


早下班系列:比 python 更称手的兵器 - 续
【摘要】
高手相争,非到千招之外难分胜负;十八般武艺,又岂能一个人样样精通?面对 Python 的犀利反击,之前一直韬光养晦、深藏不露的 SPL,现在也要拿出一些真本事,来与这个编程界新任盟主一较高下了:早下班系列:比 python 更称手的兵器 - 续!

话说上一回(早下班系列:比 python 更称手的兵器),本菜鸟刚揶揄了一番某 python 培训班的代码,结果还没等收到其他小伙伴的纷纷好评,就先被本公司的大侠给打脸了。
大侠给出了如下代码:
import pandas as pd
data = pd.read_table(‘D:/data.txt’,sep=‘ ‘)
data.PRICE = data.PRICE.str[1:].str.replace(‘,’,”).astype(‘int64’)
out = data.groupby([‘STYLE’,‘BEDROOMS’]).mean()
刨除 import 语句后,同样是三行代码!而运行效率嘛,也跟集算器也差不多:同样是 1.4s 左右!

这可真是:出师未捷脸被打,常使菜鸟泪……不对,菜鸟还不能就此放弃……
仔细一想,如果连对付这么简单的一个 22.3M 的小量数据都做得那么水,那鼎鼎大名的 python 在编程语言界也就不用混了,谷歌、脸书等那么卖力推荐 python 更只会被视为脑残。
那么上一篇文章真正得出的结论其实是:就算你参加了好几个月的 python 培训班,毕业之后,你的 python 可能也只能写出类似上一篇的那种被我这样的菜鸟还疯狂嘲讽的代码。
所以,今天的再次对比,咱就不玩上次的那种“菜鸡互啄”式的对比了,上点干货:
一、玩一点真正的大数据计算
上次偷了个懒,弄个 22.3M 的东西来冒充大数据,结果惨遭打脸,至今仍隐隐作疼……这次不敢再偷懒了,既然说是大数据,那不上他个几 G 的,也敢称为“大”么?
这回咱先上集算器的:
| A | |
|---|---|
| 1 | =file(“D:/data.txt”).cursor@t(#1,#2:decimal,#3:int,#4:decimal,#5;,” “) |
| 2 | =A1.run(decimal(replace(replace(#5,”$”,””),”,”,””)):PRICE) |
| 3 | =A2.groups(STYLE,BEDROOMS;avg(SQFEET):SQFEET,avg(BATHS):BATHS,avg(PRICE):PRICE) |
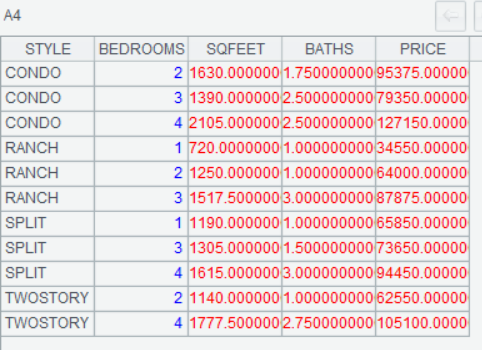
相比上次代码基本没变动多少,就是几个涉及要计算平均值的数据类型,从 int 改成了 decimal。毕竟是用大数据去计算聚合函数嘛,若还用 int 那就等着被爆出负数吧……
至于计算结果,看一看 SQFEET、BATHS 和 PRICE 三列就知道:因为是计算平均值,而大数据文件其实是用整块原始数据循环复制粘贴出来的,所以最终结果,跟原先一模一样,所以是完全正确地!
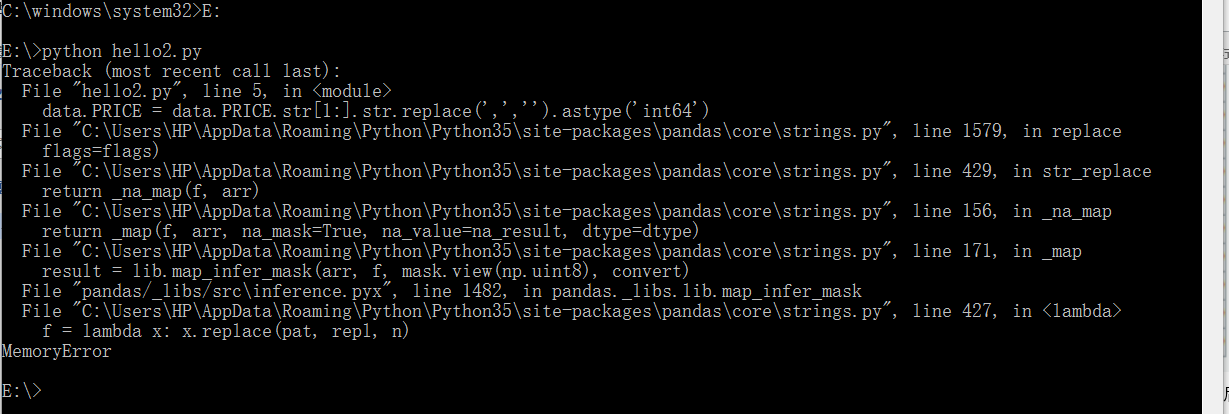
然后该 python 了,同样先上代码
import pandas as pd
data = pd.read_table(‘D:/data.txt’,sep=‘ ‘)
data.PRICE = data.PRICE.str[1:].str.replace(‘,’,”).astype(‘int64’)
print(data.groupby([‘STYLE’,‘BEDROOMS’]).mean())
接下来该测试结果了……咳,不出所料,python 家的 pandas 愉快地罢工了(内存溢出)
二、读个其他类型的文件试试
上次弄的 TXT 文本文件,是不是觉得看着太 Low,不上档次?这回咱就读个 Excel 吧。
鉴于 python 要处理大数据文件实在有点麻烦(且本人也比较懒),就不拿大数据继续欺负 python 了。回到一开始的小数据文件进行测试。只不过咱给他改成 Excel 的。

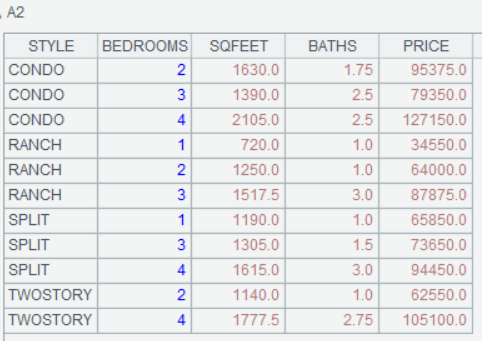
同样先上集算器的:变两行代码了(得感谢 Excel 的金额类数值的固定格式)
| A | |
|---|---|
| 1 | =file(“D:/data.xlsx”).importxls@tc() |
| 2 | =A1.groups(STYLE,BEDROOMS;avg(SQFEET):SQFEET,avg(BATHS):BATHS,avg(PRICE):PRICE) |
计算结果依旧:
接下来该上 python 了,主要代码倒也是两行
import pandas as pd
data = pd.read_excel(‘D:/data.xlsx’,sheet_name=0)
print(data.groupby([‘STYLE’,‘BEDROOMS’]).mean())
计算结果也完全一样
不过计算前别忘了安装 xlrd 和 xlwt 两个库,否则 pandas 会报错给你看哦!至于怎么安装这两个库?不难,反正我是用 pip 在线安装的。怎么安装 pip?呵呵,请看本系列的第一篇
这个比较,就算打个平手吧,毕竟 python 也不是吃素的。
三、算一点稍微复杂的东西
如果觉得平时你不需要处理多大的数据,也不嫌安 python 的各种第三方库麻烦(反正主要就折腾一次),那是否就不需要考虑集算器了呢?我觉得倒也未必……说实话,之前举例的这种分类后求平均值,太幼儿园了……根本无法体现出多少差别。所以下面咱就算个稍微复杂一点的:计算一下在至少连涨三天的股票中能达到至少连涨四天的股票的比例吧。
先看看一组原始数据:

还是先上集算器的代码,其实严格来讲整段代码可以缩成一大行(不过感觉太赖皮就不做了)。
| A | |
|---|---|
| 1 | =file(“E:/Stock.xlsx”).importxls@t().sort(Date).group(Company) |
| 2 | =A1.((a=0,~.max(a=if(Price>Price[-1],a+1,0)))) |
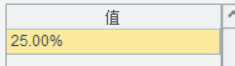
| 3 | =string(A2.count(~>=4)/A2.count(~>=3),”0.00%”) |
思路很简单,按日期排序再按股票分组,然后计算出每支股票最长上涨了多少天,再看这个值不低于 3 或不低于 4 的股票个数就完了,只是写出连涨的逻辑会有些考验,集算器有很好的跨行引用机制,就不在话下了。
计算结果嘛,因为数据不多,有耐心的可以心算验算一下
再看看 python 解决此题需要的代码(已做了尽量的简化,若还有不足欢迎指导)
import pandas as pd
defiterate(col):
prev = 0;
res = 0;
val = 0;
for curr in col:
if curr – prev > 0:
res += 1;
else:
res = 0;
prev = curr;
if val < res:
val = res;
return val;
data = pd.read_excel(‘E:/Stock.xlsx’,sheet_name=0).sort_values(‘Date’).groupby(‘Company’)[‘Price’].apply(iterate);
print(‘%.2f%%’% (data[data>=4].count()/data[data>=3].count()* 100));
基本思路其实都差不多,只是 python 没有太好的跨行引用机制,得搞个自定义函数才能实现这种略繁琐的逻辑,比较适合遇到问题喜欢 DIY 的同学们。计算结果因为都一样就不贴出来了
当然,也不是说集算器什么方面都比 python 强,比如来个深度学习神经网络啥的,暂时集算器里还没加上这类功能(毕竟术业有专攻)。总之,遇到大数据或感觉 python 类库安装起来太麻烦时,不妨考虑一下集算器。

