


Java 怎样解析和计算 json?
可以用一些类库解析json,比如sf.json\Gson\JsonPath等,但大多数没有进一步计算的能力,个别类库只能做最简单的条件查询,常见的计算几乎都要硬编码。内嵌数据库有较强的计算能力,但必须先经历繁琐的入库过程,适合时效性不敏感的情况,另外SQL是基于二维结构化数据的,并不是为多层JSON设计的,计算能力会大打折扣。
使用开源的集算器SPL能够更方便地解析json。SPL专为多层结构而设计,可以大幅简化json的计算,SPL函数丰富语法灵活,具有强大的计算能力。
SPL提供了方便调用的JDBC接口,初学者也可以轻松入门。比如,某json文件有两层,上层是员工记录,每条员工记录的Orders字段是订单记录的集合,将该文件解析为序表(SPL的多层数据对象):
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
String str="=json(file("d:/data.json").read())";
ResultSet result = statement.executeQuery(str);
…
可以看到,SPL无需入库,可以直接解析JSON文件。SPL还可以直接读取并解析restful,代码同样简单:
=json(httpfile("http://127.0.0.1:6868/api/getData").read())
SPL也可以直接读取并解析来自特殊数据源的json,比如MongoDB、elsticSearch。
SPL序表可以轻松计算多层JSON,代码简单易懂。比如,对所有员工的所有订单进行条件查询,找到金额属于某区间,且客户名称包含某字符串的订单。SPL代码如下:
=json(file("d:/data.json").read()).conj(Orders).select((Amount>1000 && Amount<=2000) && like@c(Client,"*business*"))
SPL支持算法外置,适合代码较长或频繁修改的计算,可显著降低耦合性。比如上面的条件查询可以先存为脚本文件:
A |
B |
|
1 |
=json(file("d:\\data.json").read()) |
/多层json |
2 |
=A1.conj(Orders) |
/合并订单 |
3 |
=A2.select((Amount>1000 && Amount<=2000) && like@c(Client,"*business*")) |
/条件查询 |
再在JDBC中以存储过程的形式调用脚本文件:
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection connection =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = connection.createStatement();
ResultSet result = statement.executeQuery("call getQuery()");
...
SPL内置丰富的库函数,提供了等价于SQL的计算能力,下面试举几例:
A |
||
2 |
…. |
|
3 |
=A2.conj(Orders).groups(Client;sum(Amount)) |
分组汇总 |
4 |
=A2.groups(State,Gender;avg(Salary),count(1)) |
多字段分组汇总 |
5 |
=A2.sort(Salary) |
排序 |
6 |
=A2.id(State) |
去重 |
7 |
=A2.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) |
关联 |
有些运算逻辑比较复杂,用SQL或存储过程也很难实现,而SPL具有丰富的函数和灵活的语法,可以大幅简化复杂运算逻辑。比如:json文件存储了客户名单及其销售额,要找出销售额累计占到一半的前n个大客户,并按销售额从大到小排序。
A |
B |
|
1 |
=json(file("d:\\sales.json").read()).sort(amount:-1) |
取数并逆序排序 |
2 |
=A1.cumulate(amount) |
计算累计序列 |
3 |
=A2.m(-1)/2 |
最后的累计值即是总和 |
4 |
=A2.pselect(~>=A3) |
超过一半的位置 |
5 |
=A1(to(A4)) |
按位置取值 |
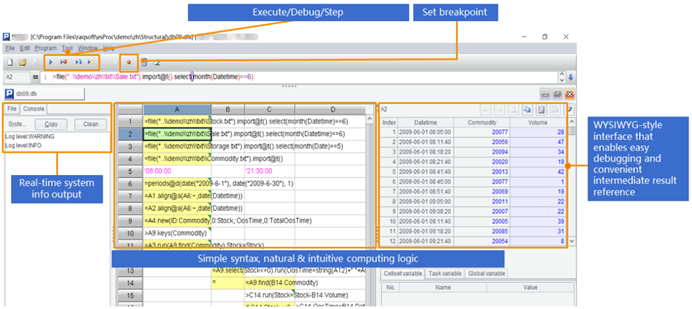
SPL提供了专业的IDE,不仅有完整的调试,还能用表格的形式观察每一步的中间计算结果,特别适合设计复杂的运算逻辑:
SPL序表可以直接表达多层json,而无需像SQL那样用二维记录做中间过度,特别适合简化多层json的计算。比如:json文件有多层子文档和多层集合(数组),部分数据如下:
[ |
按 trainerId分组,统计每组中ownerColours的成员个数,只需如下代码:
A |
|
1 |
=json(file("/workspace/JSONstr.json").read()) |
2 |
=A1(1).runners |
3 |
=A2.groups(trainer.trainerId; ownerColours.array().count():times) |
SPL结构轻便、入门成本低、解析方便、数据源种类多、计算能力强。使用SPL后,可以方便地在Java中实现多层json的计算以及逻辑复杂的计算。

