




开源SPL缩短银行绩效考核报表开发周期5倍
项目背景
银行员工绩效考核报表主要用于查询员工工作的考核结果,及时了解员工最新情况,鼓励业绩突出的员工,提醒并激励后进员工。
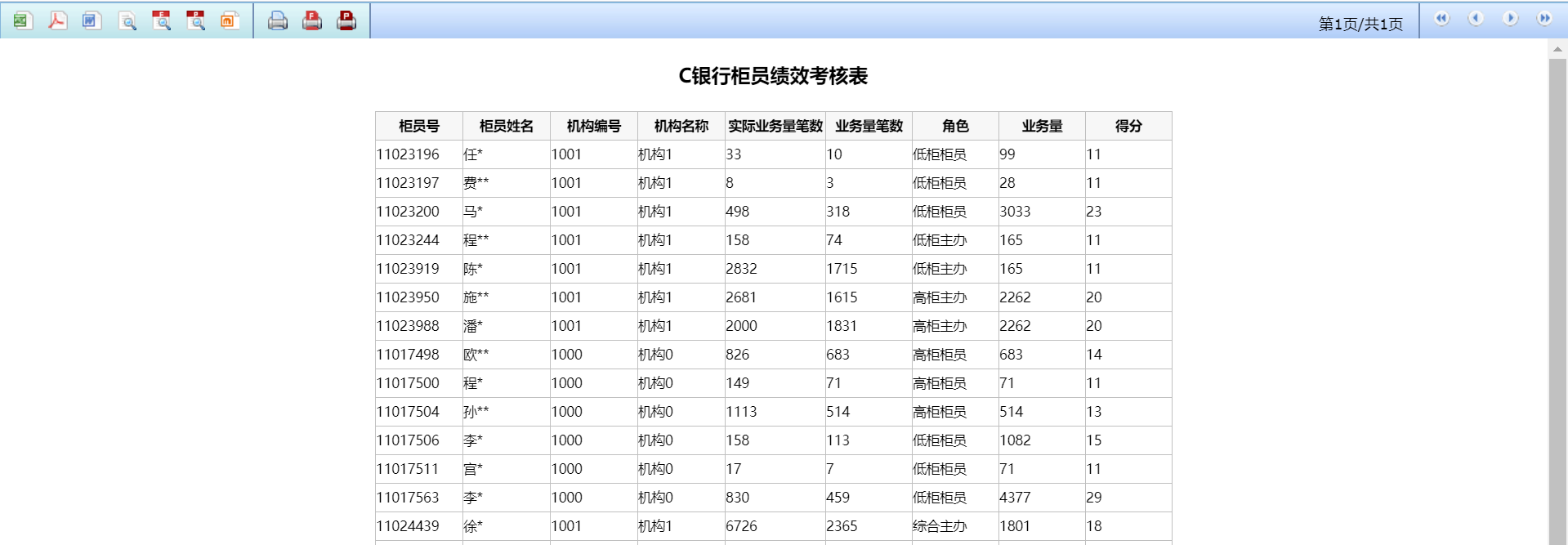
绩效考核是一项综合性事务,计算时往往涉及多种指标,实现上比较复杂。C 银行的员工绩效考核业务特点包括:
1、 涉及数据范围广
该项目要从 4 方面考核员工,包括:财务方面、客户服务方面、内部流程方面、学习成长方面。财务是指拉的存款量以及产品销售额,客户服务是指客户满意度,内部流程是指日常办公是否规范,学习成长则是指考试成绩和证书等方面。这些指标都对应银行不同的系统,涉及的数据范围很广。
2、 数据来源动态变化
考核涉及的基础数据来自银行的其他业务系统,主要通过解析其他系统导出的 excel 获取,每个表格中分多个 sheet 表,根据表名称来取得所需的 sheet 表格,数据根据表中的列名来获取数据。因为 sheet 表的顺序会变动、列名顺序也会变动,希望能够通过配置需要的 sheet 表名和列名动态取得数据。报表中同一数据可能由多个表中的多列计算获得。
3、 计算规则复杂
计算规则是一对多的层级,层级为:
计算维度、计算指标、细分指标、计分准则,细分标准下分多个计分准则,细分指标存在标杆值,有固定分值和平均分两种方式,标杆值用于计算封顶得分或者对比。
其中计算维度对应各自权重百分比,计算维度下分多个计算指标和相应的百分比,细分指标下分细分指标和各自的百分比,细分指标下分多种计分准则。
4、 计算规则需灵活配置
计算准则不固定,需要能够自定义配置,以满足日常业务和可维护性需要。
例如计算柜员考核指标的内容和计分准则如下:
柜员考核分为业务量(30%)、坐销工作(60%)、问题或差错(10%)三部分,其内容和权重会随季度或业务的繁忙程度发生变化。
问题分析
项目运行初期主要依靠 JAVA 硬编码方式实现业绩考核计算,架构如下。
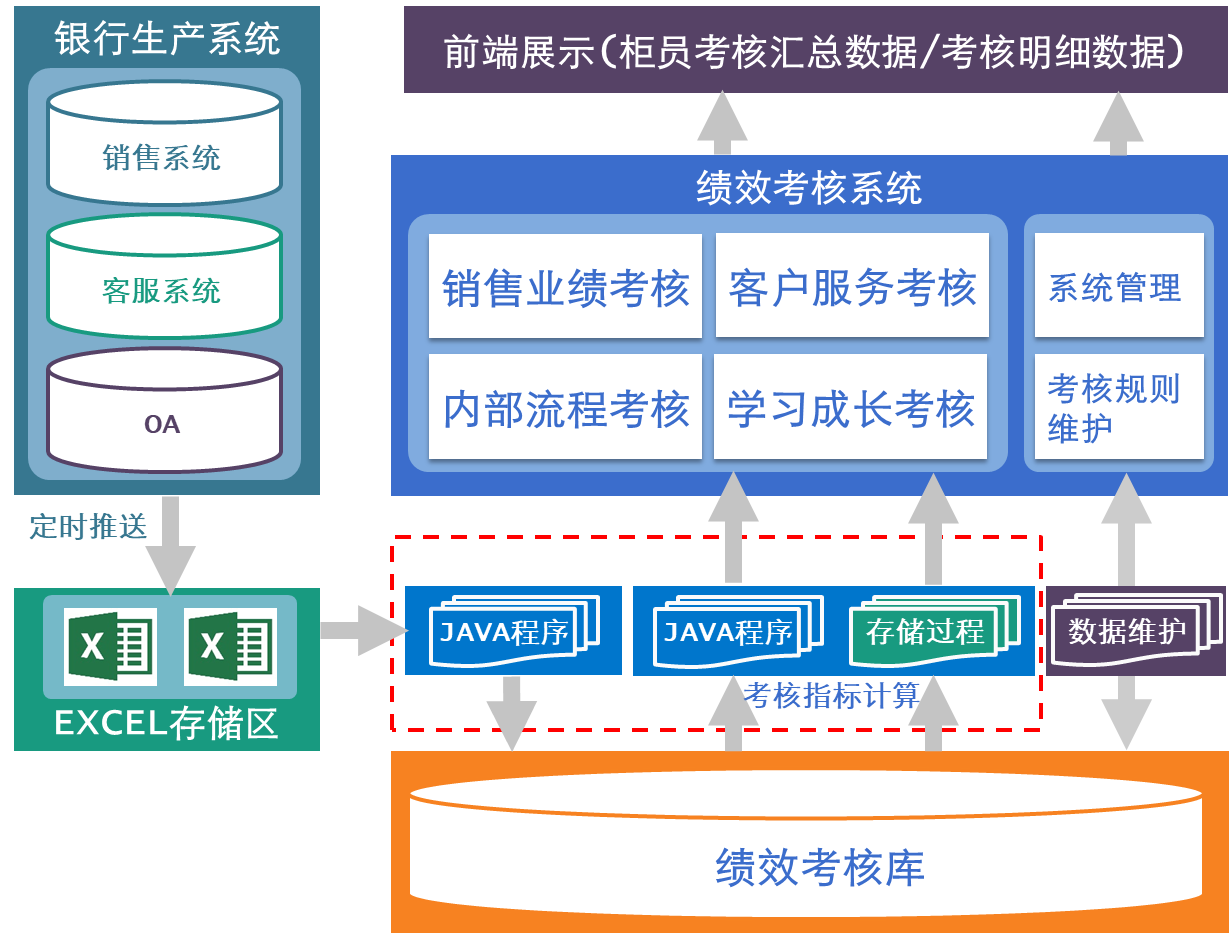
该架构下,通过 JAVA 实现带来了如下问题:
Excel 种类多解析困难
绩效考核报表的数据来源于其他系统推送的 Excel,报表需要正确读取并解析 Excel,再按照计算规则得出考核数据。但由于各系统推送的 Excel 种类高达 40 多种,每类 Excel 的数据格式不同,这就需要对应不同的解析规则。如有的 Excel 包含说明行,读取时需要跳过;有的则包含合计,读取时需要剔除;有的则需要进行行列转换才能使用…
而每个 Excel 又包含多个 sheet,因为 sheet 的顺序会变动、列名和顺序也会变动,这就需要通过配置需要的 sheet 表名和列名动态取得数据,进一步增加 Excel 解析难度。
指标计算规则复杂实现困难
绩效考核涉及财务、业务量、客户服务、内部流程、学习成长等多方面数据,每部分作用到绩效上的计算规则不同,涉及的计算复杂度也较高。如跟柜员业务量相关的得分规则为:达到平均值的计 15 分,每高于或低于分行平均值 20% 的加减 1 分, 得分最高不超过 30 分,最低分不低于 10 分。这样在计算的时候就需要根据平均值上下共划分成 20 个区间,再根据业务量对应的区间计算分值。
采用 JAVA 完成这类计算十分繁琐,JAVA 缺少针对集合运算类库,很多计算都要从头写起,实现这类计算往往需要上千行代码,实现效率较低。
需求变化快难以适应
如前所述,动态变化是绩效考核的主要特点。无论从源数据种类,数据格式,还是到 sheet 顺序、列名都是动态变化的,同时计算规则的变化也使得固化的 JAVA 程序难以适应。新需求往往要从头进行开发测试,缺乏快速响应机制,开发效率低下。
无法热切换
使用 JAVA 实现的算法修改后需要重启应用才能生效,这又会对开发效率会产生不小的影响。
这些问题导致绩效考核报表实现周期过长,成本过高!
解决方案
基于以上情况,项目最后使用开源集算器 SPL 进行绩效考核指标的计算,并将计算结果通过其提供的标准 JDBC 接口返回给前端报表进行呈现。这里以本文开篇图片中的“银行柜员绩效考核表”为例,说明 SPL 的解决过程。
该计算涉及 3 个 Excel,部分数据如图:
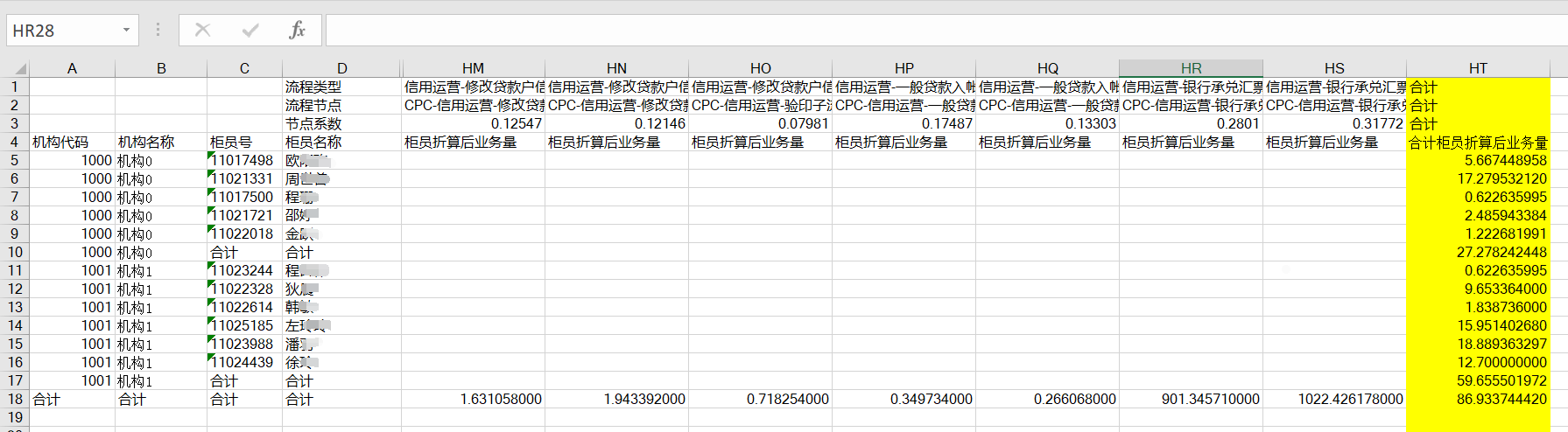
柜员业务量折算表
前 3 行数据过滤不需要读取,第 4 行为表头数据,从 4 行开始到合计的前一行是需要读取的数据行,其中第 4 行的机构代码、机构名称、柜员号、柜员名称、合计柜员折算后业务量为实际需要读取的列。
SPL 解析柜员业务量折算报表(Excel)的脚本:

A6:根据 sheet2 读取指定 sheet 名称页,跳过 4 行不读
A7:用参数传递过来的表头名称,构建一个新的序表
A8:过滤掉合计的行,即为最终结果
根据考核规则计算考核指标

A9:读取 excel 的柜员信息
A10: 柜员信息与销售业务量数据做 join 匹配
A11:计算出各柜员的 YYZB2008001001 柜员业务量汇总和 YYZB2009020018 柜员业务量折算报表相加值
A13:计算各个角色的平均业务量
 根据角色计算各个柜员的业务量,和业务量平均值(A20)
根据角色计算各个柜员的业务量,和业务量平均值(A20)

A22:根据规则:每高于或低于分行平均值 20%的加减 1 分, 得分最高不超过 30 分,构成业务量对应得分的区间。
A23:利用 SPL 的区间函数,计算各柜员的业务量得分
A25为最终计算的结果,如下:
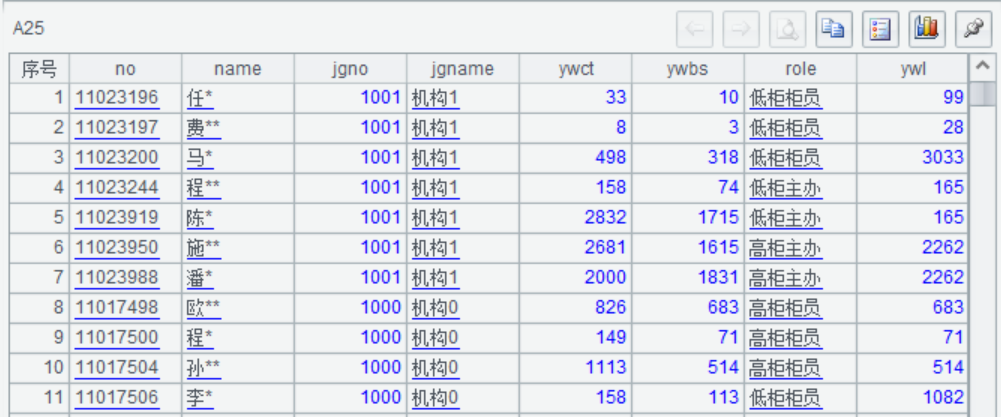
(脱敏部分数据)
这里可以看到使用 SPL25 行脚本就完成了计算,通过参数(宏)可以进行动态表(sheet)名和动态列名读取,通过 SPL 的集合运算方法(关联运算、区间划分、分组汇总)可以较方便实现绩效考核规则计算,最终通过 JDBC 接口交给前端报表呈现(报表开发部分不做详细说明)。而原来使用 JAVA 实现这个计算需要 1000 行代码,其复杂度可想而知。
方案效果
架构变化
采用 SPL 以后的系统架构改善:
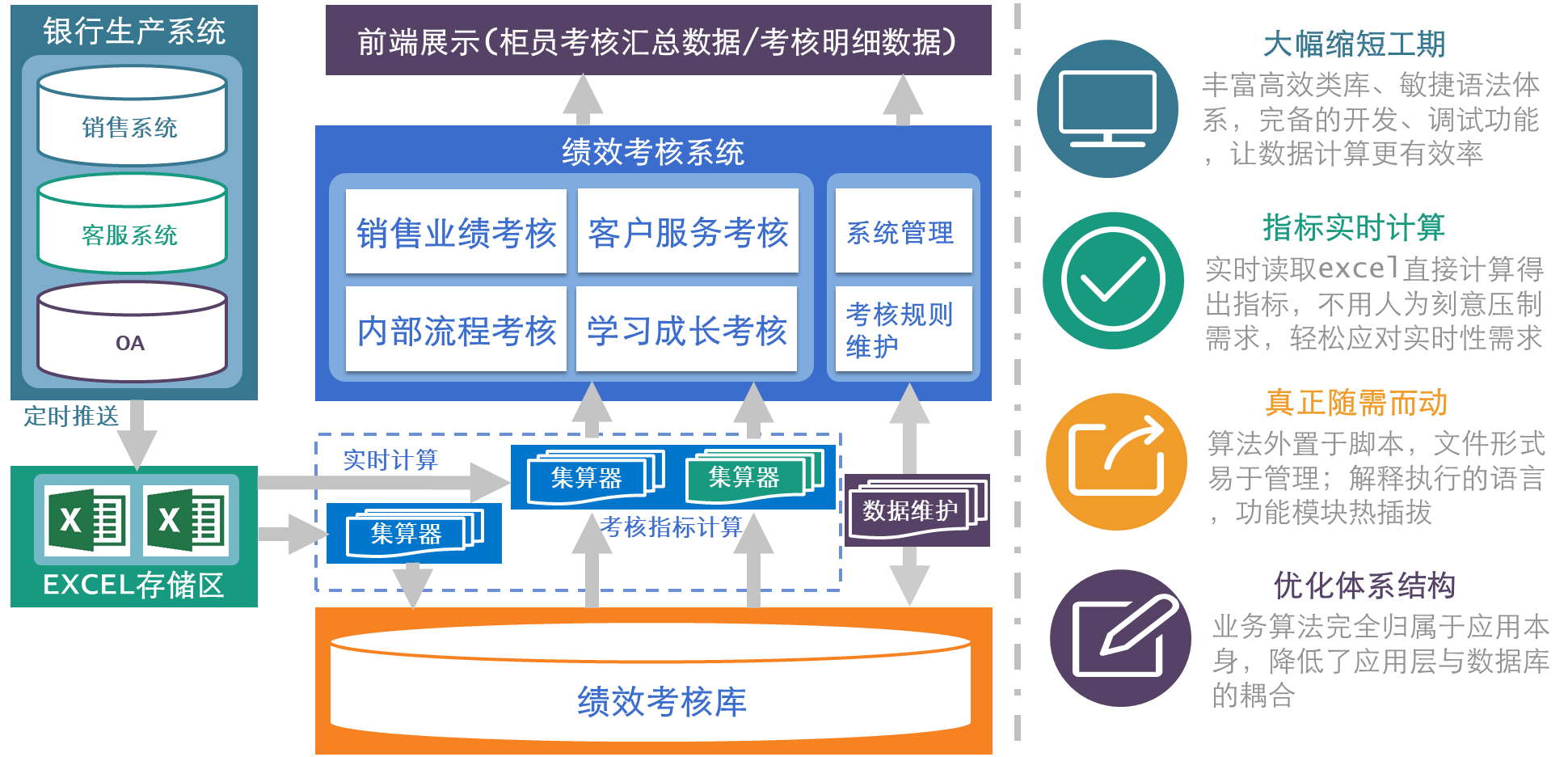
指标对比
使用 SPL 以后,开发效率得到显著提升,效果对比如下:
指标 |
Java编程 |
SPL |
提升 |
代码量 |
1000行 |
25行 |
40倍 |
工作量 |
32人天 |
6人天 |
5倍 |
可优化 |
无 |
容易 |
质变 |
维护性 |
较差 |
好 |
易管理、热切换 |
耦合性 |
高 |
低 |
模块化、工具化 |
总结
在成熟报表工具的支持下,报表格式开发的工作量已经不大,工作量已经从呈现阶段转到数据准备阶段了,这部分开发量占比远远大于报表布局那些事。而目前大多数报表工具都没有这种能力,大家只能采用原始硬编码的方式实现,开发效率非常低下。
SPL 的出现很好地解决了这个问题。SPL 提供了丰富的计算类库可以满足各类复杂计算的需要,过程化脚本编辑使得算法实现也更简单,从而进一步提升报表开发效率。
在本例中,SPL 的分步计算能力、动态数据解析能力以及丰富的集合运算函数支持使得开发效率大幅提升,从而缩短开发周期,降低实现成本。
对 SPL 感兴趣可以参考 敏捷数据计算引擎,在《SPL COOK》中有大量 SPL 敏捷计算的例子。
其它相关案例:
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?


你好
你好,是有什么问题吗?