也与前两项相关,程序控制力度粗犷一些,实现逻辑简单一些,程序就容易编写,那软件成本就会低一些,带来的副作用是运行时间超长或者需要昂贵的硬件。
这三个因素里面,一般对于计算任务来说,自然是越快越好,当然只要不慢过能容忍的时长,也就还算是有意义的计算;而硬件因素的弹性就比较小,有多少资源是相对固定的;所以,剩下的可以大做文章的就是软件成本了。软件成本里,程序员的工资是很重要的一项,而有没有顺手的软件环境让程序员能高效的把计算描述出来,就成了关键。最典型的例子就是理论上用汇编程序能写出所有的程序,但它明显不如 SQL 或 JAVA 做个常规计算来的容易。
说到 SQL 和 JAVA,成规模的计算中心的一些维护者估计也会皱眉,使用它们的时间越长,越能体会需求变动或优化算法过程中的痛苦,明明算法过程自己想的很清楚了,但编写成可运行的程序就困难重重。这些困难主要来自两个方面:
- 首先,一些基础的数据操作方法是自己逐渐积累的,没有经过整体的优化设计,这些个人工具对个人的开发效率有不错的提升,但没法通用,也不全面,这个困难主要表现在用 JAVA 等高级语言实现的一些 UDF 上。
- 第二,主要是思维方式上的,在生产场景下用习惯了 SQL 查询,在计算场景下遇到的性能问题自然而然就想通过优化 SQL 语句的方式把问题缓解掉。但实际上这可能是个温水煮青蛙的过程。越深入搞,把简单的过程问题越可能搞成庞大不可拆分的逻辑块,到最后只有原创作者或高手才敢碰它。我这个老程序员,十多年前刚入行的时候,八卦中耳闻过 ORACLE 的系统管理员,尤其是有性能优化能力的,比普通程序员贵多了,可见这个难题在数据规模相对较小的十年前已经凸显了。
(注:生产场景和计算场景在初始阶段的软件系统里一般很难截然分开,数据都是从生产场景积累起来的,等积累多了,慢慢会增加计算需求,逐渐独立出计算中心和数据仓库。这个量变引起质变的过程,如果不在思维上转变,不引入新办法,那就将成为被煮的青蛙。)
为了节省读者的时间,我们先把性能优化的常用手段总结一下,方便有需求的用户逐条对比进行实际操作。
1、 只加载计算相关数据。
- 列存方式存储数据;
- 常用的字段和不常用的分开存储;
- 用独立的维表存储维的属性,减少事实表的信息冗余;
- 按照某些常用作查询条件的字段分开存储,如按年份、性别、地区等独立存储;
2、 精简计算涉及到的数据
- 用来分析时,一些冗长的编号,可以序号化处理,用 1、2、……替代 TJ001235-078、 TJ001235-079、……,这样即能加快加载数据的速度,又能加快计算速度。
- 日期时间,如果用字符串类型按照我们熟悉的格式 (2011-03-08) 存储,那加载和计算都会慢。前面这个日期可以存储成 110308 这样的数值类型,也可以存储成相对于一个开始时间的毫秒数(如相对于最早的数据 2010-01-01 的毫秒数)。
3、 算法的优化
- 计算量小的条件写在前面,如 boolean 类型的判断,要早于字符串查找,这样用较少的计算就能排除掉不符合要求的数据;
- 减少对大事实表的遍历次数。具体方法有:在一次遍历过程中,同时给多个独立的运算操作提供数据(后面会提到的集算器里的管道概念),而不是每个运算操作遍历一次数据;做 JOIN 时,在内存里的维表里检索事实表数据,而不是用每条维表数据去遍历一次事实表。
- 查找时借用 HASH 索引、二分法、序号直接对位等方式加快速度。
4、 并行计算
- 加载数据和计算两个步骤都可以并行。考量计算特点,根据加载数据和运算哪个量更大来判断瓶颈是计算机的磁盘还是 CPU,磁盘阵列适合并行加载数据,多核 CPU 适合并行运算。
- 多机集群的并行任务,要考虑主程序和子程序的通讯问题,尽量把复杂计算独立到节点机上完成,网络传输较慢,要减少节点机之间的数据交换。
实操效果
兵马未动粮草先行,有了上面这些指导思想,我们下面就切入正题实现漏斗计算的优化,看一下实际的优化效果。
1、未做任何优化,直接开工
数据:
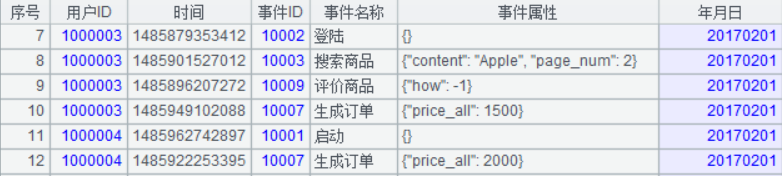
程序:(附件中的 1-First.splx,也附带了测试数据文件,可在集算器里直接执行)
漏斗转换计算核心代码的逻辑细节在上一篇中详细介绍过,这里就不再赘述。
结果:(注:之后的测试都以 118 万条数据为基础,成倍增加)
118 万条记录 /70MB/ 用户数量 8000/31 秒;
590 万条记录 /350MB/ 用户数量 4 万 /787 秒。
分析:
数据量增加到 5 倍,但耗时增加到了 26 倍,性能下降得厉害,而且不是线性的。原因是被分析的用户列表扩大了 5 倍,同时被分析的记录数也扩大 5 倍,那检索用户次数理论上就扩大了 5*5 倍。接下来采用以下优化方式↓
2、按用户 ID 顺序插入用户列表,用二分法查找用户。
程序:(2-BinarySearch.splx)
B12 给 find 增加 @b 选项,指明用二分法查找;D13 中却去掉 insert 的第一个位置参数 0 后,新用户就不直接追加到最后了,而是按主键顺序插入。
A |
B |
C |
D |
|
11 |
…… |
|||
12 |
for A11 |
>user=A10.find@b(A12.用户 ID) |
||
13 |
if user==null |
if A12.事件 ID==events(1) |
>A10.insert(,A12.用户 ID: 用户 ID,1:maxLen,[[A12. 时间,1]]:seqs) |
|
14 |
…… |
结果:
118 万条记录 /70MB/ 用户数量 8000/10 秒;
590 万条记录 /350MB/ 用户数量 4 万 /47 秒。
分析:
优化后,1 倍的数据量耗时缩减到 1/3;5 倍的数据量提速比较明显,缩减到 1/16。进一步观察,5 倍数据量是 350MB,从硬盘载入数据的速度慢点算也会有 100M/ 秒,假如 CPU 够快的话,极限速度应该能到 4 秒左右,而现在的 47 秒证明 CPU 耗时还比较严重,根据经验可以继续优化↓
3、批量读入游标数据
程序:(3-BatchReadFromCursor.splx)
12~17 行整体剪切后,向右移一个格子之后,在 A12 增加一个批量加载游标数据的循环,表示 A11 中的游标每次取 10000 条,B12 再对取出来的这 10000 条数据循环处理。
A |
B |
C |
|
11 |
…… |
||
12 |
for A11,10000 |
for A12 |
…… |
13 |
…… |
结果:
118 万条记录 /70MB/ 用户数量 8000/4 秒;
590 万条记录 /350MB/ 用户数量 4 万 /10 秒;
5900 万条记录 /3.5GB/ 用户数量 40 万 /132 秒;
11800 万条记录 /7GB/ 用户数量 80 万 /327 秒。
分析:
优化后,1 倍数据量耗时缩减到 2/5;5 倍的数据量缩减到 1/5;新测试的 50 倍、100 倍性能也大体随数据量保持了线性。注意到原始数据有一些字段用不到,用到的字段也可以通过序号化等手段再简化,简化后的文件会小几倍,从而达到从硬盘减少读取时间的目的,具体优化方式如下↓
4、精简数据
思路:
先观察一下原始数据:用户 ID 用从 1 开始的序号替代,除了减少少许存储空间外,还可以在后续计算时通过序号快速定位到用户,减少查找时间。时间和年月日字段信息重复,去掉年月日,长整型的时间字段也可以进一步精简成相对 2017-01-01 这个开始时间的毫秒数;事前我们知道只有 10 种事件,那事件 ID 和事件名称可以单独提取出个维表记录,这个事实表里只保存序号化的事件 ID(1、2、3…10)就够了;事件属性是 JSON 格式,种类不多,那对于某一种事件,可以用序列存储事件属性的值,在序列中的位置表示某种属性,这样即缩减存储空间,又能提升查找属性的效率。
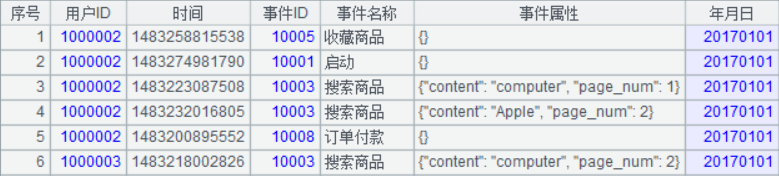
除了上面这些字段值的精简,我们存储数据的格式弃用文本方式,改变成集算器二进制格式,存储空间更小,加载速度更快,精简后的事实表如下:

实现:
精简事实表数据之前,要先通过事实表生成用户表、事件表两个维表的(genDims.splx,运行后生成 user.bin 和 event.bin):
A |
|
1 |
>beginTime=now() |
2 |
>fPath="e:/ldsj/demo/" |
3 |
=file(fPath+"src-11800.txt").cursor@t() |
4 |
=channel(A3) |
5 |
=A4.groups(#1:用户 id) |
6 |
=A3.groups(#3:事件 ID,#4: 事件名称; iterate(~~.import@j().fname()): 属性名称) |
7 |
=file(fPath+"event.bin").export@b(A6) |
8 |
=file(fPath+"user.bin").export@b(A4.result()) |
9 |
=interval@s(beginTime,now()) |
提取维表的这段程序,仍然有优化的手段体现。提取两个维表,常规思维是每遍历一遍数据,生成一个维表;从硬盘读入大量数据进行遍历,读入慢,但读入后的计算量却非常小。针对这种情况,那有什么手段可以在读入数据时,同时用于多种独立的计算呢,答案就是“管道”,多定义了几个管道,就多定义了几种运算。A4 针对 A3 游标定义管道,A5 定义 A4 管道的分组计算,A6 定义另外一个分组计算,A7 导出 A6 的结果,A8 导出 A4 管道的结果。最终得到的两个维表如下:
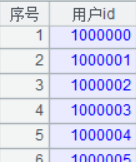
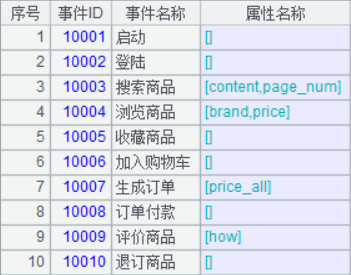
基于上面两个维表对事实表进行精简(toSeq.splx),6.8G 的文本文件精简后,得到 1.9G 的二进制文件,缩小了 3.5 倍。
A |
B |
C |
D |
|
1 |
>beginTime=now() |
|||
2 |
>fPath="e:/ldsj/demo/" |
|||
3 |
=file(fPath+"src-11800.txt").cursor@t() |
|||
4 |
=file(fPath+"event.bin").import@b() |
=A4.(事件 ID) |
=A4.(属性名称 ) |
|
5 |
=file(fPath+"user.bin").import@b() |
=A5.(用户 ID) |
||
6 |
||||
7 |
func |
|||
8 |
=A7.import@j() |
|||
9 |
=[] |
|||
10 |
for B7 |
|||
11 |
>B9.insert(0,eval("B8."+B10)) |
|||
12 |
return B9 |
|||
13 |
||||
14 |
for A3,10000 |
|||
15 |
=A14.new(C5.pos@b(用户 ID): 用户 ID,C4.pos@b( 事件 ID): 事件 ID, 时间: 时间,func(A7, 事件属性,D4(C4.pos@b( 事件 ID))): 事件属性 ) |
|||
16 |
=file(fPath+"src-11800.bin").export@ab(B15) |
|||
17 |
=interval@s(beginTime,now()) |
这段代码出现了一个新的知识点,第 7~12 行定义了一个函数来处理 json 格式的事件属性,B15 里精简每一行数据时,调用了这个函数。B16 把每次精简好的一万条记录追写入同一个二进制文件。
程序:(4-Reduced.splx)
在上一次程序的基础上改造了这么几个格子:
A3/A4 中的时间相对于 2017-01-01;
A6 事件序列改用序号;
A7 中属性过滤,用精确匹配值的方式替换以前低效的模糊匹配字符串方式; A10 初始化用户序列,长度为用户数,该序列中的位置代表用户的序号;
C12 用序号方式查找用户;
E13 用序号方式存储新用户:
A |
B |
C |
D |
E |
|
2 |
…… |
||||
3 |
>begin=interval@ms(date(2017,1,1),date(2017,1,1)) |
||||
4 |
>end=interval@ms(date(2017,1,1),date(2017,3,1)) |
||||
5 |
>dateWindow=10*24*60*60*1000 |
||||
6 |
>events=[3,4,6,7] |
||||
7 |
>filter="if(事件 ID!=4||(事件属性.len()>0&& 事件属性 (1)==\"Apple\");true)" |
||||
8 |
|||||
9 |
/开始执行漏斗转换计算程序 |
||||
10 |
=to(802060).(null) |
||||
11 |
=file(dataFile).cursor@b().select(时间 >=begin&& 时间 <end && events.pos(事件 ID)>0 && ${filter}) |
||||
12 |
for A11,10000 |
for A12 |
>user=A10(B12.用户 ID) |
||
13 |
if user==null |
if B12.事件 ID==events(1) |
>A10(B12.用户 ID)=[B12. 用户 ID,1,[[B12. 时间,1]]] |
||
14 |
…… |
结果:
11800 万条记录 /1.93GB/ 用户数量 80 万 /225 秒。
分析:
优化后,100 倍数据量耗时缩减到上一步的 2/3。除了精简涉及的查询字段,我们再看看另一种能有效缩减查询数据量的方法↓
5、把数据预先拆分存储,计算的时候只加载涉及到的数据
思路:
如何拆分数据和查询特点有关,这个例子中经常查询不定时间段,那按照日期拆分比较合适,按照事件 ID 拆分就没有意义了。
拆分数据的程序(splitData.splx):
A4 每次取出 10 万条数据;B4 循环 60 天;C6 按照日期查询到数据后,通过 C9 追加到各自日期的文件里。
A |
B |
C |
D |
|
1 |
=dataFile=file("e:/ldsj/demo/src-11800.bin").cursor@b() |
|||
2 |
>destFolder="e:/ldsj/demo/dates/" |
|||
3 |
>oneDay=24*60*60*1000 |
|||
4 |
for A1,100000 |
for 60 |
>begin=long(B4-1)*oneDay |
|
5 |
>end=long((B4))*oneDay |
|||
6 |
=A4.select(时间 >=begin && 时间 <end) |
|||
7 |
if (C6 == null) |
next |
||
8 |
>filename= string(date(long(date(2017,1,1))+begin), "yyyyMMdd")+".bin" |
|||
9 |
=file(destFolder+fileName).export@ab(C6) |
执行后生成 59 天的数据文件:
程序:(5-SplitData.splx)
A2 中把以前被分析的文件定义换成目录;
A3/A4 的起止日期条件有所变动,以前是查询日期字段,现在变成查找日期文件;
A11 把目录下的日期文件排序,选出要分析的多个日期文件,然后组合成一个游标之后再进行事件过滤就可以了。
A |
|
1 |
…… |
2 |
>fPath="e:/ldsj/demo/dates/" |
3 |
>begin="20170201.bin" |
4 |
>end="20170205.bin" |
5 |
…… |
11 |
=directory(fPath+"2017*").sort().select(~>=begin&&~<=end).(file(fPath+~:"UTF-8")).(~.cursor@b()).conjx().select(events.pos(事件 ID)>0 && ${filter}) |
12 |
…… |
结果:
目标数据选择 2017-02-01 至 2017-02-05 这 5 天,全量扫描数据 168 秒;只扫描 5 个文件得到相同结果 7 秒,效果显著。到目前为止,读取数据和计算都是单线程的,下面我们再试试并行计算↓
6、并行计算
单线程加载数据,多线程计算
程序:(6-mulit-calc.splx)
增加 B 列,B2 中启动 4 个线程处理 A12 里加载的 100000 条数据,C12 中依据用户 ID%4 的余数分成 4 组,分别给 4 个线程进行运算。
A |
B |
C |
|
11 |
…… |
||
12 |
for A11,100000 |
fork to(4) |
for A12.select(用户 ID%4==B12-1) |
13 |
…… |
结果:
11800 万条 /1.93GB/ 用户数 80 万 /4 线程 / 一次性读入 10 万条数据 /262 秒;
11800 万条 /1.93GB/ 用户数 80 万 /4 线程 / 一次性读入 40 万条数据 /161 秒;
11800 万条 /1.93GB/ 用户数 80 万 /4 线程 / 一次性读入 80 万条数据 /233 秒;
11800 万条 /1.93GB/ 用户数 80 万 /4 线程 / 一次性读入 400 万条数据 /256 秒。
分析:
笔者测试机器是单个机械硬盘,加载数据速度是瓶颈,所以对提速不太明显。但调整单次加载的数据量,还是会有明显的性能差异。每次处理 40 万条数据时性能最优。
多线程加载数据
预处理:(splitDataByUserId.splx)
虽然 4 个线程可以同时读全量数据的同一个文件,但每个线程读出 3/4 的无用数据必然拖慢速度,所以预先按照用户 ID%4 拆分一下文件能更快些。C3 查询出 ID%4 的数据,C6 把查询的数据存入相应的拆分文件。
A |
B |
C |
D |
|
1 |
=file("e:/ldsj/demo/src-11800.bin").cursor@b() |
|||
2 |
e:/ldsj/demo/users/ |
|||
3 |
for A1,100000 |
for to(4) |
=A3.select(用户 ID%4==B3-1) |
|
4 |
if (C3 == null) |
next |
||
5 |
="src-11800-"+string(B3)+".bin" |
|||
6 |
=file(A2+C5).export@ab(C3) |
程序:(6-mulit-read.splx)
把多线程代码前移到 A11,每个线程内读取各自的文件进行计算 (B11)。
A |
B |
C |
|
9 |
…… |
||
10 |
=to(802060).(null) |
||
11 |
fork to(4) |
=file(fPath+"src-11800-"+string(A11)+".bin").cursor@b().select(时间 >=begin&& 时间 <end && events.pos(事件 ID)>0 && ${filter}) |
|
12 |
for B11,10000 |
…… |
|
13 |
…… |
结果:
11800 万条记录 /1.93GB/ 用户数量 80 万 /4 线程 /113 秒。
分析:
同样受限于加载数据速度,提速也有限。如果用多台机器集群,每台机器处理 1/4 的数据,因为是多个硬盘并行,速度肯定会有大幅提升,下面我们就看一下如何实现多机并行↓
多机集群并行计算
集算器如何部署集群计算,如何写集群的主、子程序的知识点不是本文重点关注的,可以移步相关的文档详细了解:http://doc.raqsoft.com.cn/esproc/tutorial/jqjs.html。
主程序:(6-multi-pc-main.splx)
A3 中用 callx 调用子程序 6-multi-pc-sub.splx,参数序列 [1,2,3…] 传入每个子程序控制处理哪一部分数据;返回的结果再通过 B6 汇总到一起,结果存放在 A4 格子里。
A |
B |
|
1 |
>beginTime=now() |
|
2 |
[127.0.0.1:8281,127.0.0.1:8282] |
|
3 |
=callx("e:/ldsj/demo/6-multi-pc-sub.splx",to(2),"e:/ldsj/demo/users/";A2) |
|
4 |
||
5 |
for A3 |
|
6 |
>A4=if(A4==null,A5,A4++A5) |
|
7 |
=interval@s(beginTime,now()) |
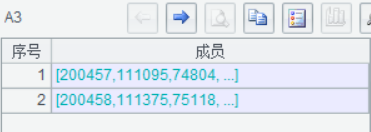
A3 得到结果序列:
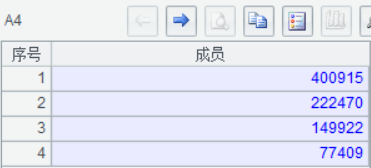
A4 汇总出最终结果:
节点机子程序:(6-multi-pc-sub.splx)
相比较上一步单机多线程加载数据的程序,去掉 A11 的多线程 fork to(4);节点机计算哪个拆分文件是通过 taskSeq 参数由主程序传过来的(B11);A22 把 A20 里的结果返回给主程序。
A |
B |
C |
|
9 |
…… |
||
10 |
=to(802060).(null) |
||
11 |
=file(fPath+"src-11800-"+string(taskSeq)+".bin").cursor@b().select(时间 >=begin&& 时间 <end && events.pos(事件 ID)>0 && ${filter}) |
||
12 |
for B11,10000 |
…… |
|
13 |
…… |
||
22 |
return A20 |
结果:
11800 万条记录 /1.93GB/ 用户数量 80 万 / 单节点机处理四分之一数据 /38 秒。主程序汇总的时间很短忽略不计,也就是 4 个 PC 的四块硬盘并行加载数据时,能把速度提升到 38 秒。
程序和测试数据在百度网盘下载 。安装好集算器,修改下程序里的文件路径,就可以运行看效果了。
结束语 - 前瞻
看到上面这么多的优化细节,估计有人质疑,这么费力的把这事做到极致,是不是吹毛求疵了?数据库应该是内置了一些自动的优化算法,目前已有共识的是尤其 ORACLE 在这方面已经做的很细致,这些细节根本不需要用户操心。确实,自动性能优化的重要意义是肯定的,但近几年随着数据环境的复杂化,数据量的剧增,更精细的控制数据的能力也就有了越来越多的应用场景,虽然会增加学习成本,但也会带来更高的数据收益。而且这个学习成本除了解决性能问题外,还能更好地解决根本上的描述复杂计算、整理数据方面的业务需求,更何况这类问题是无法自动化的,因为是“决策要做什么”变复杂了,因此只能提供更方便的编程语言提高描述效率,正视问题。计算机再智能,也不能替代人类做决策。自动和手动两种方式不是对立,而是互补的关系!
上面这些优化的思路是我们程序员能预先想到的,同时也大概能根据计算任务特点选择效果显著的优化方式。但我要说的是计算机系统太复杂了:特点迥异的计算需求、不稳定的硬盘读写速度、不稳定的网络速度、无法估量的 CPU 具体计算量!所以实际业务中我们还需要依靠经验根据实际优化的效果来选择优化方法。
SPL 出现以前,因为优化方式的实现和维护都比较困难,因此试验动作就难以密集进行,优化成果不多也就是自然的了;同时因为缺乏密集“倒腾”数据的锻炼,优化经验的积累也不容易,这也从另一个角度验证了高级数据分析师人才昂贵的现状。使用高效工具的第一批人,永远是获益最大的那一群人,第一批用弓箭的,第一批用枪的,第一批用坦克的,第一个用原子弹的……而你就是第一批用 SPL 的程序员。程序员的庞大队伍里分化出一支专业搞数据处理、分析的数据程序员,形成一个有独立技能的职业,这是必然的趋势。您的职业规划,方向选择也要尽早有个打算,才有占领某一高地的可能。
最后还要说一句,目前这个结果仍然还有优化余地。如果再将数据压缩存储,还可以进一步减少硬盘访问时间,而数据经过一定的排序并采用列式存储后确实还可以再压缩。另外,这里的集群运算拆分成了 4 个子任务,而即使配置相同的机器,也可能运算性能不同,这时候就会发生运算快的要等运算慢的,最终完成时间是以计算最慢的那台机器为准,如果我们能把任务拆得更细一些,就可以做到更平均的效率,从而进一步提高计算速度。这些内容,我们将在后面的文章继续讲述。

