




制约数据挖掘业务的环节
各行各业都对数据挖掘表现出极大兴趣,也纷纷展开了应用尝试,但成功案例并不多,这是为什么呢?
1. 数据质量差
玩数据就像挖金矿。如果含金量高,那么挖掘难度就小,出金率就高,如果含金量低,那么就会难度大效果差。数据质量问题通常表现在三个方面。
(1)数据量不足
要教一个牙牙学语的小朋友什么是苹果,只需要指着苹果说“苹果”(可能需要重复这个过程几次)就行了,然后孩子就能识别各种颜色和形状的苹果了,简直是天才!
然而,机器还没达到这一步,大部分机器学习算法需要大量数据才能正常工作。即使是最简单的问题,很可能也需要成千上万个示例。因此机器学习的样本量不能过少。尤其在一些不平衡的样本中,虽然样本总量不少但是由于阳性率太低(我们关心的现象太少,如预测故障时历史数据中几乎没有故障记录)很低,这样也是很难建出有效模型。
(2)数据不具代表性
训练数据要非常有代表性。举个例子,假设我们想知道金钱是否让人感到快乐,为了分析这个问题我们可以从 OECD 网站 (https://goo.gl/0Eht9W) 下载“幸福指数”的数据,再从 IMF 网站 (http://goo.gl/j1MSKe) 找到人均 GDP 的统计数据,将数据并入表格,按照人均 GDP 排名,会得到如表显示的摘要。
| 国家 | 人均 GDP | 生活满意度 |
|---|---|---|
| 匈牙利 | 12240 | 4.9 |
| 韩国 | 27195 | 5.8 |
| 法国 | 37675 | 6.5 |
| 澳大利亚 | 50962 | 7.3 |
| 美国 | 55805 | 7.2 |
| … | … | … |
随机绘制几个国家的数据,如下左图所示。
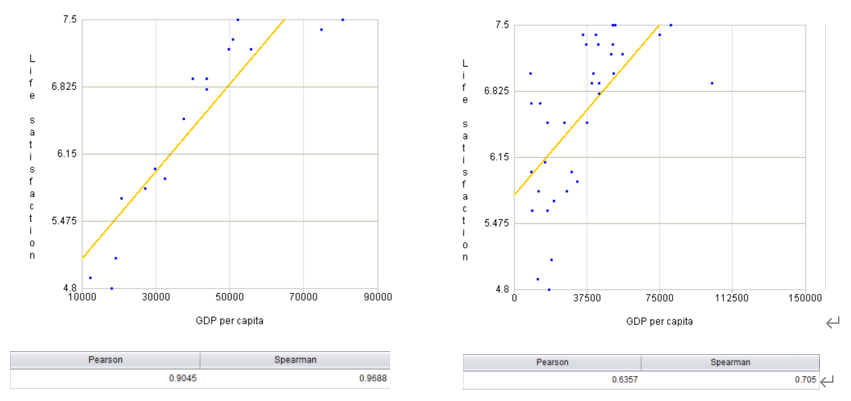
看出趋势了么,虽然数据中包含噪声,但仍然可以看出随着 GDP 增加,生活满意度或多或少呈线性上升的趋势。计算两者的线性相关系数能达 0.9 以上,似乎我们可以得出金钱能够让人感到快乐的结论。
但是,我们拿来训练的数据集并不具备完全的代表性,有些国家的数据样本缺失。将缺失国家 / 地区信息补全之后,我们又得到了右图。
缺失国家信息不仅显著地改变了模型,也更清楚地说明,这种线性模型可能永远不会那么准确(相关系数仅为 0.63)。用不具代表性的数据训练出来的模型不可能做出准确的预估,尤其是针对那些特别贫穷或富裕的国家。因此针对分析目标选择具有代表性的训练集非常重要的。
(3)错误缺失的数据
我们常说:垃圾入、垃圾出。如果原始数据满是错误、异常值和噪声,算法将很难检测到数据规律,更不太可能有良好的表现。所以花时间来清理训练数据是非常值得的投入。事实上,大多数数据科学家都会花费相当多的时间来做这项工作。例如:如果某些实例明显是异常情况,要么直接将其丢弃,要么尝试手动修复错误,都会大有帮助。再例如,如果某些实例缺少部分特征(比如,5% 的顾客没有指定年龄),你必须决定是整体的忽略这些特征,还是忽略这部分有缺失的实例,又或者是将缺失值补充完整(比如,填写年龄值得中位数),或者是训练一个带这个特征的模型,再训练一个不带这个特征的模型,等等。
这个过程是相当花费时间和精力的,但幸运的是,近年来出现了一种自动建模技术,这些产品将统计学家处理数据的丰富经验融入到了产品工具中,把这些耗时耗力的工作可交给工具自动处理。无论是对数据科学家还是数据新手来说都是一个提高工作效率的神器。
2. 专业人才少
数据挖掘项目往往由技术部门主导实施,但是由于技术有相当的工作量和难度,普通技术人员难以完成,必须有专业的数据科学家才能实现,使得项目会在某些环节上断裂。
从数据挖掘本身来看,算法设计处于核心地位,而统计学为数据挖掘提供了指导思想,同时数据挖掘又需要数据库等计算的支撑,所以说数学、统计学、计算机这几个学科在数据挖掘中都起到了比较重要的作用。一名合格的数据挖掘工程师必须要同时具备这几个学科的知识和经验。
从工具方面来讲,多数人使用 SAS 或 R/Python 等工具和编程语言,但即使有 SAS 这样的超强工具,建模工作还是要通过人工方式进行建模,而且 SAS 的应用门槛很高,同样需要很深厚的统计学背景才能用好,而这种数据科学家通常很少并且很贵,所以 SAS 很难普及用好。用 R/Python 编程的方式来实现建模挖掘分析,通常是由程序员来完成的,而纯粹的程序人员(即使编程能力很强)缺乏统计学背景知识,只会比较盲目的多次尝试,也没有数据预处理的经验,效果就会很差。
在用人成本方面,数据挖掘人才更是高居不下,通常只有大型企业的总公司才拥有少数技术团队。目前主流的人工建模方式,模型质量很大程度上取决于建模师的水平,同样的数据不同水平的人建出的模型完全不同,这样一方面模型质量无法保证,另一方面人才的流动会对数据挖掘业务产生重大影响,即使是之前开发好的模型,新来的员工对其更新,也要将整个建模过程重来一遍。
所幸的是,近年来自动建模技术的快速发展使我们已经能够帮助我们解决上述矛盾。自动建模技术会大幅度降低数据挖掘人员的门槛,一个普通的技术或业务人员经过简单的培训即可掌握,这样企业就可以快速的培养一批建模师,增加人才储备,降低建模成本。同时自动建模技术可以建立起一个模型工厂,由工厂自动化生产出来的模型质量稳定有保障,人才的流动也不会业务产生太大影响。 下表我们总结了人工建模和自动建模技术对建模师资格要求和模型特征。如表可见,相比于手工建模,自动建模技术对建模人员的要求非常低,输出模型的质量也稳定有保证。
| 建模师资格要求 | 人工建模 | 自动建模 |
|---|---|---|
| 编程能力 | 高 | 低 |
| 数值分析 | 中等 | 低 |
| 统计 / 机器学习 | 高 | 低 |
| 数据工程 | 高 | 低 |
| 业务领域知识 | 高 | 高 |
| 总体而言 | 高 | 低 |
| 模型特征 | 人工建模 | 自动建模 |
|---|---|---|
| 工具稳定性 | 商业化建模工具:高 / 开源工具:高度依赖建模师 | 高 |
| 可重复适用能力 | 同一建模者:高 / 其他建模者:低 | 高 |
| 模型成本 | 高 | 非常低 |
| 模型质量 | 高度依赖建模师 | 稳定,达到中高级建模师水平 |
| 可集成化程度 | 低 | 高 |
3. 建模效率低
目前市场业界主要采用 python 或 SAS 建模。数据探索,预处理、建模调参和模型评估全由建模师凭经验手动操作,建一个模型需要几周甚至几个月的时间,这样即使有专业人员建模效率也很低,难以大规模推广应用。
而在需求侧,业务场景是多种多样的,模型的需求量很大。就是一个业务场景也往往不是一个模型就能完全解决的,而是需要一系列的模型。例如在精准营销场景中,使用模型可以帮助我们快速的定位潜在目标客户,提高营销成功率。以目前手工建模的生产效率通常只能是简单的建一个全国所有客户的模型,但是各地区的营销政策和消费特点可能是不同,即使同一地区不同客户群体的关注点也是不一样的,并且客户购买的可能不止一款产品,这样一个模型用所有的结果就是放到哪里都不太适用。
这时候,使用自动建模技术则可以较好地解决这一问题,将建模时间由几周缩短到几个小时,在短时间内建立很多模型,这样就可以去建立一系列的模型,整体预测的效果会更好。
在一些业务场景中,业务随市场变化很快,对模型更新的要求也高,而人工建模的方式模型更新和重新建模差不多,需要重新手动数据预处理,建模调参等,如果赶上人员变动,模型更新更是耗时耗力。如此低下的生产效率是满足不了市场需求的。采用自动建模技术更新模型就很方便了,只需设定一个更新触发条件(比如定时或者模型指标下降到某一值)便可自动进行,不需要人工参与。
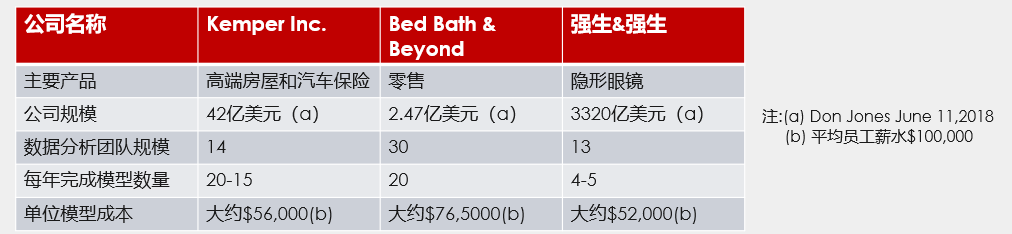
从经济角度分析,手工建模的方式生产效率低下,导致模型成本非常高,以下表中三家美国公司数据分析团队的模型成本为例,我们很保守的估计一个数据挖掘人员的年薪是 10 万美金(实际上远不止这么低),单位模型成本至少要在 5 万美金以上。而采用自动建模技术以后,生产效率至少会比原来翻几倍,模型成本也会大幅度下降,模型不再昂贵,可以广泛应用。
对进一步数据挖掘和 AI 技术感兴趣的同学还可以搜索“乾学院”,上面有面向小白的零基础“数据挖掘”免费课程,或者直接点下面的链接也可以 :
http://www.raqsoft.com.cn/wx/course-data-mining.html
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?

