


Excel 去除重复数据
【问题】
I have an excel file with following data (dummy)
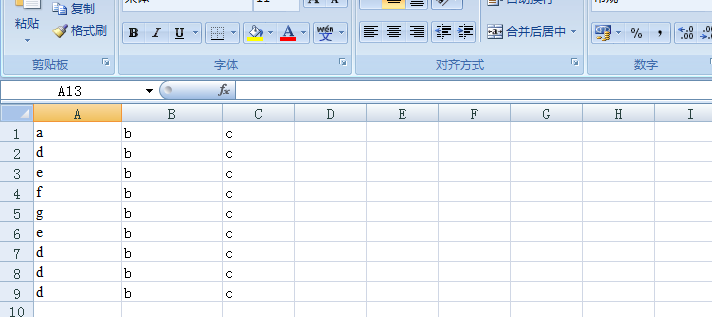
I am reading this file and storing the result in a Set so that duplicates can be removed and I only get unique list. Below is the what I tried:
FileInputStream file = new FileInputStream(new File(“C:\\Users\\harshita.sethi\\Desktop\\ALLOT010T_Input_Keywords.xls”));
HSSFWorkbook w = new HSSFWorkbook(file);
HSSFSheet sheet = w.getSheetAt(0);
int totalrows = sheet.getLastRowNum();
System.out.println(sheet.getRow(0).getPhysicalNumberOfCells());
String[][] data = new String[totalrows+1][sheet.getRow(0).getPhysicalNumberOfCells()];
Set<String[]> keySet = new HashSet<>();
for (int i = 0; i <= totalrows; i++) {
for (int j = 0; j < sheet.getRow(0).getPhysicalNumberOfCells(); j++) {
HSSFCell cell = sheet.getRow(i).getCell(j);
// writing keywords from excel into a hashmap
data[i][j]=cell.getRichStringCellValue().getString();
}
keySet.add(data[i]);
}
Iterator<String[]> iterator = keySet.iterator();
System.out.println(“Output Set is as below”);
while(iterator.hasNext()){
String[] next = iterator.next();
System.out.println(next[0] + “\t”+ next[1] +"\t"+next[2]);
}
The output of this code is as shown below
Output Set is as below
d b c
e b c
a b c
d b c
d b c
g b c
e b c
f b c
d b c
The set didn’t remove the duplicate. What other approach can I used to eliminate these duplicates. Any column can have different or same value. So I cannot remove duplicates based on a particular column
I want the entire row to be unique.
PS: This data is just dummmy. In real scenario I have more columns and any column value can be different which will make the row unique.
【回答】
这是个典型的去重动作,用 SPL 比 Java 要简单得多。
| A | |
|---|---|
| 1 | = file(“d:\\data.xlsx”).importxls() |
| 2 | = A1.group@1(#1,#2,#3) |
这段代码可以方便地集成进 Java,参考【Java 如何调用 SPL 脚本】
执行上述脚本语句即获取结果: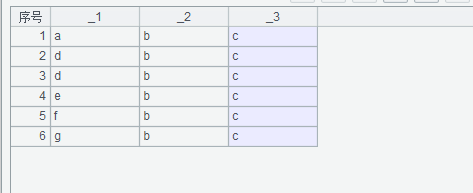
A1:读取 Excel 文件;
A2:获取数据集合并去掉重复数据;

