




开源SPL缩短电力企业风机监控报表开发周期16倍
问题背景
E 电力企业在风力发电系统中需要查询风力发电机运行状况(风机停机时间、停机时长、是否超过阈值等信息),在系统中通过报表(图表)输入时间和风机参数进行查询。
设备运行状态由工业设备和实时数据库(麦杰)采集记录,由于其数据过于原始,且格式无法直接用于报表查询,需要进行二次加工(标准化)存储到关系数据库再使用。
由于实时库的特殊性以及标准化算法异常复杂,以前只能用 JAVA\C# 等高级语言实现,不仅设计周期长,且难以实现难以维护。
问题分析
风机原始实时数据存储在麦杰数据库中,麦杰库没有 JDBC 接口,但有符合工业标准的 OPC 接口(OLE for Process Control)。通过该接口,JAVA 程序可获取某时间段内某风力发电机每秒(或每毫秒)的起停状态。数据格式如下:
DynamicData: time:2017-07-05 15:06:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:35:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:38:00.000,AV:4.0,AS:0 DynamicData: time:2017-07-05 15:44:00.000,AV:2.0,AS:0 DynamicData: time:2017-07-05 15:44:01.000,AV:2.0,AS:-32768 DynamicData: time:2017-07-05 15:53:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:54:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:59:00.000,AV:5.0,AS:0 DynamicData: time:2017-07-05 15:59:01.000,AV:5.0,AS:-32768 DynamicData: time:2017-07-05 15:59:02.000,AV:1.0,AS:0 |
上表中,有意义的字段是 time 和 AV,分别代表时间点和该时间点的风机状态,其中 AV 等于 1.0 表示开机,等于其他值表示各种原因导致的停机。
原始数据无法直接用于报表查询,需要标准化并存储在关系型数据库中(如 SQL Server 或 Mysql)。如下是标准化数据 alarm 表:
startTime |
endTime |
distance |
alarmno |
id |
2017-06-27 19:00:00 |
2017-06-27 19:00:00 |
0 |
-1 |
653 |
2017-07-5 16:03:00 |
2017-07-5 16:02:00 |
60 |
2 |
654 |
2017-07-5 18:06:00 |
2017-07-5 18:03:00 |
180 |
4 |
655 |
2017-07-5 18:21:00 |
2017-07-5 18:20:00 |
60 |
5 |
656 |
2017-07-5 18:39:00 |
2017-07-5 18:32:00 |
420 |
10 |
657 |
2017-07-5 18:50:00 |
11 |
658 |
各字段意义如下:
startTime:停机开始时刻(对应原始数据中的 time 字段)
endTime:停机结束时刻(即风机起动时刻,对应原始数据中的 time 字段)
distance:停起间隔秒数(endTime -startTime)
alarmno:停机状态(对应原始数据中的 AV)
id:记录编号(自增型)
另外还有风机编号等不重要的字段,这里略去。
原始数据和标准化数据对应关系举例:
1. 连续的多个(至少一个)停机数据,简称为停机区;连续的多个(至少 1 个)起机数据,简称为起机区。原始数据一定是两区交替出现的形式,比如下图黑色为起机区,红色为停机区。
DynamicData: time:2017-07-05 15:06:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:35:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:38:00.000,AV:4.0,AS:0 DynamicData: time:2017-07-05 15:44:00.000,AV:2.0,AS:0 DynamicData: time:2017-07-05 15:44:01.000,AV:2.0,AS:-32768 DynamicData: time:2017-07-05 15:53:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:54:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:59:00.000,AV:5.0,AS:0 DynamicData: time:2017-07-05 15:59:01.000,AV:5.0,AS:-32768 DynamicData: time:2017-07-05 15:59:02.000,AV:1.0,AS:0 |
2. 停机区和紧挨着的下一个起机区,合称为停起区。如下图框中就是停起区
| DynamicData: time:2017-07-05 15:06:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:35:00.000,AV:1.0,AS:0
|
3. 显然,停起区对应一条标准化数据,其中停机开始时刻为停机区的第一条,停机结束时刻(起动时刻)为起机区的第一条,这两条数据称为停起对。如下图打 * 号所示:
| DynamicData: time:2017-07-05 15:06:00.000,AV:1.0,AS:0 DynamicData: time:2017-07-05 15:35:00.000,AV:1.0,AS:0
|
所以上图中原始数据,只对应 2 条标准化数据(停起对)
startTime |
endTime |
alarmno |
2017-07-05 15:38:00 |
2017-07-05 15:53:00 |
4.0 |
2017-07-05 15:59:00 |
2017-07-05 15:59:02 |
5.0 |
标准化过程
思路:每小时定时访问麦杰库,取出一小时之内的原始数据(以下称为麦杰数据集),转为标准化数据,追加到关系型数据库。
算法 1:从麦杰库取出字符串,转为结构化二维表,以便进行后续计算。这个算法可称为结构化。
算法 2:如果关系型数据库为空,则新增一条初始数据,时间为 8 天前。
算法 3:当麦杰数据集第一条数据为停机时,如果库中最新记录为半条(只有停机说明数据错误),则比对数据后更新库,如果库中最新记录为整条(说明数据正常),则追加数据。
算法 4:当麦杰数据集第一条数据为起机时,需要追溯上一个小时或 N 个小时,直到找到对应的停机时刻,形成完整的停起对。这个算法称为追溯。
算法 5:追溯得到的停起对,需要和数据库最新记录比较,如果是漏写的数据,则追加这条数据。本算法称为补漏。
算法 6:不能无限制追溯,如果追溯 7 天仍然找不到停机时刻,则将 7 天前作为停机时刻。
算法 7:计算出所有的停起对。
算法 8:写库时,如果麦杰数据集以起为结尾,说明最后一个停起对是完整的,但如果麦杰数据集以停结尾,则说明最后一个停起对不完整(风机停了但一直没启动),此时需要向数据库插入半条记录(只有停),待下个小时再访问麦杰时,再补上这条记录的起机时刻。
算法 9:alarm 表旨在记录每次停机停了多久,但业务上有个要求是“两次停机间隔如果小于 10 分钟,则合并为一次停机”,这就要求把两条记录合并,把上一条记录的停机时刻作为合并后的停机时刻,把下一条记录的起机时刻作为合并后的起机时刻。本算法会将多条记录合并为少量记录,可形象的称为“拉链”算法。
实现这些计算的难点在于麦杰接口是 OPC,只能用 API 调用,访问起来很不方便,计算起来更是困难重重,因为它不像关系型数据库可用 SQL 语句实现查询、排序、聚合,它只能用 JAVA/C# 从底层实现,代码量极大。
解决方案
我们使用开源集算器 SPL 进行优化,最终开发时间缩短了 16 倍。下面来看一下 SPL 的解决之道。
SPL 提供多种数据源接口
除关系数据库,SPL 还提供了大量非关系型数据源接口,而且还可以通过调用 JAVA 程序进行扩展。在本例中,通过调用麦杰的 OPC 接口程序读取数据,然后在 SPL 中进行计算。
代码:
invoke(GetMaiJie.getData,name,string(lasthour),string(nowhour),0,1)
SPL 复杂计算能力
SPL 提供了丰富的集合运算方法,可以较为方便地完成各类复杂运算。
读取并结构化数据:
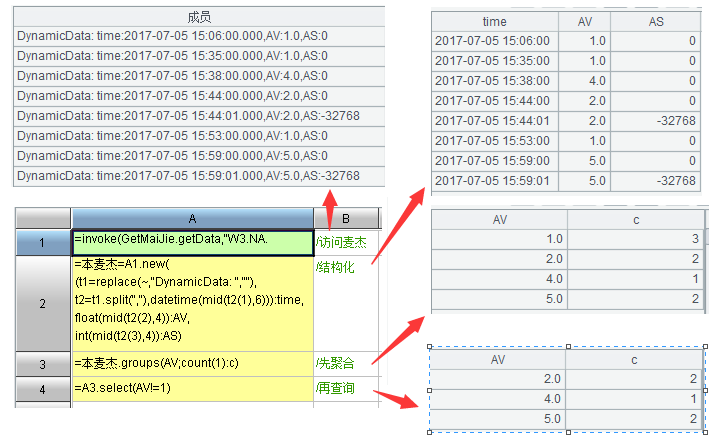
追溯(算法 4)、停起对(算法 7)、拉链(算法 9)都是很难实现的算法。以计算停起对为例,JAVA 要 195 行代码,涉及大量嵌套循环以及难以理解的临时变量和条件关系,而 SPL 只需三行。
麦杰数据集如下:
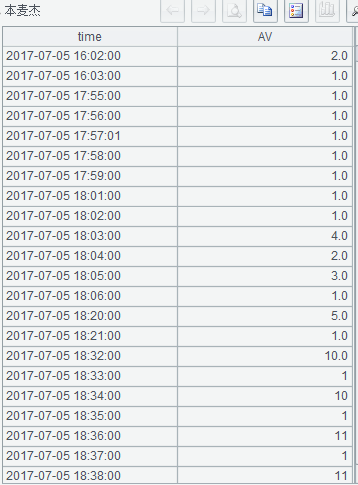
先将麦杰数据集分组,每组是一个停起区,代码:
A14=麦杰数据集.group@i(AV!=1.0 && AV[-1]==1.0)
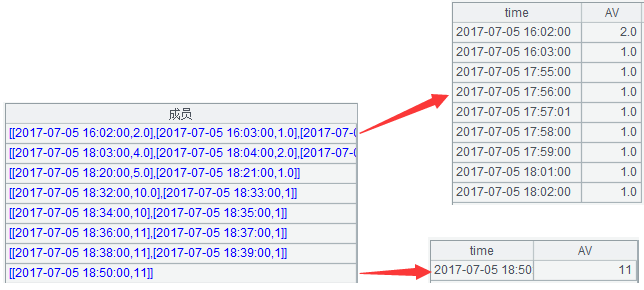
再将组内数据继续分组,即将每个起停区分为起机区与停机区,代码:
B14=A14.(~.group@i(AV[-1]!=1.0 && AV==1.0))
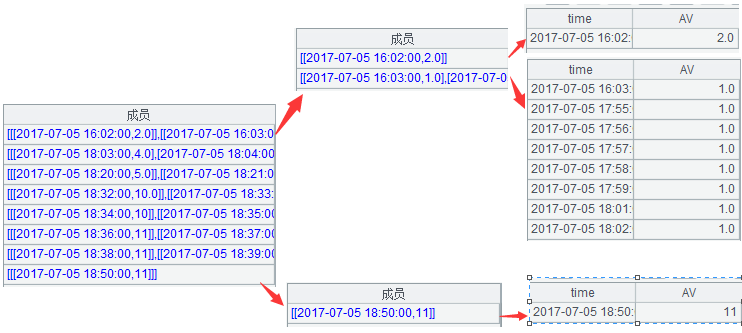
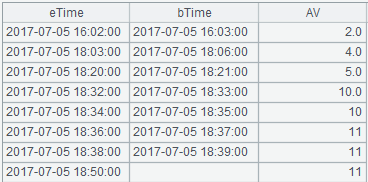
最后取出每个停机区和起机区的第一条,形成停起对。代码:
停起对
=B14.new(~(1)(1).time:eTime,if(~.len()>1,~(2)(1).time,null):bTime,~(1)(1).AV:AV)
可以看到,SPL 代码精炼易懂,可以直观表达算法逻辑,IDE 下还可以断点调试,而同样的算法数据库也难以实现。
避免频繁写库
由于拉链算法会频繁操作关系数据库,每次还要计算停起间隔,其他算法也会反复查询数据库,这就对数据库造成巨大压力,稳定性也会变差。算法中之所以易发生漏写数据、数据错误,也是因为频繁写库造成的。
SPL 有统一入库口径,可在算法中实现数据比较、拉链、查询等操作,最后将原始数据和更改后的数据自动比对,批量生成 SQL,只更新一次数据库。通过统一入库口径,数据库压力显著减轻,执行效率大大提升,原本 JAVA 中的漏写数据、数据错误不再发生。
代码:
A4=conn=connect("mysql")
A21=conn.update@l(改后表: 原始表,alarm)
A22=conn.close()
原始表:
改后表: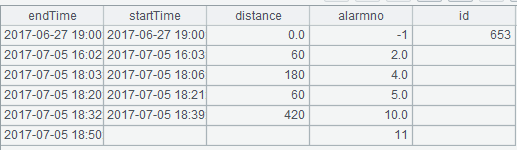
不存在计算误差
之前用 JAVA 实现追溯算法,由于缺乏直观易用的结构化库函数,只能用两个嵌套循环分别实现,一个用来计算麦杰数据集的停起对,向下循环;一个用来计算上麦杰的停起对,向上循环。向下循环比较直观,但向上循环过于抽象复杂,导致无法算出上麦杰的起机时间,只能用麦杰数据集的第一条(一定是起机时间)代替。这两个起机时间虽然属于同一个起机区,时间相差较小,但毕竟存在隐患,如果进行整月整年的统计,就会出现较大误差。
SPL 内置高性能结构化函数,上麦杰和麦杰数据集可合并后一起计算,不必分成两种算法,因此不存在这种隐患。
JAVA 实现中类似的情况有很多,基本都是由于 JAVA 等高级语言缺少集合计算类库,实现过于复杂导致。
SPL 完整代码:

方案效果
这里对比一下使用 SPL 前后的差异。
指标 |
JAVA |
SPL(SPL) |
提升 |
代码量 |
2029 行 |
22 行 |
92 倍 |
工作量 |
49 人天 |
3 人天 |
16.3倍 |
维护性 |
较差 |
好 |
易管理、热切换 |
总结
在成熟报表工具的支持下,报表格式开发的工作量已经不大,工作量已经从呈现阶段转到数据准备阶段了(本例仅给出报表数据准备算法,省略了报表的制作过程),这部分开发量占比远远大于报表布局那些事。尤其需要对接特殊数据源且涉及复杂计算时,报表工具往往无能为力。
SPL 的出现很好地解决了这些问题。SPL 提供了丰富的数据源接口(可扩展)和计算类库可以满足各类复杂计算的需要,过程化脚本编辑使得算法实现也更简单,从而进一步提升报表开发效率。
除了开发效率,在性能和应用结构方面 SPL 也有很大优势。对 SPL 感兴趣可以再参考 敏捷数据计算引擎,在《SPL COOK》中还有大量 SPL 敏捷计算的例子。
其它相关案例:
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

