




报表查询分析的数据准备用什么技术?
报表查询分析都要涉及数据准备,就是把原始数据加工成可以呈现或分析的形式(如常见的报表数据集)。不过,数据准备经常并不轻松,可能面临各种复杂的情况。
数据准备面临的挑战
多样性数据源
当前业务的数据来源非常丰富,理论上任何数据源都可能同时作为报表的数据源来源,RDB、NoSQL、CSV、Excel、Json、Hadoop 不一而足,这就产生了报表开发中的多样性数据源问题。而且这些数据源要求不仅能连接,还可能进行混合计算。报表分析是一项综合事务,基于多种同构或异构数据源进行混合分析也很常见。这就需要这些数据准备技术不仅可以对接多种数据源,并可以进行跨源混合计算,还能够与报表和 BI 工具紧密结合。
复杂计算
另一个问题是报表数据准备的复杂度。有些数据准备的复杂度很高,从原始数据加工成报表需要的形式要进行大量复杂编码才能实现。这当然也跟报表的业务性质有关了,不仅数据来源广泛、跨度大、数据处理逻辑也复杂,这就造就了复杂的数据准备过程。所以,我们经常能看到上千行 SQL、几百 KB 的存储过程。
集成性
一些报表使用报表工具开发,最后在应用中发布供用户使用。数据准备作为报表的一部分,自然要与报表应用集成在一起。另外一些临时使用的一次性报表虽然不需要被集成,但如果反复出现,也可能要被移植到应用系统中,这样就也要求集成性。如果数据准备技术的集成性不好,那对报表的作用将大打折扣
另一方面,数据准备技术是否支持热部署 / 热切换直接关系到报表开发运维的方便程度,如果支持报表修改后上载到应用中可以实时生效会很方便;反过来如果还要重启服务才能生效,对开发运维就很不方便了。
常用数据准备技术
SQL
SQL 是目前用于报表数据准备常用的方式,SQL 是专用的集合运算语言,完成结构化数据处理很简单,如常见的分组汇总,一个 group by 语句就写出来了。
使用 SQL 只需要引入对应数据库接口(如 JDBC)就可以使用,具有一定的集成性,但需要与数据库紧耦合。另外,发送 SQL 给数据库可以实时查询结果,也可以认为 SQL 支持热切换。
不过 SQL 的缺点也很明显,很难应对前面我们提到数据准备面临的挑战。
SQL 基于的数据库有“库”的概念,数据只有入库才能查询,这就很难应对多样性数据源的场景。很多数据源,像 NoSQL、本地文件、网络文件系统等都面临无 SQL 可用的局面,基于这些数据源的数据准备实现时要比 SQL 麻烦得多。
还有就是复杂计算的支持并不好,SQL 要实现这些复杂计算经常要嵌套多层,几百行的 SQL 很常见,不仅实现困难,修改也不方便。举个不太复杂的例子:
根据股票记录表查询股价连续上涨超过 5 天的股票及上涨天数(股价相等记为上涨)
SQL 实现:
select code, max(risenum) - 1 maxRiseDays
from (select code, count(1) risenum
from (select code,
changeSign,
sum(changeSign) over(partition by code order by ddate) unRiseDays
from (select code,
ddate,
case
when price >= lag(price)
over(partition by code order by ddate) then
0
else
1
end changeSign
from stock_record))
group by code, unRiseDays)
group by code
having max(risenum) > 5
感受到了么,虽然并不是很长,但是看懂也要花一些时间,更别提想到并写出来了。复杂计算 SQL 实现困难来源于关系代数理论,这并非是工程上(数据库本身)可以解决的。
很多数据库还提供了存储过程,存储过程是在 SQL 的基础上增加了过程控制机制,这样就可以应对多步的数据处理任务。但存储过程并没有改变 SQL 的能力,SQL 支持不好的计算在存储过程中仍然难写。
开发效率不高就导致难以应对没完没了的报表需求,一个上千行的 SQL、几百 KB 的存储过程无论如何也没办法轻松实现,自然无法低成本应付高频新增修改的、没完没了的报表需求。
由此看来,SQL 作为最常见的数据准备技术并非十分理想,很多时候甚至非常不理想,那为什么使用仍然这么广泛呢?那是因为相对 SQL,Java 等技术表现更差。
Java
Java 作为图灵完备的语言理论上各类计算也都能完成,包括报表数据准备。而且,Java 可以很容易解决多样性数据源问题,毕竟各类数据源通常都提供的 Java 接口,因此可以顺利读取和使用,没有什么是硬编码解决不了的。
Java 另外一个优点是很容易与应用集成,报表工具或分析应用都提供了 Java 接口,Java 完成的数据准备天然可以给报表使用。
Java 的问题在于进行结构化数据计算并不方便,而报表数据准备大都是基于结构化数据进行的。Java 缺少结构化数据计算的必要类库,提供的数据类型过于基础,使得即使完成一个简单的分组汇总也好几十行代码(通用的会更复杂),相对 SQL 来说开发效率就太低了。
与 SQL 类似,低开发效率就无法很好对应没完没了的报表需求,Java 在这方面则更为严重。而且 Java 作为编译型语言不支持热切换,也很难应对频繁多变的报表需求
所以,综合来看 Java 除了具备很强的灵活性外,在数据准备面临挑战的几个方面也并不占优,很多情况下甚至不如 SQL。
Python
Python 作为新晋数据处理编程语言可以独立用于报表分析,其最大的优势在于其丰富的程序库,如在数据分析方面大名鼎鼎的 Pandas。同 Java 类似,Python 也可以对接多种数据源,完成多数据源混合计算。
在复杂计算方面,Python 支持过程计算,在 DataFrame 等特性的加持下,计算实现要比 Java 简单很多,与 SQL 相比则不相伯仲,有的计算 SQL 更简单,而 Python 支持过程计算实现复杂计算上会更有优势。
因此那些相对临时(一次性使用)的报表使用 Python 开发也还算方便。但是如果这些报表需要持久化,集成到应用系统时这些报表就有可能需要使用其他技术重做,这是因为 Python 与主流的应用程序(通常是 Java 的)很难一体化集成部署,很可能还要多进程间通讯,性能和稳定性都不好,这会大大限制 Python 用于报表数据准备的使用场景。
在实现报表数据准备方面,这些技术都存在这样那样的问题,那么还有没有其他选择呢?
理想的集算器 SPL
使用开源集算器 SPL 可以完成报表数据准备工作,并很好应对各类挑战。
集算器 SPL 是一款开源数据处理引擎,提供了不依赖数据库的计算能力,擅长结构化数据计算,计算类库丰富可以满足各类数据准备工作。SPL 天然支持多种数据源(RDB、NoSQL、Json、CSV、Webservice 等),还可以实现跨数据源混合计算。敏捷语法与过程计算可以快速实现复杂数据准备任务,轻松应对没完没了的情况。
开放的多源支持
不同于数据库需要数据先入库再计算,SPL 面对多样性数据源时可以直接计算,这样可以充分利用不同数据源各自的优点(如文件的 IO 效率很高,NoSQL 可以存储文档数据,RDB 计算能力较强)。
SPL 目前直接支持几十种数据源(仍在扩展中),你听说过还是没听说过的数据源几乎都能行,不仅可以连接取数,还可以进行跨数据源混合计算,充分利用各类数据源的优点后,再实施跨源计算为报表提供数据准备。

敏捷语法与过程计算
SPL 设计了专门用于结构化数据计算的敏捷语法,不仅天然支持过程计算,数据处理可以分多步、按照自然思维一步一步实施,而且提供了丰富的计算类库,基于 SPL 可以更容易实现复杂计算。
上一段代码看一下效果:
【计算目标】要找出销售额占到一半的前 n 个客户(大客户)的订单情况。
A |
|
1 |
=file(“/opt/ods/orders.csv”).import@tc() |
2 |
=A1.groups(customer;sum(amount):amount).sort(amount:-1) |
3 |
=A2.sum(amount)/2 |
4 |
=0 |
5 |
=A2.pselect((A4=A4+amount,A4>=A3)) |
6 |
=A2.(customer).to(,A5) |
7 |
=A1.select(A6.pos(A1.customer)) |
通过分步的方式,先找到符合条件的大客户,再查询这些客户的详细订单信息。这些计算都是在库外完成的,可以使用文件等其他数据源。从实现的过程来看,SPL 的过程计算更加优秀,语法也更为简洁。
而前面提到的计算股票最长连续上涨天数,SPL 的实现是这样的:
A |
||
1 |
=connect@l("orcl").query@x("select * from stock_record order by ddate") |
|
2 |
=A1.group(code) |
|
3 |
=A2.new(code,~.group@i(price<price[-1]).max(~.len())-1:maxrisedays) |
计算每只股票的连续上涨天数 |
4 |
=A3.select(maxrisedays>=5) |
选出符合条件的记录 |
按交易日排好序,按股票分组,SPL 分组不会强制要求聚合,可以保留分组成员,基于每个分组计算连续上涨天数。计算时,将连涨的记录分到一组,然后求最大值 -1 就是最长连续上涨天数了,完全按照自然思维实现,不用绕来绕去。
SPL 的语法简洁程度也要优于 Python,实现同样的计算也更简单。比如我们要计算:000062 股票股价最高的三天的涨幅。
Python 实现:
import pandas as pd
stock_file="D:/data/STOCKS.csv"
stock_data=pd.read_csv(stock_file,dtype={'STOCKID':'object'})
stock_62=stock_data.query('STOCKID=="000062"').copy()
ort_pos=(-stock_62["CLOSING"]).argsort()
max3pos=sort_pos.iloc[:3]
stock_62s=stock_62.shift(1)
max3CL=stock_62["CLOSING"].iloc[max3pos]
max3CLs=stock_62s["CLOSING"].iloc[max3pos]
max3_rate=max3CL/max3CLs-1
print(max3_rate)
Python 的 argsort(…) 可以返回排序后的位置信息。由于 Python 中没有循环函数,也不可以在循环过程中利用位置信息来计算,只能绕一下,先找到股价最高的 3 天的股价,再找到股价最高 3 天的前一天的股价,两者计算后得到涨幅,有点麻烦。
SPL 实现:
A |
||
1 |
=file(“D:/data/STOCKS.csv”).import@tc(#1:string,#2,#3) |
|
2 |
=A2.select(STOCKID=="000062") |
|
3 |
=A2.psort@z(CLOSING) |
/股价排序位置 |
4 |
=A3.m(:3) |
/取前 3 个位置 |
5 |
=A2.calc(A4,if(#==1,null,CLOSING/CLOSING[-1]-1)) |
/按位置算涨幅 |
SPL中的 psort(…) 函数返回从小到大的位置信息,@z 选项则是逆序。calc(…) 函数是定位计算,利用成员的位置和相对位置进行计算。CLOSING[-1] 是当前成员的前一个成员,整体无论是过程化还是运算思维都很简洁。
编辑 SPL 脚本可以使用专门的 IDE 完成,简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…,编辑调试简单,开发效率也更高。

与应用无缝集成
SPL 为报表准备数据时,位置介于报表呈现工具(或 BI 工具)和数据源之间,可以与应用系统无缝集成。这样报表和 BI 工具就拥有了复杂多步数据准备的能力,既不与数据源耦合,也跟主应用独立。SPL 提供了标准 JDBC 和 ODBC 接口供报表工具调用,可以完全替代原有数据准备方式。
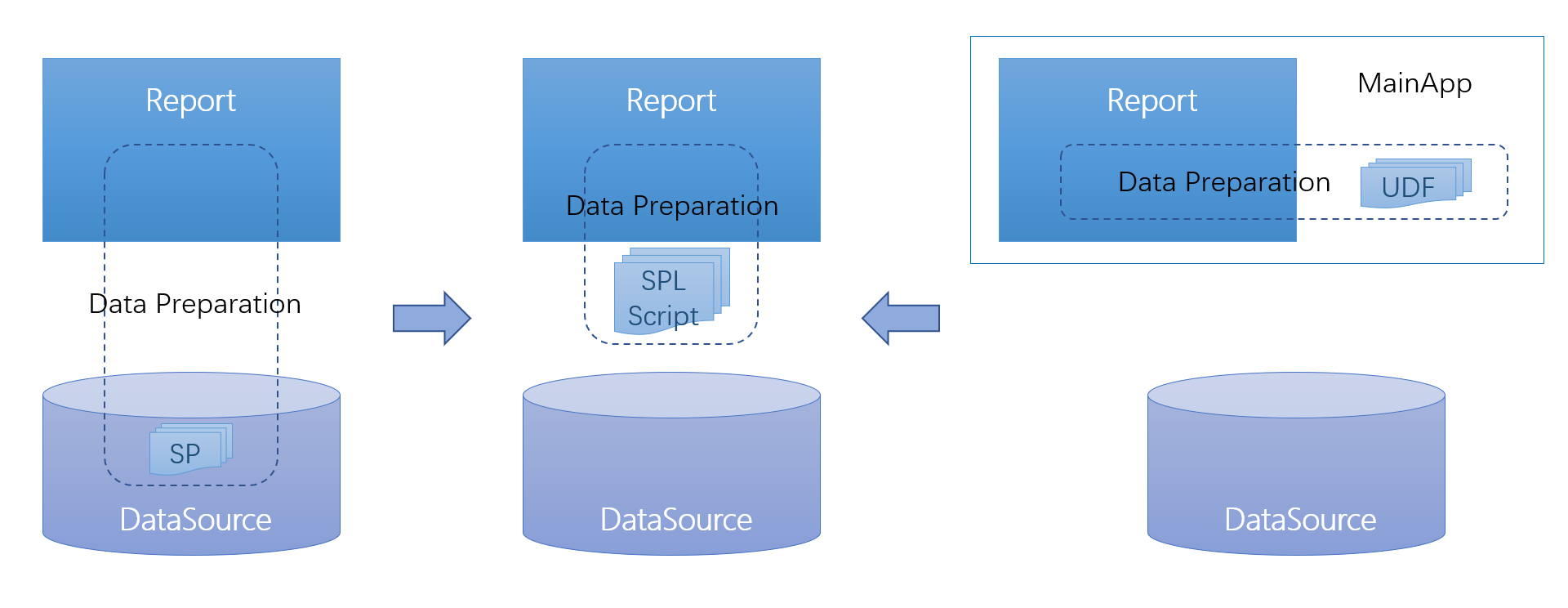
通过 JDBC 执行 / 调用 SPL 脚本很简单:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement st = conn.prepareCall("{call splscript(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
SPL 是解释执行的,天然支持热切换。可以很好适应报表多变的修改需求,修改不需要重启即时生效。

数据处理逻辑位于 SPL 文件(.splx)中,修改后实时生效,相对 Java 等编译型语言需要重启服务有很大优势。
SPL 和 SQL 都是专用结构化数据计算语言,但 SPL 更开放、语法更简洁,相对 Java 和 Python 无论是在开发效率还是集成性、热切换等方面也更具优势,因此更适合用于报表数据分析的数据准备工作。
延伸阅读
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?


英文版