


Java 怎样查询统计 MongoDB 的数据
可以用官方的Json风格的语法查询或统计MongoDB,优点是稳定可靠,缺点是语法古怪难掌握,很多基本计算都不支持,计算能力一般,而且代码非常繁琐。另一种方法是使用函数式编程风格的Hibernate Criteria,优点是更接近自然语言,易于理解,缺点是架构沉重且计算能力弱。还有一种方法,使用支持通用SQL的Calcite,优点是学习成本低,缺点是计算能力非常弱,且配置很麻烦,还要对collection进行结构性改造。
更好的方法是使用开源类库集算器SPL,不仅计算能力非常强而且容易掌握,也不需要改造collection,集成架构很轻便,配置起来也简单。
SPL提供了易用的JDBC接口,初学者可以快速入门。比如某collection存储多条雇员记录,每个雇员的Orders字段存储多条订单记录。下面对所有的订单进行条件查询:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="= mongo_shell@x(mongo_open("mongodb://127.0.0.1:27017/mongo"),"test1.find()").fetch().conj(Orders). select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*"))";
ResultSet result = statement.executeQuery(str);
…
SPL支持算法外置于JAVA代码,可大幅减低代码耦合性,特别适合计算代码较长或频繁修改的情况。比如上面的条件查询,可以先将计算代码存为SPL脚本文件:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell@x(A1,"data.find()").fetch() |
3 |
=A2.conj(Orders).select(Amount>1000 && Amount<=3000 && like@c(Client,"*s*")) |
再在JAVA代码中以存储过程的形式调用SPL脚本文件名:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="call condition()";
ResultSet result = statement.executeQuery(str);
…
SPL内置丰富的计算函数,提供了等价于SQL的计算能力。下面再举几例:
A |
B |
|
3 |
… |
|
4 |
=A2.conj(Orders).groups(year(OrderDate);sum(Amount)) |
//对订单分组汇总 |
5 |
=A2.groups(Dept,Gender;count(1)) |
//对员工分组汇总 |
6 |
=A2.sort(Dept,-Salary) |
//排序 |
7 |
=A2.id(State) |
//去重 |
SPL甚至提供了SOL语法,以方便数据库程序员。比如前面的条件查询可以改成下面的SQL:
$select OrderId, Client, Amount, OrderDate from {A2.conj()} where Client like '%S%' or (Amount>1000 and Amount<=2000)
SPL提供了简单易用的关联函数,可弥补MongoDB和其他几种计算类库的弱点。比如,对同一个collection里的员工和订单进行关联计算:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"data.find()").fetch() |
3 |
=A2.new(Orders.OrderID,Orders.Client, Name,Gender,Dept) |
再比如,两个collection是主子关系,要进行左关联,只需如下代码:
A |
B |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
|
2 |
=mongo_shell@x(A1,"main.find()").fetch() |
=mongo_shell@x(A1,"detail.find()").fethc() |
3 |
=join@1(B2,cat;A2,cat) |
|
4 |
=A3.new(_1.title,_1.regex,_1.cat,_2.path) |
|
SPL的语法体系表达能力强,很多SQL和存储过程都难以实现的计算,用SPL可以轻松解决。比如,计算某支股票最长的连续上涨天数,SPL的实际计算代码只有一行:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/mongo") |
2 |
=mongo_shell(A1,"share.find()").fetch() |
3 |
=a=0,A2.max(a=if(price>price[-1],a+1,0)) |
SPL支持多层数据对象,特别适合计算MongoDB里的多层Json数据。比如,对于下面的collection,统计每条记录中 income,output 的数量之和:
_id |
Income |
Output |
1 |
{"cpu":1000, "mem":500, "mouse":"100"} |
{"cpu":1000, "mem":600 ,"mouse":"120"} |
2 |
{"cpu":2000,"mem":1000, "mouse":"50","mainboard":500 } |
{"cpu":1500, "mem":300} |
各种类库包括MongDB自己的查询语法都很难实现这类计算,SPL就简单多了:
A |
|
1 |
=mongo_open("mongodb://127.0.0.1:27017/raqdb") |
2 |
=mongo_shell@x(A1,"computer.find()").fetch() |
3 |
=A2.new(_id:ID,income.array().sum():INCOME,output.array().sum():OUTPUT) |
SPL提供了专业的IDE,不仅有完整的调试功能,还能用表格的形式观察每一步的中间计算结果,特别适合逻辑复杂的计算:
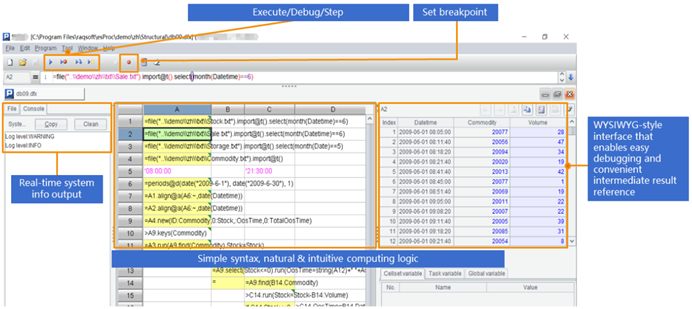
除了上面提到的,SPL还有很多实用功能,比如支持SQL语法,支持csv\xls\restful\各种NoSQL数据源的混合计算,这里不再赘述。


英文版