


跨库数据表的运算
【摘要】
跨库数据表的运算,一直都是一个说难不算太难,说简单却又不是很简单的、总之是一个麻烦的事。大量的、散布在不同数据库中的数据表们,明明感觉要把它们合并起来,再来个小小的计算,似乎也就那么回事……但真要做起来,需要这又忘了那的,却又不像仅仅就那么回事?
想要给这些小麻烦们,来一个快刀斩乱麻式的、嘁嚓咔嚓地一劳永逸的解决方案么?首先,你需要一把叫做集算器的宝刀(重点);然后,你可以再看看这篇算是买一赠一的秘传刀法(免费);最后,面向敌人们手起刀落……你就可以轻松愉快地去睡一个好觉了:跨库数据表的运算!
1. 简单合并(FROM)
所谓跨库数据表,是指逻辑上同一张数据表被分别存储在不同数据库中。其原因有可能是因为数据量太大,放在一个数据库难以处理,也可能在业务上就需要将生产库和历史库分开。而不同的数据库,可能只是部署在不同的机器上的同种数据库,也可能是连类型都不同的数据库系统。
在面对跨库数据表,特别是数据库类型都不相同的情况时,数据库自带的工具往往就力所不及了,一般都需要寻找能够很好地支持多数据源类型的第三方工具,而集算器,可以说是其中的佼佼者了。下面,我们就针对几种常见的跨库混合运算情况详细讨论一下:
跨库运算,简单粗暴的思路就是把散布在各个库里的逻辑上相同的数据表合并成一个表,然后在这一个表上进行运算。
例如,在两个数据库 HSQL 和 MYSQL 中,分别存储了一张学生成绩表,两者各自保存了一部分学生信息,如下图所示:
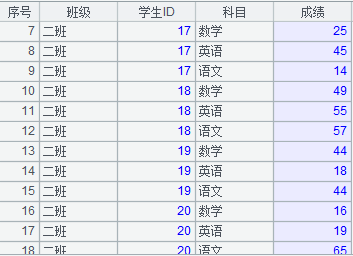

利用集算器,我们可以很容易地将这两个结构相同的表合并为一个表,集算器的 SPL 脚本如下:
A |
B |
|
1 |
=connect("org.hsqldb.jdbcDriver","jdbc:hsqldb:hsql://127.0.0.1/demo?user=sa") |
=connect("com.mysql.jdbc.Driver","jdbc:mysql://127.0.0.1:3306/demo?user=root&password=password") |
2 |
=A1.query("select * from 学生成绩表") |
=B1.query("select * from 学生成绩表") |
3 |
=A2 | B2 |
|
A1、A2 和 B1、B2 分别读取了两个库里的学生成绩表,而 A3 用一种简单直观的方式就把两个表合并了。
这种方式实际上是把两个表都读入了内存,分别生成了集算器的序表对象,然后利用序表的运算“|”完成了合并。可能有的同学会问:如果我的数据量比较大,无法全部读入内存怎么办?没关系,专为处理大数据而生的集算器,决不会被这么简单的小问题难住。我们可以使用游标,同样可以实现表的快速拼接:
A |
B |
|
2 |
=A1.cursor("select * from 学生成绩表") |
=B1.cursor("select * from 学生成绩表") |
3 |
=[A2, B2] .conjx() |
|
A2、B2 分别用游标打开两个库里的学生成绩表,A3 则使用 conjx() 函数将这两个游标合并,形成了一个新的可以同时访问两个表的游标。
对应于 SQL,这种简单合并好比只是完成了 from 工作,让结构相同的跨库表的数据“纵向”拼接成了一个可以访问的序表或者游标,而实际运算中,还会涉及过滤 (where/having)、分组聚合 (group+sum/count/avg/max/min)、连接 (join+on)、去重 (distinct)、排序 (order)、取部分数据 (limit+offset),等等操作,下面我们就将对这些运算一一展开讨论。
当然,我们在处理这些运算的需求时,不能只是简单的实现功能,我们还需要考虑实现的效率和性能,因此原则上,我们会尽量利用数据库的计算能力,而集算器主要负责混合运算。不过,有时也需要由集算器负责几乎所有的运算,数据库仅仅负责存储数据。
2. WHERE
where 过滤的本质是通过比较计算,去除比较的结果是 false 的记录,因此 where 只作用于一条记录,不涉及记录之间的运算,也不需要考虑数据位于哪个数据库。比如,在前面的例子中,我们要统计出“一班”所有同学的“数学”成绩,单库中的 SQL 是这样的:
SELECT 学生 ID, 成绩 FROM 学生成绩表 WHERE 科目 =’数学’ AND 班级 =‘一班’
多库时,也只要将 where 子句直接写在 SQL 中,让各个数据库去并行处理过滤就可以了:
A |
B |
|
2 |
=A1.query("select 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'and 班级 =' 一班 ' ") |
=B1.query("select 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'and 班级 =' 一班 ' ") |
3 |
=A2 | B2 |
|
我们也可以让集算器负责所有过滤运算,数据库仅存储数据。这时可以使用集算器的 select 函数(与 SQL 的 select 关键字不同)
A |
B |
|
2 |
=A1.query("select 学生 ID, 成绩, 科目, 班级 from 学生成绩表") |
=B1.query("select 学生 ID, 成绩, 科目, 班级 from 学生成绩表") |
3 |
=A2.select(科目 =="数学" && 班级 =="一班").new(学生 ID, 成绩) |
=B2.select(科目 =="数学" && 班级 =="一班").new(学生 ID, 成绩) |
4 |
=A3 | B3 |
|
数据量较大时,同样也可以将序表换成游标,使用 conjx 函数进行连接:
A |
B |
|
2 |
=A1.cursor("select 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'and 班级 =' 一班 ' ") |
=B1.cursor("select 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'and 班级 =' 一班 ' ") |
3 |
=[A2, B2].conjx() |
|
3. ORDER BY 和 LIMIT OFFSET
order by 是在结果集产生后才进行的处理。在上面的例子中,如果我们要按数学成绩排序,对于单数据库,只需要加上 order by 子句:
SELECT 班级, 学生 ID, 成绩 FROM 学生成绩表 WHERE 科目 =’数学’ AND 班级 =‘一班’ ORDER BY 成绩
而对于多数据库,可以让数据库先分别排序,然后由集算器归并有序数据。这样可以最大的发挥数据库与并行服务器的性能。
A |
B |
|
2 |
=A1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'and 班级 =' 一班 'order by 成绩") |
=B1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'and 班级 =' 一班 'order by 成绩") |
3 |
=[A2, B2].merge(成绩) |
|
也可以倒序排序,归并时在排序字段前加“-”(merge 函数可以不加“-”,不过按标准写法是加上的)
A |
B |
|
2 |
=A1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩 desc") |
=B1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩 desc") |
3 |
=[A2, B2].merge(- 成绩) |
|
当然也可以完全由集算器来排序:
A |
B |
|
2 |
=A1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 '") |
=B1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 '") |
3 |
=[A2.sort( 成绩), B2.sort(成绩)].merge(成绩) |
|
由集算器实现倒序排序:
A |
B |
|
2 |
=A1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 '") |
=B1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 '") |
3 |
=[A2.sort(- 成绩), B2.sort(- 成绩)].merge(- 成绩) |
|
而对于大数据量,需要使用游标及 mergex 来完成有序归并:
A |
B |
|
2 |
=A1.cursor("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩") |
=B1.cursor("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩") |
3 |
=[A2 , B2].mergex(成绩) |
|
limit 和 offset 的执行又在 order 之后,例子中如果想取数学成绩除了第一名之后的前十名(可以少于但不能多于),单库情况下 SQL 是这样的:
SELECT 班级, 学生 ID, 成绩 FROM 学生成绩表 WHERE 科目 =’数学’ AND 班级 =‘一班’ ORDER BY 成绩 DESC LIMIT 10 OFFSET 1
多数据库时,可以用集算器的 to 函数实现 limit offset 的功能,to(n+1,n+m) 等同于 limit m offset n
A |
B |
|
2 |
=A1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩 desc") |
=B1.query("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩 desc") |
3 |
=[A2, B2].merge(- 成绩).to(2, 11) |
|
对于大数据量使用游标的情况,offset 功能可以使用集算器函数 skip 实现,而 limit 的功能则可以使用函数 fetch 实现
A |
B |
|
2 |
=A1.cursor("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩 desc") |
=B1.cursor("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 'order by 成绩 desc") |
3 |
=[A2, B2].mergex(- 成绩). |
=A3.skip(1) |
4 |
=A3.fetch(10) |
4. 聚合运算
我们来讨论五种常见的聚合运算:sum/count/avg/max/min。
• sum 的基础是加法,根据加法结合律,各数据库中内部数据先分别求和,然后拼接成一张表后再求总和,与先拼接成一张表然后一起求和的结果,其实是一样的。
• count 的本质,是对每项非 null 数据计 1,null 数据计 0,然后进行累加计算。所以其本质仍是加法运算,与 sum 一样符合加法结合律。唯一不同的是对原始数据不是累加其本身的数值而是计 1(非 null)或计 0(为 null)。
• avg 的本质,是当 count > 0 时 avg = sum/count,当 count = 0 时 avg = null。显然 avg 不能像 sum 或 count 那样先分别计算了。不过根据定义,我们可以先算出 sum 和 count,再通过 sum 和 count 计算出 avg。
• max 和 min 的基础都是比较运算,而因为比较运算具有传递性,因此所有数据库的最值,可以通过比较各个数据库的最值得到。
依旧是上面的例子,这次我们要求两个班全体学生的数学总分、人数、平均分、最高及最低分,对于单源数据:
SELECT sum(成绩) 总分数, count(成绩) 考试人数, avg(成绩) 平均分, max(成绩) 最高分, min(成绩) 最低分 FROM 学生成绩表 WHERE 科目 ='数学'
聚合运算的结果集很小,只有一行,因此无论源数据量的大小,都可以使用游标,代码如下:
A |
B |
|
2 |
=A1.cursor("select sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 ' ") |
=B1.cursor("select sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 ' ") |
3 |
=[A2, B2].conjx().total(sum( 总分数), sum(考试人数), max(最高分), min(最低分)) |
|
4 |
=create(总分数, 考试人数, 平均分, 最高分, 最低分).insert(0, A3(1), A3(2), if(A3(2)!=0,A3(1)/A3(2),null), A3(3), A3(4)) |
|
事实上,前面提到的 order by +limit offset 本质上也可以看成是一种聚合运算:top。从这个角度进行优化,可以获得更高的计算效率。毕竟数据量大时,全排序的成本很高,而且取前 N 个数据的操作也并不需要全排序。当然,这个方法对于数据量小的情况也同样适用。
具体来说,对于 order by F limit m offset n 的情况,只需先用 top(n+m, F, ~),再用 to(n+1,) 就行了。
我们仍以之前的含 order by+limit offset 的 SQL 语句为例:
SELECT 班级, 学生 ID, 成绩 FROM 学生成绩表 WHERE 科目 =’数学’ AND 班级 =‘一班’ ORDER BY 成绩 DESC LIMIT 10 OFFSET 1
对于多数据库, 脚本如下,其中倒序排序只需在排序字段前加“-”:
A |
B |
|
2 |
=A1.cursor("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 '") |
=B1.cursor("select 班级, 学生 ID, 成绩 from 学生成绩表 where 科目 =' 数学 'AND 班级 =' 一班 '") |
3 |
=[A2, B2].conjx().top(11, - 成绩, ~).to(2,) |
5. GROUP BY、DISTINCT 和 HAVING
A、分组聚合运算
对于 group by,因为最终所得结果与样本个体的输入顺序无关,所以只要样本的总体不变,最终结果也不会变。也就是说,只要在从分库中提取数据和最终汇总全部数据时,都预先进行了分类运算即可。
假设我们想分别求一、二班的数学总分、人数、平均分、最高及最低分,单数据库如下:
SELECT 班级, sum(成绩) 总分数, count(成绩) 考试人数, avg(成绩) 平均分, max(成绩) 最高分, min(成绩) 最低分 FROM 学生成绩表 WHERE 科目 ='数学' GROUP BY 班级
我们分三种情况讨论:
第一,对于小数据,聚合运算的结果集只会更小,这时推荐使用 query+groups:
A |
B |
|
2 |
=A1.query("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级") |
=B1.query("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级") |
3 |
=(A2 | B2) .groups(班级: 班级; sum( 总分数): 总分数, sum(考试人数): 考试人数, max(最高分): 最高分, min(最低分): 最低分 ) |
|
4 |
=A3.new(班级, 总分数, 考试人数, if( 考试人数 ==0, null, 总分数 / 考试人数): 平均分, 最高分, 最低分 ) |
|
第二,对于大数据量,如果结果集也很大,那么就应该使用 cursor+groupx。
另外,由于大结果集的分组计算较慢,需要在外存产生缓存数据。而如果我们在数据库中对数据先排序,则可以避免这种缓存(此时计算压力会转到数据库,因此需要根据实际情况权衡,通常情况下,数据库服务器的计算能力会更强一些)。
具体的办法是对 SQL 的结果集使用 order by 排序,然后在集算器中使用 mergex 函数归并后,再使用 groupx 的 @o 选项分组:
A |
B |
|
=A1.cursor("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级 order by 班级") |
=B1.cursor("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级 order by 班级") |
|
3 |
=[A2 , B2].mergex(班级).groupx@o(班级: 班级; sum( 总分数): 总分数, sum(考试人数): 考试人数, max(最高分): 最高分, min(最低分): 最低分 ) |
|
4 |
=A3.new(班级, 总分数, 考试人数, if( 考试人数 ==0, null, 总分数 / 考试人数): 平均分, 最高分, 最低分 ) |
|
当然如果不希望加重数据库负担,也可以让数据库只做分组而不排序,此时集算器直接用 groupx,注意不能加 @o 选项。另外汇总数据时,也要把 mergex 换成 conjx:
A |
B |
|
2 |
=A1.cursor("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级") |
=B1.cursor("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级") |
3 |
=[A2, B2].conjx().groupx( 班级: 班级; sum( 总分数): 总分数, sum(考试人数): 考试人数, max(最高分): 最高分, min(最低分): 最低分 ) |
|
4 |
=A3.new(班级, 总分数, 考试人数, if( 考试人数 ==0, null, 总分数 / 考试人数): 平均分, 最高分, 最低分 ) |
|
第三,如果已明确地知道结果集很小,那么推荐用 cursor+groups
此时 groups 比 groupx 有更好的性能,因为 groups 将运算数据都保存在内存中,比 groupx 节省了写入外存文件的时间。
另外用 groups 可以不要求在数据库中预先排序,因为数据库 group by 的结果集本身不一定有序,再使用 orde by 排序也会增加成本。而对于小结果集,集算器用 groups@o 也并不一定比直接用 groups 更有效率。
通常,汇总数据要用 conjx
A |
B |
|
2 |
=A1.cursor("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级") |
=B1.cursor("select 班级, sum( 成绩) 总分数, count(成绩) 考试人数, max(成绩) 最高分, min(成绩) 最低分 from 学生成绩表 where 科目 =' 数学 'group by 班级") |
3 |
=[A2, B2].conjx().groups( 班级: 班级; sum( 总分数): 总分数, sum(考试人数): 考试人数, max(最高分): 最高分, min(最低分): 最低分 ) |
|
4 |
=A3.new(班级, 总分数, 考试人数, if( 考试人数 ==0, null, 总分数 / 考试人数): 平均分, 最高分, 最低分 ) |
|
B、去重后计数 (count distinct)
在各个数据库内去重,可以使用 distinct 关键字。而数据库之间的数据去重,则可以使用集算器的 merge@u 函数。要注意的是使用前应该确保表内数据对主键字段(或者具有唯一性的一个或多个字段)有序。
对于 distinct 来说, sum(distinct)、avg(distinct) 的计算方法与 count(distinct) 大同小异,而且业务中不常用到,而 max(distinct)、min(distinct) 与单纯使用 max、min 没有区别。因此,我们只以 count(distinct) 为例加以说明。
比如,想要计算全年级(假设只有一班和二班)语数外三科至少有一科不及格需要补考的总人数,单数据库的 SQL 是这样的:
SELECT count(distinct 学生 ID) 人数 FROM 学生成绩表 WHERE 成绩 <60
对于多源数据,全分组聚合在使用游标或序表方面没有差别,为了语法简便起见以游标为例:
A |
B |
|
2 |
=A1.cursor("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
=B1.cursor("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
3 |
=[A2, B2].mergex@u(班级, 学生 ID).total(count( 学生 ID)) |
|
再如,想要分别计算每班语数外三科至少有一科不及格需要补考的总人数,单数据库的 SQL 是这样的:
SELECT 班级, count(distinct 学生 ID) 人数 FROM 学生成绩表 WHERE 成绩 <60 GROUP BY 班级
对于多数据库,同样需要先汇总去重,再进行分组聚合。汇总前需要数据有序,且汇总后数据仍然有序,所以分组函数 groups 和 groupx 都可以使用 @o 选项。
对于小数据量,可以使用 merge@u、groups@o 和 query:
A |
B |
|
2 |
=A1.query("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
=B1.query("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
3 |
=[A2, B2].merge@u(班级, 学生 ID) .groups@o(班级: 班级; count( 学生 ID): 补习人数 ) |
|
对于大数据量小结果集,可以使用 mergex@u、groups@o 和 cursor:
A |
B |
|
2 |
=A1.cursor("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
=B1.cursor("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
3 |
=[A2, B2].mergex@u(班级, 学生 ID) .groups@o(班级: 班级; count( 学生 ID): 补习人数 ) |
|
对于大数据量大结果集,可以使用 mergex@u、groupx@o 和 cursor:
A |
B |
|
2 |
=A1.cursor("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
=B1.cursor("select distinct 班级, 学生 ID from 学生成绩表 where 成绩 <60 order by 班级, 学生 ID") |
3 |
=[A2, B2].mergex@u(班级, 学生 ID) .groupx@o(班级: 班级; count( 学生 ID): 补习人数 ) |
|
C、对聚合字段过滤(having)
having 是对聚合 (分组) 后得出的结果集再做过滤。所以当语句中有 having 出现时,如果聚合 (分组) 操作没有彻底执行完毕,需要将 having 子句先提取出来。待数据彻底完成聚合 (分组) 操作之后,再执行条件过滤。
对于多源数据,如果聚合计算是在汇总之后才能最终完成,那么 having 必须使用集算器的函数 select 来实现过滤。
下面主要说明这种聚合计算在汇总之后才完成的情况:比如,想要获得一班和二班的三个科目的考试中,有哪些平均分是低于 60 分的。对于单数据库,SQL 可以这样写:
SELECT 班级, 科目, avg(成绩) 平均分 FROM 学生成绩表 GROUP BY 班级, 科目 HAVING avg(成绩)<60
对于多数据库,相关集算器执行代码如下:
A |
B |
|
2 |
=A1.query("select 班级, 科目, sum( 成绩) 总分, count(成绩) 人数 from 学生成绩表 group by 班级, 科目") |
=B1.query("select 班级, 科目, sum( 成绩) 总分, count(成绩) 人数 from 学生成绩表 group by 班级, 科目") |
3 |
=(A2 | B2).groups(班级: 班级, 科目: 科目; sum( 总分): 总分, sum(人数): 人数 ).new( 班级, 科目, ( 总分 / 人数): 平均分 ) |
|
4 |
=A3.select(平均分 <60) |
|
对于大数据量,需要使用游标 (select 函数同样适用于游标)
A |
B |
|
2 |
=A1.cursor("select 班级, 科目, sum( 成绩) 总分, count(成绩) 人数 from 学生成绩表 group by 班级, 科目 order by 班级, 科目") |
=B1.cursor("select 班级, 科目, sum( 成绩) 总分, count(成绩) 人数 from 学生成绩表 group by 班级, 科目 order by 班级, 科目") |
3 |
=[A2, B2].mergex(班级, 科目).groupx@o(班级: 班级, 科目: 科目; sum( 总分): 总分, sum(人数): 人数 ).new( 班级, 科目, ( 总分 / 人数): 平均分 ) |
|
4 |
=A3.select(平均分 <60) |
|
6. JOIN ON
跨库的 JOIN 实现起来非常困难,不过比较幸运的是,我们可以通过存储设计避免很多跨库 JOIN。我们分三种情况讨论:
1. 同维表分库,需要重新拼接为一个表
2. 要连接的外键表在每个库中都有相同的一份
3. 需要连接的外键表在另一个库中
对于集算器来讲,前两种的处理情况是一样的:都不需要涉及跨库 join,join 操作都可以在数据库内完成。区别只在于第一种是分库表,数据库之间没有重复数据;而第二种则要求把外键表的数据复制到每个库中。
如果外键表没有复制到每个库中,那就会涉及真正的跨库 join,因为很复杂,这里只举一个内存外键表的例子,其它更复杂情况会有专门的文章阐述。
A、同维表或主子表同步分库
所谓同维表,简单来讲就是两个表的主键字段完全一样,且其中一个表的主键与另一个表的主键有逻辑意义上的外键约束(并不要求数据库中一定有真正的外键,主键同理也是逻辑上的主键并不一定存在于数据库中)。
假设有两个库,每个库中有两个表,分别记为 A 库中的 A1 表和 A2 表,B 库中的 B1 表和 B2 表。从逻辑上看 1 表是 A1 表加上 B1 表,2 表是 A2 表加上 B2 表,我们再假设 1 表与 2 表为同维表,现在要做 1 表与 2 表的 join 连接运算。
所谓同步分库,就是在设计分库存储时,保证了 1 表和 2 表按主键进行了同步的分割。也就是必须保证分库之后,A1 和 B2 的 join 等值连接的结果是空集,同样 A2 和 B1 的 join 等值连接的结果也是空集,这样也就不必有跨库的 join 连接运算了。
举例说明,比如有两张表:股票信息与公司信息,表的结构如下:
公司信息

股票信息

两个表的主键都是 (公司代码, 股票代码),且股票信息的主键与公司信息的主键有逻辑意义上的外键约束关系,二者互为同维表。
现在假设我想将两个表拼接在一起,单数据库时 SQL 是这样的:
SELECT * FROM 公司信息 T1 JOIN 股票信息 T2 ON T1. 公司代码 =T2. 公司代码 AND T1. 股票代码 = T2. 股票代码
现假设公司信息分为两部分,分别存于 HSQL 和 MYSQL 数据库中,股票信息同样分为两部分,分别存于 HSQL 和 MYSQL 数据库中,且二者是同步分库。
join 连接公司信息与股票信息的集算器代码:
A |
B |
|
2 |
=A1.query("SELECT * FROM 公司信息 T1 JOIN 股票信息 T2 ON T1. 公司代码 =T2. 公司代码 AND T1. 股票代码 = T2. 股票代码") |
=B1.query("SELECT * FROM 公司信息 T1 JOIN 股票信息 T2 ON T1. 公司代码 =T2. 公司代码 AND T1. 股票代码 = T2. 股票代码") |
3 |
=A2 | B2 |
|
对于大数据:
A |
B |
|
2 |
=A1.cursor("SELECT * FROM 公司信息 T1 JOIN 股票信息 T2 ON T1. 公司代码 =T2. 公司代码 AND T1. 股票代码 = T2. 股票代码") |
=B1.cursor("SELECT * FROM 公司信息 T1 JOIN 股票信息 T2 ON T1. 公司代码 =T2. 公司代码 AND T1. 股票代码 = T2. 股票代码") |
3 |
=[A2, B2].conjx() |
|
主子表的情况与同维表类似,即一个表(主表)的主键字段被另一个表(子表)的主键字段所包含,且子表中对应的主键字段与主表的主键有逻辑意义上的外键约束关系。
举例说明,比如有两张表:订单与订单明细,表的结构如下:
订单

订单明细

其中订单是主表,主键为 (订单 ID);而订单明细为子表,主键为 (订单 ID, 产品 ID),且订单明细的主键字段订单 ID,与订单的主键有逻辑意义上的外键约束关系,显然二者为主子表的关系。
现在假设我想将两个表拼接在一起,单数据库的 SQL 是这样的:
SELECT * FROM 订单 T1 JOIN 订单明细 T2 ON T1. 订单 ID=T2. 订单 ID
现假设订单分为两部分,分别存于 HSQL 和 MYSQL 数据库中,订单明细同样分为两部分,分别存于 HSQL 和 MYSQL 数据库中,且二者同步分库。
join 连接订单与订单明细的集算器代码:
A |
B |
|
2 |
=A1.query("SELECT * FROM 订单 T1 JOIN 订单明细 T2 ON T1. 订单 ID=T2. 订单 ID") |
=B1.query("SELECT * FROM 订单 T1 JOIN 订单明细 T2 ON T1. 订单 ID=T2. 订单 ID") |
3 |
=A2 | B2 |
|
对于大数据:
A |
B |
|
2 |
=A1.cursor("SELECT * FROM 订单 T1 JOIN 订单明细 T2 ON T1. 订单 ID=T2. 订单 ID") |
=B1.cursor("SELECT * FROM 订单 T1 JOIN 订单明细 T2 ON T1. 订单 ID=T2. 订单 ID") |
3 |
=[A2, B2].conjx() |
|
B、外键表复制进每个库
所谓外键表,即是指连接字段为外键字段的情况。这种外键表 join 也是业务上常见的一种情况。因为要连接的外键表在每个库中都有同一份,那么两个外键表汇总并去重后,其实还是任一数据库中原来就有的那个外键表。
而 join 的连接操作,本质上可以视为一种乘法,因为 join 连接等价于 cross join 后再用 on 中条件进行过滤。则根据乘法分配率可以推导出:若是需要做连接操作的外键表(不妨设为连接右侧的表)在每个库中都有同一份,则连接左侧的表(每个数据库中各有其一部分)在汇总后再连接,等同于各数据中的连接左侧的表与外键表先做连接操作后,再汇总到一起的结果。如图所示:

所以我们在存储设计时,只要在每个数据库中把外键表都重复一下,就可以避免复杂的跨库 join 操作。一般情况下,外键表作为维表的数据量相对较小,这样重复的成本就不会很高,而事实表则会得很大,然后用分库存储的方法,来解决运算速度缓慢或存储空间不足等问题。
例如,有两个表:客户销售表和客户表,其中客户销售表的外键字段:客户,与客户表的主键字段:客户 ID,有外键约束关系。现在我们想查询面向河北省各公司的销售额记录,对于单数据源,它的 SQL 是这样写的:
SELECT T1. 公司名称 公司名称, T2. 订购日期 订购日期, T2. 销售额 销售额 FROM 客户表 T1 JOIN 客户销售表 T2 ON T1. 客户 ID=T2. 客户 WHERE T1. 省份 ='河北'
对于多数据源的情况,我们假设客户销售表分别存储在两个不同的数据库中,而每个数据库中都有同一份的客户表做为外键表。则相关的集算器代码如下:
A |
B |
|
2 |
=A1.query("select T1. 公司名称 公司名称, T2. 订购日期 订购日期, T2. 销售额 销售额 from 客户表 T1 join 客户销售表 T2 on T1. 客户 ID=T2. 客户 where T1. 省份 =' 河北 ' ") |
=B1.query("select T1. 公司名称 公司名称, T2. 订购日期 订购日期, T2. 销售额 销售额 from 客户表 T1 join 客户销售表 T2 on T1. 客户 ID=T2. 客户 where T1. 省份 =' 河北 ' ") |
3 |
=A2 | B2 |
|
大数据量使用游标时:
A |
B |
|
2 |
=A1.cursor("select T1. 公司名称 公司名称, T2. 订购日期 订购日期, T2. 销售额 销售额 from 客户表 T1 join 客户销售表 T2 on T1. 客户 ID=T2. 客户 where T1. 省份 =' 河北 ' ") |
=B1.cursor("select T1. 公司名称 公司名称, T2. 订购日期 订购日期, T2. 销售额 销售额 from 客户表 T1 join 客户销售表 T2 on T1. 客户 ID=T2. 客户 where T1. 省份 =' 河北 ' ") |
3 |
=[A2, B2].conjx() |
|
C、需要连接的外键表在另一个库中
对于维表(外键表)也被分库的情况,我们只考虑维表全部可内存化的情况,不可内存化时,常常就不适合再将数据存在数据库中了,需要专门针对性的的存储和计算方案,这将在另外的文章中专门讨论。在这里我们只通过例子来讨论维表可内存化的情况。
对于这种情况,当涉及的数据量比较大而需要使用游标时,计算逻辑会变得比较复杂。所以我们在这里只讲一下针对小数据量的使用序表的 join 处理方法。关于对大数据量的使用游标的 join 处理,会另有一篇文章做专门的介绍。
当要做 join 连接运算的外键表全部或部分存储在另一个库中时,最直观的办法就是将两个表都提取出来并各自汇总后,再计算 join 连接。
下面仍以客户销售表和客户表来举例,假设外键表客户表也分别存储在两个数据库中,此时就不能在 SQL 中使用 join 关键字来实现连接运算了,但我们可以将其提取出来后,用集算器的 join 函数来实现目的,它的集算器代码如下所示:
A |
B |
|
2 |
=A1.query("select 客户 ID 客户, 公司名称 from 客户表 where 省份 =' 河北 ' ") |
=B1.query("select 客户 ID 客户, 公司名称 from 客户表 where 省份 =' 河北 ' ") |
3 |
=A2 | B2 |
|
4 |
=A1.query("select 客户, 订购日期, 销售额 from 客户销售表") |
=B1.query("select 客户, 订购日期, 销售额 from 客户销售表") |
5 |
=A4 | B4 |
|
6 |
=join(A3: 客户表, 客户; A5: 客户销售表, 客户) |
|
7 |
=A4.new(~.field(1).field(1): 客户, ~.field(1).field(2): 公司名称, ~.field(2).field(2): 订购日期, ~.field(2).field(3): 销售额 ) |
|
当事实表数据量较大的时候,也可以使用游标处理事实表,只需将 join 换成 cs.join 即可:
A |
B |
|
2 |
=A1.query("select 客户 ID 客户, 公司名称 from 客户表 where 省份 =' 河北 ' ") |
=B1.query("select 客户 ID 客户, 公司名称 from 客户表 where 省份 =' 河北 ' ") |
3 |
=A2 | B2 |
|
4 |
=A1.cursor("select 客户, 订购日期, 销售额 from 客户销售表") |
=B1.cursor("select 客户, 订购日期, 销售额 from 客户销售表") |
5 |
=[A4, B4].conjx() |
|
6 |
=A5.join(客户, A3: 客户) |
|
7. 简单 SQL
前面我们主要是从计算原理的角度出发,分析了如何使用集算器实现类似 SQL 效果的多数据源混合计算。除此之外,集算器还提供了一种更简单、直观的方法,那就是可以在各个数据库上通过 SQL 查询获取游标,用所有这些游标构建成一个多路游标对象,再用简单 SQL 对这个多路游标做二次处理。如果简单 SQL 中没有涉及 join 的运算,甚至还可以让集算器直接将一句简单 SQL 翻译成各种数据库的 SQL,从而实现更进一步的自动化。不过这种办法属于比较保守的做法,虽然简单直接,但不能利用所了解的数据情况进行优化(比如不会使用 groups),因此性能就会差一些。
下面仍旧用学生成绩的例子,我们想要计算每个班的数学成绩的总分、考试人数、平均分、最高分和最低分,使用简单 SQL 处理这个问题的集算器代码如下:
A |
B |
|
2 |
=A1.cursor("select 班级, 成绩 from 学生成绩表 where 科目 =' 数学 ' ") |
=B1.cursor("select 班级, 成绩 from 学生成绩表 where 科目 =' 数学 ' ") |
3 |
=[A2, B2].mcursor() |
|
4 |
=connect().query("select 班级, sum( 成绩) 总分, count(成绩) 考生人数, avg(成绩) 平均分, max(成绩) 最高分, min(成绩) 最低分 from {A3} group by 班级") |
|
因为使用了游标,所以这种写法也可以用于大数据量。另外再提一句,这个办法甚至也可以用于非数据库的数据源(比如文件数据源)!简单 SQL 的特性可参考相关文档,这里就不再进一步举例了。

