




开源SPL缩短石油集团油井分析报表开发周期10+倍
项目背景
A 石油集团原有一套“勘探与生产技术数据管理系统”,底层结构为 JAVA,展现部分用报表工具。该系统的设计目标是宏观展示全国油井数据,监控各项关键指标,防范已知和未知风险,追溯并解决问题油井。
集团在全国有十几个大油田、上百小油田,每个油田都有几十到几千口油井。该系统在试点油田运行后,基本达到了设计目标,但正式部署到全国时,却发生了开发工作量大,迟迟无法推广的问题。
问题分析
障碍产生的原因是以 JAVA 手段处理油井数据工作量巨大。原因主要有以下几方面:
解析 JSON
原系统要对油井进行监控统计,数据来自于数据库和油井传感器。数据库提供 JDBC 接口,报表工具可直接访问,这方面不存在开发效率的问题。但油井传感器提供的是 json 接口,报表工具不能直接访问,必须解析成报表工具可识别的二维表(自定义数据集)。
个别报表工具可解析最简单(单层)json,但传感器是标准(多层)json,因此只能用 JAVA 硬编码解析,而此项开发工作量非常大。。
如果只解析一种传感器,工足量虽大但尚能忍受,但每口油井有多种传感器,json 格式各不相同,因此要用不同的 JAVA 类去解析,这样的开发效率就无法忍受了。推广到全国后,又发现即使是相同类型的传感器,各地也存在年代和版本差异,从而导致 json 格式更多更复杂,其开发过程令人苦不甘言。
数据计算
将 json 解析为 JAVA 二维表,这只是最基本的开发障碍,真正的障碍是对二维表进行计算。
数据计算是 SQL 的专项,报表工具虽然也具有计算能力,但只限于最简单的算法,并不能像 SQL 那样自由计算,比如:分组后取得各组最大的前三条记录,用这些记录和另一个二维表关联,再做一次分组汇总。此外,报表计算时必须带着外观属性,内存占用大,很容易溢出。报表计算性能更是短板,比如关联只能用字符串匹配来模拟,数据一旦上万就变得很慢。
用 SQL 无法计算 JAVA 二维表,用报表计算又缺乏自由和性能,所以只能用 JAVA 代码来计算。
JAVA 自由度极高,任意 SQL 算法理论上都能等价实现;计算时不必带着外观属性,可以控制内存溢出;利用哈希表和排序算法,性能也有保障。但 JAVA 缺乏计算类库,就连最简单的过滤都要从底层写起,因此代码冗长繁琐,极易出错,难以复用难以维护,这些都会严重影响开发进度。
其他原因
开发工作量大的原因还有:试点范围扩大到全国,报表数量剧增;油井数量每天都有增减;json 格式变化多端;报表经常要改;json 和数据库混合计算,JAVA 实现困难等等。但这些都是表面原因,最底层最根本的原因还是前面的两条:解析 Json 和数据计算。
解决方案
解决问题的关键是找到一种能快速解析 JSON 并完成数据计算的技术,并且能方便地与报表工具配合。
我们最终选择了开源集算器 SPL 进行 JSON 解析以及后续数据计算。SPL 提供了解析多层 JSON 的能力,并提供了丰富的计算类库可以快速完整解析和计算的工作,而且 SPL 提供了标准 JDBC 接口可以很方便地将计算后数据交给前端报表工具进行呈现。
解析 json
SPL 支持多种数据源,包括数据库、文本、Excel、Hadoop、mongodb,http 流,也可以直接解析 json,开发工作量几乎为零。示例如下:
A |
B |
|
1 |
=httpfile("http://10.1.127.6/Servlet?t") |
/ 获得 json 流 |
2 |
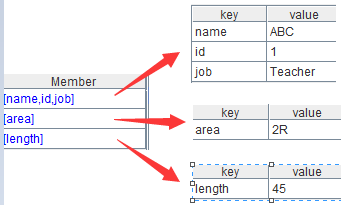
=A1.read().import@j() |
/ 解析多层 json |
解析结果如下:
数据计算
SPL 内置结构化数据计算类库,封装了丰富的结构化计算函数,支持集合运算、关联运算、有序运算,开发工作量极低。不管是执行 SQL、解析 json 或读取文件,其结果都是统一的数据类型,都可以执行所有的 SPL 函数,也可进行多数据源混合计算。示例如下:
A |
B |
|
1 |
=httpfile("http://10.1.127.6/Servlet?t") |
/ 获得 json 串 |
2 |
=A1.read().import@j() |
/ 解析多层 json |
3 |
=A2.select(like(name,"A*")) |
/ 对解析结果模糊查询 |
4 |
=A3.groups(key; count(~)) |
/ 对查询结果分组汇总 |
JDBC 接口
SPL 对外提供 JDBC 接口,可被任意 JAVA 程序、报表工具调用,用法和访问数据库一致,开发工作量几乎为零。示例如下:
Connection con= DriverManager.getConnection(“jdbc:esproc:local://”);
Statement st =con.prepareCall(“call queryJson()”);
st.execute();
方案效果
采用 SPL 方案后,以一口油井的一个报表的开发工作量为例来看一下工作量的变化。下面这张报表涉及 9 种 json 源,需要解析 json,再合并解析结果,最后进行一系列的计算 (具体数据和算法涉密不再贴出)。
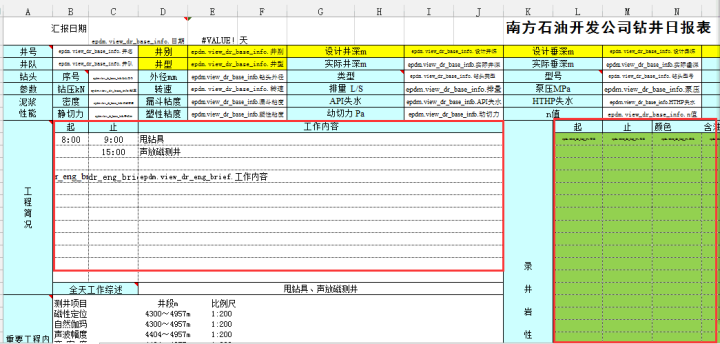
优化前后的指标对比如下:
指标 |
优化前 |
优化后 |
解析 9 种 json |
32 小时(4 工作日) |
2 小时 |
Json 合并及计算 |
64 小时(8 工作日) |
2 小时 |
报表设计 |
4 小时(0.5 工作日) |
4 小时 |
修改报表 |
32 小时(4 工作日) |
2 小时 |
总工作量 |
132小时(16.5 工作日) |
10小时 |
从 132 小时到 10 小时,报表开发周期缩短了13.2倍!
采用标准化的技术手段在缩短开发周期的同时,还可以迅速向全国复制,从而大范围推广系统提升风险管控能力,意义重大。
总结
在成熟报表工具的支持下,报表格式开发的工作量已经不大,工作量已经从呈现阶段转到数据准备阶段了,这部分开发量占比远远大于报表布局那些事。而目前大多数报表工具都没有这种能力,大家只能采用原始硬编码的方式实现,开发效率非常低下。
SPL 的出现很好地解决了这个问题。SPL 提供了丰富的计算类库可以满足各类复杂计算的需要,过程化脚本编辑使得算法实现也更简单,从而进一步提升报表开发效率。
SPL 中支持了多样性数据源(NoSQL、文本、Hadoop、ES…),可以屏蔽底层数据源的差异,适应应用扩展需要。SPL 还提供了与前端报表对接的标准 JDBC/ODBC 接口,这样绝大多数报表工具就都能享受到 SPL 给报表开发带来的诸多便利。
对 SPL 感兴趣可以参考 敏捷数据计算引擎,在《SPL COOK》中有大量 SPL 敏捷计算的例子。
其它相关案例:待添加。
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

