


数据脱敏的处理方法及查询
【摘要】
关键词:集算器、SPL、数据脱敏、报表
1)、数据脱敏是“指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏。是数据库安全技术之一。”
2)、本文介绍的脱敏数据报表查询将利用润乾集算器编写 SPL 脚本,对敏感信息字段 (如: 姓名、证件号、银行账户、住址、电话号码、企业名称、工商注册号、纳税人识别号) 等通过预定义的脱敏规则进行数据脱敏、变形,实现敏感隐私数据的保护。
3)、润乾集算器能使脱敏工作变得的简单易行,同时可以减少大量重复性工作。通过集算器 SPL 脚本实现的脱敏数据,可直接作为报表数据集进行查询分析,也可以作为开发、测试和其它非生产环境或外包环境下的真实数据集使用。
去乾学院看个究竟吧! 数据脱敏的处理方法及查询
数据脱敏的处理方法及查询
1.1 数据脱敏介绍
根据百度词条的解释,数据脱敏是“指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏。是数据库安全技术之一,数据库安全技术主要包括:数据库漏扫、数据库加密、数据库防火墙、数据脱敏、数据库安全审计系统。”
随着信息时代的发展,我们对数据信息的安全要求越来越重视,比如对非生产环境下的敏感数据的脱敏保护。在金融、运营商、政府、能源等部门,非生产环境下数据脱敏已列入监管部门的法规要求。非生产环境数据多用于开发、测试、培训以及第三方数据分析、挖掘,如果不能有效实施敏感数据保护,极易造成敏感数据的泄露。所以,保证非生产数据的安全已经成为一个重要的课题,要求我们能够通过对敏感信息进行脱敏、变形,实现有效的数据保护。
1.2 对数据脱敏工具的要求
数据脱敏工具应该具有对多种异构数据源的支持,从而将一个脱敏规则应用于不同的数据源,比如针对“客户名称”字段的修改,脱敏规则基本一致,所以应该可以在 Excel、TXT、Oracle、MS SQLServer、MySQL、Hadoop 等数据源上直接引用。另外,工具还应支持将脱敏数据完全不落地分发,提供文件到文件、文件到数据库、数据库到数据库、数据库到文件等方式,并且不需要在生产系统或本地安装任何客户端。
本文介绍的脱敏数据报表查询将利用润乾集算器编写 SPL 脚本,对敏感信息字段 ( 如: 姓名、证件号、银行账户、住址、电话号码、企业名称、工商注册号、纳税人识别号) 等通过预定义的脱敏规则进行数据脱敏、变形,实现敏感隐私数据的保护。
润乾集算器能使脱敏工作变得的简单易行,同时可以减少大量重复性工作。通过集算器 SPL 脚本实现的脱敏数据,可直接作为报表数据集进行查询分析,也可以作为开发、测试和其它非生产环境或外包环境下的真实数据集使用。
1.3 脱敏数据的特征
数据脱敏不仅要执行数据漂白,抹去数据中的敏感内容,同时也需要保持原有的数据特征、业务规则和数据关联性,保证开发、测试、培训以及大数据类业务不会受到脱敏的影响,达成脱敏前后的数据一致性和有效性:
l 保持原有数据特征
数据脱敏前后必须保证数据特征的保持,例如:身份证号码由十七位数字本体码和一位校验码组成,分别为区域地址码(6 位)、出生日期(8 位)、顺序码(3 位)和校验码(1 位)。那么身份证号码的脱敏规就需要保证脱敏后依旧保持这些特征信息。
l 保持数据之间的一致性
在不同业务中,数据和数据之间具有一定的关联性。例如:出生年月或年龄和出生日期之间的关系。同样,身份证信息脱敏后仍需要保证出生年月字段和身份证中包含的出生日期之间的一致性。
l 保持业务规则的关联性
保持数据业务规则的关联性是指数据脱敏时数据关联性以及业务语义等保持不变,其中数据关联性包括:主、外键关联性、关联字段的业务语义关联性等。特别是高度敏感的账户类主体数据往往会贯穿主体的所有关系和行为信息,因此需要特别注意保证所有相关主体信息的一致性。
l 多次脱敏之间的数据一致性
相同的数据进行多次脱敏,或者在不同的测试系统进行脱敏,需要确保每次脱敏的数据始终保持一致性,只有这样才能保障业务系统数据变更的持续一致性以及广义业务的持续一致性。
1.4 数据脱敏应用场景
一般常见的数据脱敏场景,是将生产数据或是生产数据文件按照脱敏规则,将数据不落地脱敏至测试数据库或是测试数据文件中,具体如下所示:
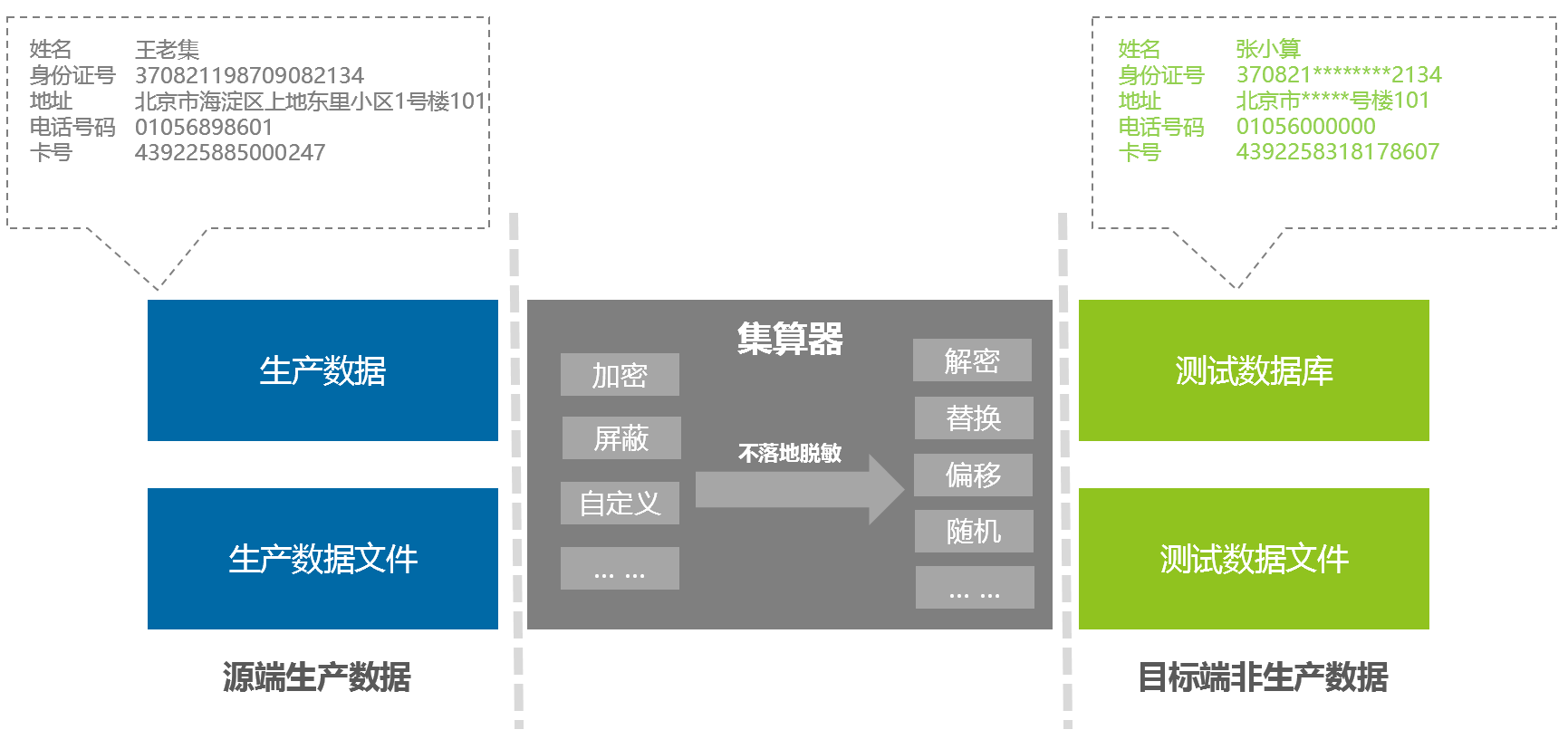
使用集算器的 SPL 可以按照业务场景要求自行定义和编写脱敏规则,比如针对上面的人员信息:姓名、身份证号、地址、电话号码、卡号等进行不落地脱敏,满足数据脱敏需要。
集算器是一个无框架,可快速部署开发的数据计算中间件工具,能够直接运行编写好的 SPL 数据脱敏脚本即时进行数据脱敏,支持各种常见的数据脱敏的处理方式,包括数据替换、无效化、随机化、偏移和取整、掩码屏蔽、灵活编码等,本文介绍的数据脱敏方法都可以在实际应用中混合替换使用。
本文中应用场景的数据脱敏都是基于下表数据内容进行的,数据存储在“数据脱敏验证表.txt”文件中。

1.4.1 数据替换
数据脱敏要求:用设置的固定虚构值替换真值。例如将手机号码统一替换为 13800013800。
使用集算器 SPL 编码实现的脚本,如下:
A |
B |
|
1 |
=file("数据脱敏验证表.txt").import@t() |
/导入文本数据 |
2 |
=A1.run(mobile=13800013800) |
/电话号码数据替换 |
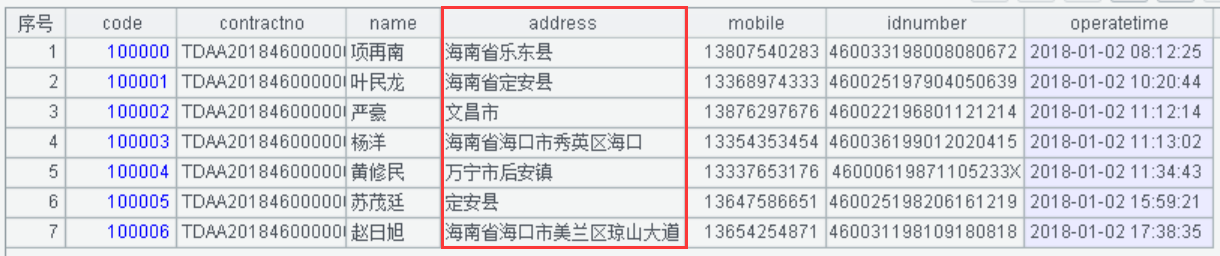
A1:导入“数据脱敏验证表”的文本数据。手机号码脱敏前的显示值如下:

A2:将手机号码统一数据替换。直接使用run()函数对 mobile 手机号码字段数据进行赋值替换为13800013800。数据替换后,手机号码脱敏后的显示值如下:

1.4.2 无效化
数据脱敏要求:通过对数据值得截断、加密、隐藏等方式使敏感数据脱敏,使其不再具有利用价值,例如将地址以 ****** 代替真值。数据无效化与数据替换所达成的效果基本类似。
使用集算器 SPL 编码实现的脚本,如下:
A |
B |
|
1 |
=file("数据脱敏验证表.txt").import@t() |
/导入文本数据 |
2 |
=A1.run(address="******") |
/地址隐藏式无效化 |
3 |
=A1.run(address=left(address,3)+"******") |
/地址截断无效化 |
A1:导入“数据脱敏验证表”的文本数据。地址脱敏前显示值如下:
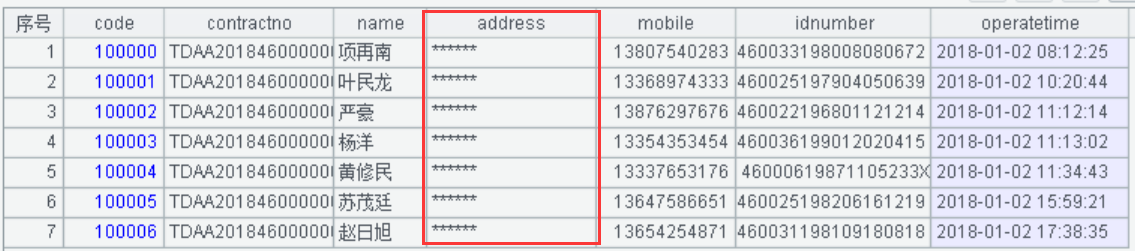
A2:将地址进行数据隐藏式的无效化脱敏。直接使用run()函数对 address 地址字段数据进行无效化的 ****** 处理。数据无效化后,地址脱敏后的显示值如下:
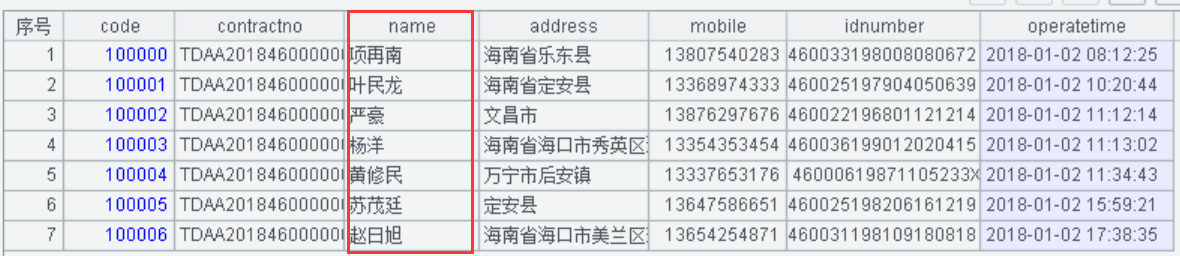
A3:将地址进行数据截断式的无效化脱敏。使用left()函数对 address 地址源字符串的左边三位字串加上 ****** 的截断无效化处理。截断无效化的地址脱敏后显示值如下:

1.4.3 随机化
数据脱敏要求:采用随机数据代替真值,保持替换值的随机性以模拟样本的真实性。例如用随机生成的姓和名代替真值。
使用集算器 SPL 编码实现的脚本,如下:
A |
B |
C |
|
1 |
=file("姓氏.txt").import@it() |
=file("名字.txt").import@it() |
/引入外部姓名字典表,用于随机生成姓名信息 |
2 |
=file("数据脱敏验证表.txt").import@t() |
/导入文本数据 |
|
3 |
=A2.run(name=A1(rand(A1.len())+1)+B1(rand(B1.len())+1)) |
/姓名随机化 |
|
A1:导入外部姓名字典表,用于随机化替换姓名真值。此处需特别注意一下,由于“姓氏”和“名字”文本数据都是单列数据表,在使用import()函数时需要增加 @i 选项,@i 表示文本数据只有1列时返回成序列,在单元格 A3 中可以直接位置获取随机值。
A2:导入“数据脱敏验证表”的文本数据。姓名脱敏前显示值如下:
A3:将姓名进行随机化脱敏。直接使用run()函数对 name 姓名进行随机化,使用rand()函数从“姓氏.txt”和“名字.txt”外部字典表随机化组合生成姓名。随机化后姓名的显示值如下:
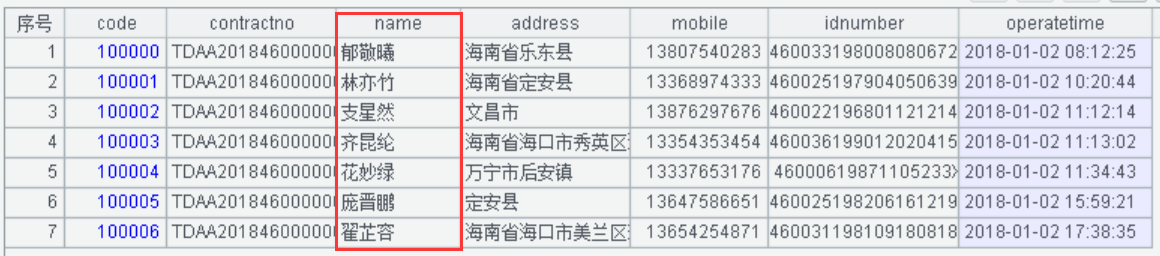
【注意】这个例子中我们针对数据脱敏引入了外部字典表,实际情况中可以根据数据脱敏要求,随时引入任意外部字典表,通过数据的随机化组合,实现替换真值数据的脱敏处理。
1.4.4 偏移和取整
数据脱敏要求:通过随机移位改变数字数据,例如日期 2018-01-02 8:12:25 变为 2018-01-02 8:00:00,偏移取整在保持了数据的安全性的同时保证了范围的大致真实性,此项功能在大数据利用环境中具有重大价值。
使用集算器 SPL 编码实现的脚本,如下:
A |
B |
||
1 |
=file("数据脱敏验证表.txt").import@t() |
/导入文本数据 |
|
2 |
=A1.run(operatetime=string(operatetime,"yyyy-MM-dd HH:00:00")) |
/日期的偏移和取整 |
|
A1:导入“数据脱敏验证表”的文本数据。操作日期脱敏前显示值如下:
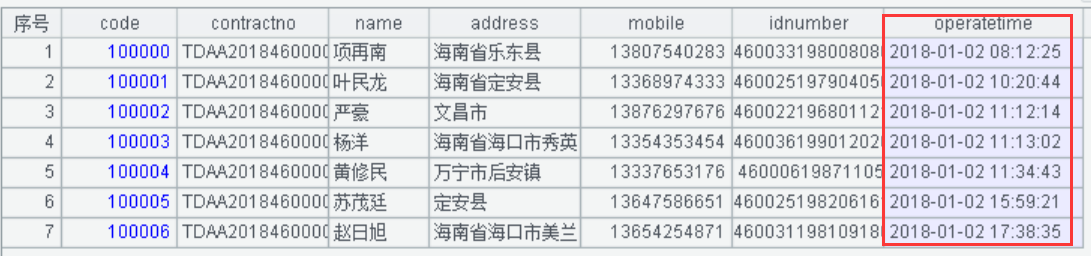
A2:将操作日期进行时间的偏移和取整脱敏。使用使用string()函数按照偏移和取整规则格式化成“yyyy-MM-dd HH:00:00”格式,操作时间脱敏后的显示值如下:
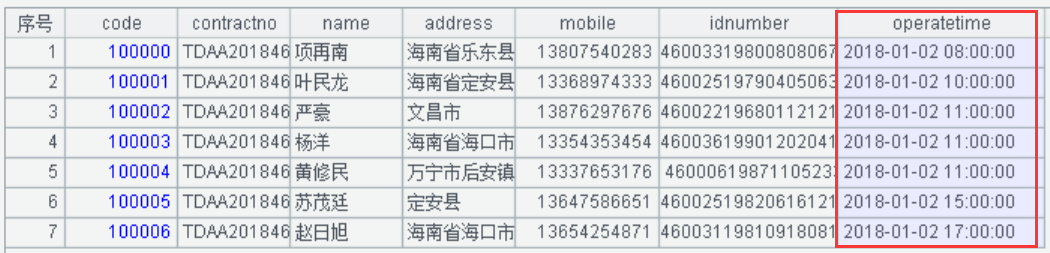
【注意】脱敏后的日期时间保持了原有的数据特征,方便脱敏数据的后续使用。
1.4.5 掩码屏蔽
数据脱敏要求:掩码屏蔽是针对账户类数据的部分信息进行脱敏时的有力工具,比如银行卡号或是身份证号的脱敏。
使用集算器 SPL 编码实现的脚本,如下:
A |
B |
||
1 |
=file("数据脱敏验证表.txt").import@t() |
/导入文本数据 |
|
2 |
=A1.run(idnumber=left(string(idnumber),6)+"********"+ right(string(idnumber),4)) |
/身份证号掩码屏蔽 |
|
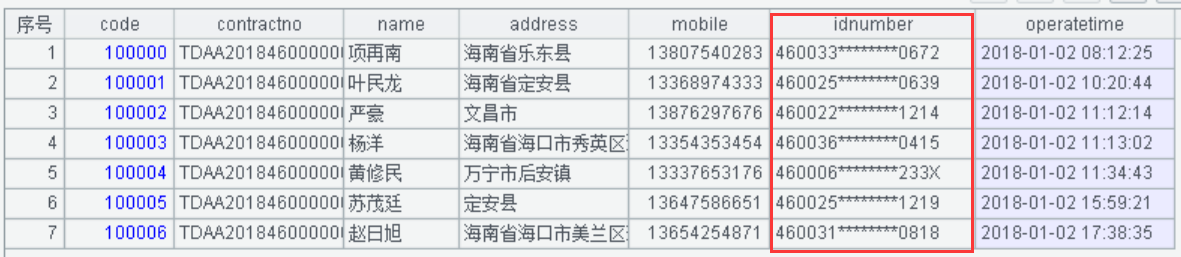
A1:导入“数据脱敏验证表”的文本数据。身份证号脱敏前显示值如下:
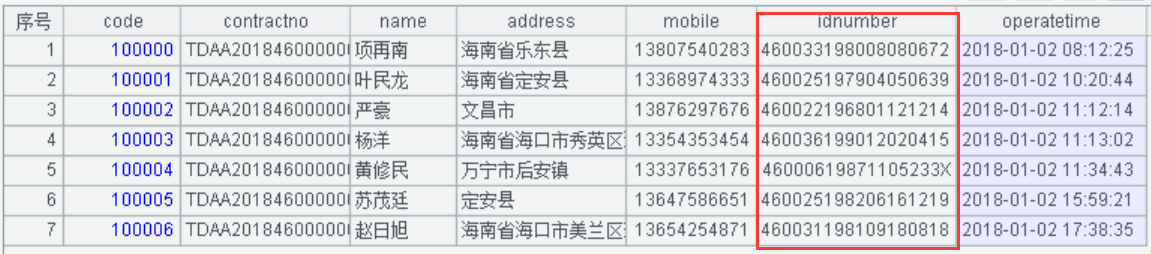
A2:将身份证号的出生日期进行掩码屏蔽脱敏。使用left()函数截取身份证号的左边 6 位 + 字符串 ********+right()函数截取身份证号右边 4 位替换源身份证字符串,身份证号码脱敏后的显示值如下:
1.4.6 灵活编码
数据脱敏要求:在需要特殊脱敏规则时,可执行灵活编码以满足各种可能的脱敏规则。比如用固定字母和固定位数的数字替代合同编号真值。
使用集算器 SPL 编码实现的脚本,如下:
A |
B |
||
1 |
=file("数据脱敏验证表.txt").import@t() |
/导入文本数据 |
|
2 |
=A1.run(contractno="RAQA"+string(year(now()))+ mid(string(contractno),9,4)+string(#,"#000000000")) |
/合同编号灵活编码 |
|
A1:导入“数据脱敏验证表”的文本数据。合同编号脱敏前显示值如下:
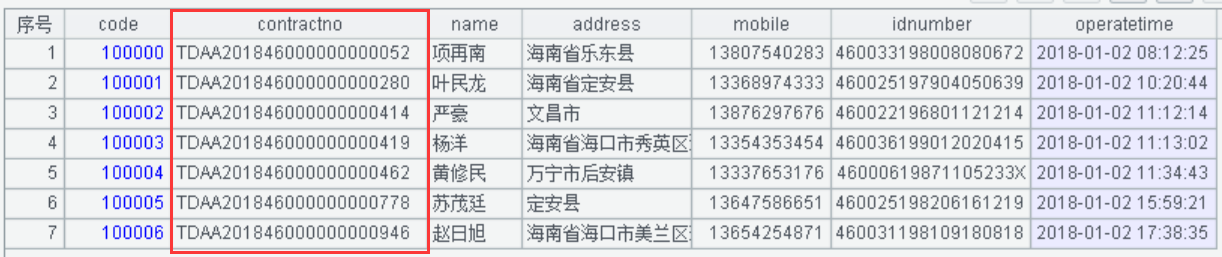
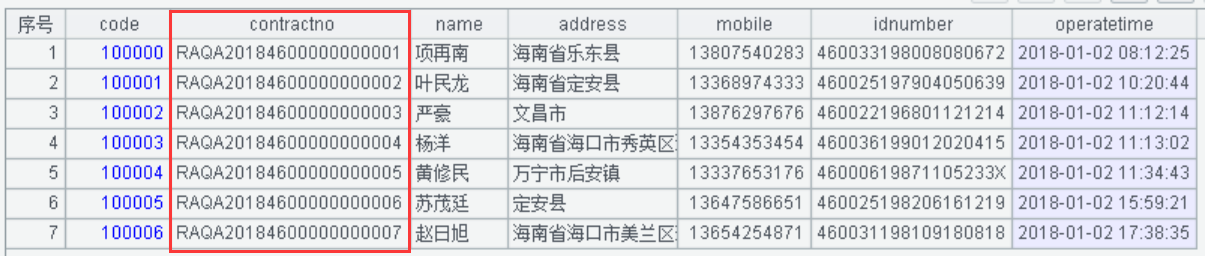
A2:将合同编号进行自定义编码脱敏。自定义编码规则:4 位固定码 + 当前年份 + 源目标字符串 4 位号码 +9 位数值组成,使用的函数已有介绍,不再赘述,合同编号脱敏后显示值如下:
1.4.7 脱敏数据的分发
集算器 SPL 支持文件到文件、文件到数据库、数据库到数据库、数据库到文件的脱敏数据分发。下面分别进行具体说明:
1.4.7.1 文本分发到文本
使用集算器 SPL 编码实现的文本分发到文本的脚本如下:
A |
B |
C |
|
1 |
=file("姓氏.txt").import@it() |
=file("名字.txt").import@it() |
/引入外部姓名字典表,用于随机组合生成姓名信息 |
2 |
=file("数据脱敏验证表.txt").cursor@t() |
/导入大数据量文本数据 |
|
3 |
=A2.run(contractno="RAQA"+string(year(now()))+mid(string(contractno),9,4)+string(#,"#000000000"),name=A1(rand(A1.len())+1) +B1(rand(B1.len())+1),address=left(address,3)+"******",mobile=13800013800,idnumber=left(string(idnumber),6)+"********"+right(string(idnumber),4),operatetime=string(operatetime,"yyyy-MM-dd HH:00:00")) |
/按照脱敏规则进行数据表脱敏 |
|
4 |
>file("脱敏数据结果表.txt").export@at(A3) |
/直接导出到文本文件 |
|
A1-B1:引入外部字典表“姓氏”和“名字”的文本数据,用于随机组合生成姓名信息。
A2:使用游标导入大数据量的“数据脱敏验证表”文本数据。
A3:按照脱敏规则进行数据表脱敏。
A4:直接将脱敏的数据导出到文本文件。使用export()函数导出脱敏数据,其中,其中 @t 指定将第一行记录作为字段名, 如果不使用 @t 选项就会以 _1,_2,…作为字段名,@a表示追加写, 不使用 @a 表示覆盖,分发到文本的脱敏结果如下:

【注意】集算器 SPL 的文件处理能力还支持导入、导出 xls、xlsx、csv 等多种类型文件。
1.4.7.2 文本分发到数据库
使用集算器 SPL 编码实现的文本分发到数据库(以 MySQL 为例)的脚本如下:
A |
B |
C |
|
1 |
=file("姓氏.txt").import@it() |
=file("名字.txt").import@it() |
/引入外部姓名字典表,用于随机组合生成姓名信息 |
2 |
=file("数据脱敏验证表.txt").cursor@t() |
/导入大数据量文本数据 |
|
3 |
=A2.run(contractno="RAQA"+string(year(now()))+mid(string(contractno),9,4)+string(#,"#000000000"),name=A1(rand(A1.len())+1) +B1(rand(B1.len())+1),address=left(address,3)+"******",mobile=13800013800,idnumber=left(string(idnumber),6)+"********"+right(string(idnumber),4),operatetime=string(operatetime,"yyyy-MM-dd HH:00:00")) |
/按照脱敏规则进行数据表脱敏 |
|
4 |
=connect("MySQL") |
/连接 MySQL 数据源 |
|
5 |
>A4.update(A3,personinfo,code,contractno,name,address, mobile,idnumber,operatetime;code) |
/执行 update 更新,直接导出到数据库中 |
|
6 |
>A4.close() |
/关闭数据库连接 |
|
A1-A3:同上。
A4:连接 MySQL 数据源。使用connect()进行 MySQL 数据库的连接。如果用鼠标点击 A4 单元格,可以直接查看 MySQL 数据库的连接信息。具体查看数据库配置教程相关章节文档配置说明。
A5:更新 MySQL 数据库中“personinfo”库表的数据。使用update()将单元格 A3 的游标数据更新到 MySQL 数据库“personinfo”库表中。使用数据库工具查看结果如下
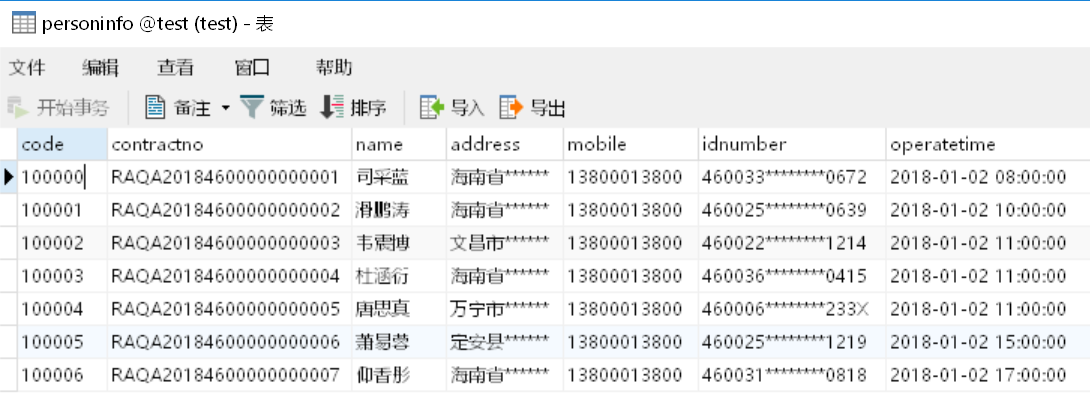
A6:使用close()函数关闭 A4 建立起的 MySQL 数据源连接。
1.4.7.3 数据库分到数据库
使用集算器 SPL 编码实现的数据库分发到数据库的脚本如下(均以 MySQL 为例):
A |
B |
||
1 |
同上 |
/引入外部姓名字典表,用于随机组合生成姓名信息 |
|
2 |
=connect("MySQL") |
/连接 MySQL 数据源 |
|
3 |
=A2.cursor("select * from personinfo_copy") |
/游标读取 MySQL 中 personinfo_copy 表待脱敏数据 |
|
4 |
同上 A3 单元格 |
/按照脱敏规则进行数据表脱敏 |
|
5 |
>A2.update(A4,personinfo_copy_test,code,contractno, name,address,mobile,idnumber,operatetime;code) |
/执行 update 更新,直接将脱敏数据导出到数据库的 personinfo_copy_test 表中 |
|
6 |
>A2.close() |
/关闭数据库连接 |
|
A1:同上。
A2:连接 MySQL 数据源。
A3:游标读取 MySQL 中表“personinfo_copy”的待脱敏数据。该表的数据如下:
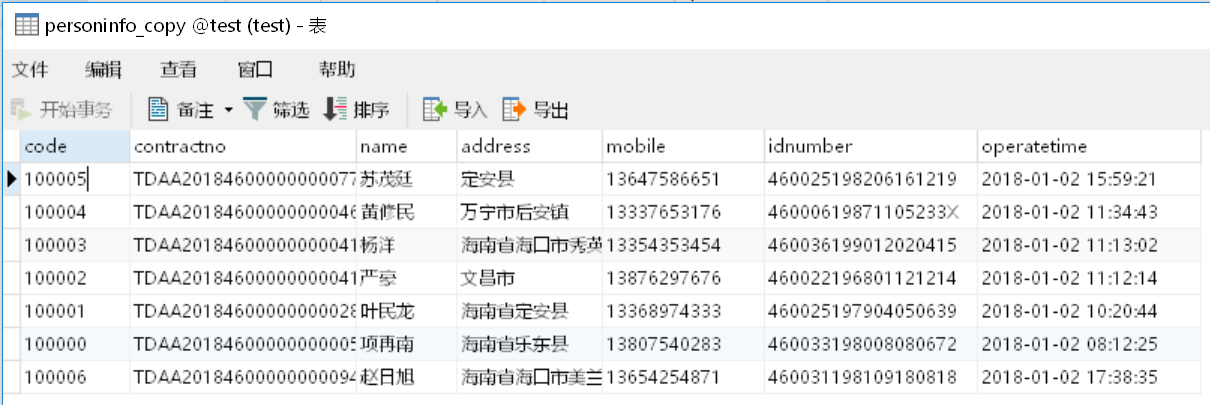
A4:同上。
A5:更新 MySQL 数据库中“personinfo_copy_test”库表的数据。使用update()将单元格 A3 的游标数据更新到 MySQL 数据库的“personinfo_copy_test”库表中。结果如下:
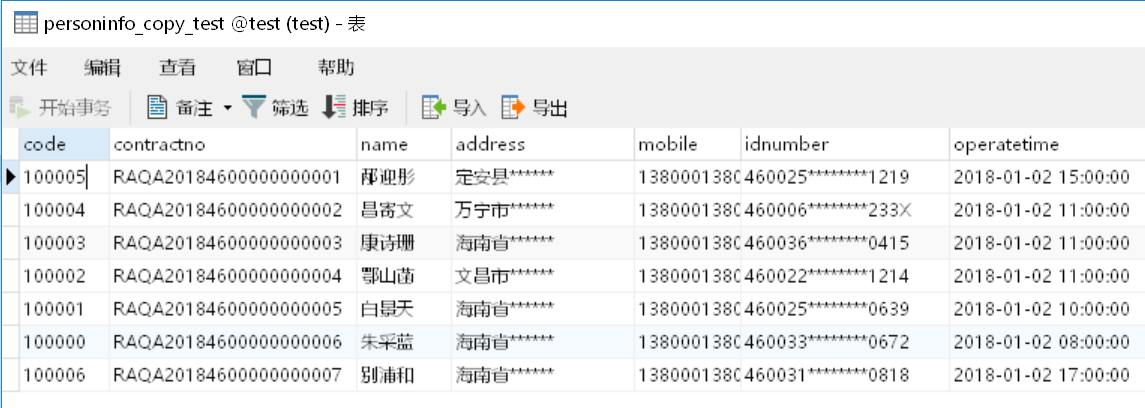
A6:使用close()函数关闭 A2 建立起的 MySQL 数据源连接。
1.4.7.4 数据库分到文本
使用集算器 SPL 编码实现的数据库(以 MySQL 为例)分发到文本的脚本如下:
A |
B |
||
1 |
同上 |
/引入外部姓名字典表,用于随机组合生成姓名信息 |
|
2 |
同上 |
/连接 MySQL 数据源 |
|
3 |
同上 |
/游标读取 MySQL 中 personinfo_copy 表待脱敏数据 |
|
4 |
同上 A4 单元格 |
/按照脱敏规则进行数据表脱敏 |
|
5 |
>file("脱敏数据结果表.txt").export@at(A4) |
/直接导出到文本文件 |
|
6 |
>A2.close() |
/关闭数据库连接 |
|
A1-A4:同上。
A5:直接将脱敏的数据库(MySQL)数据分发到文本文件。分发到文本的脱敏结果同上。
A6:使用close()函数关闭 A2 建立起的 MySQL 数据源连接。
1.5 脱敏数据报表查询实例
下面我们就结合上面介绍的数据脱敏方法,具体实现一个可以动态配置是否脱敏数据的报表查询实例,大致流程如下: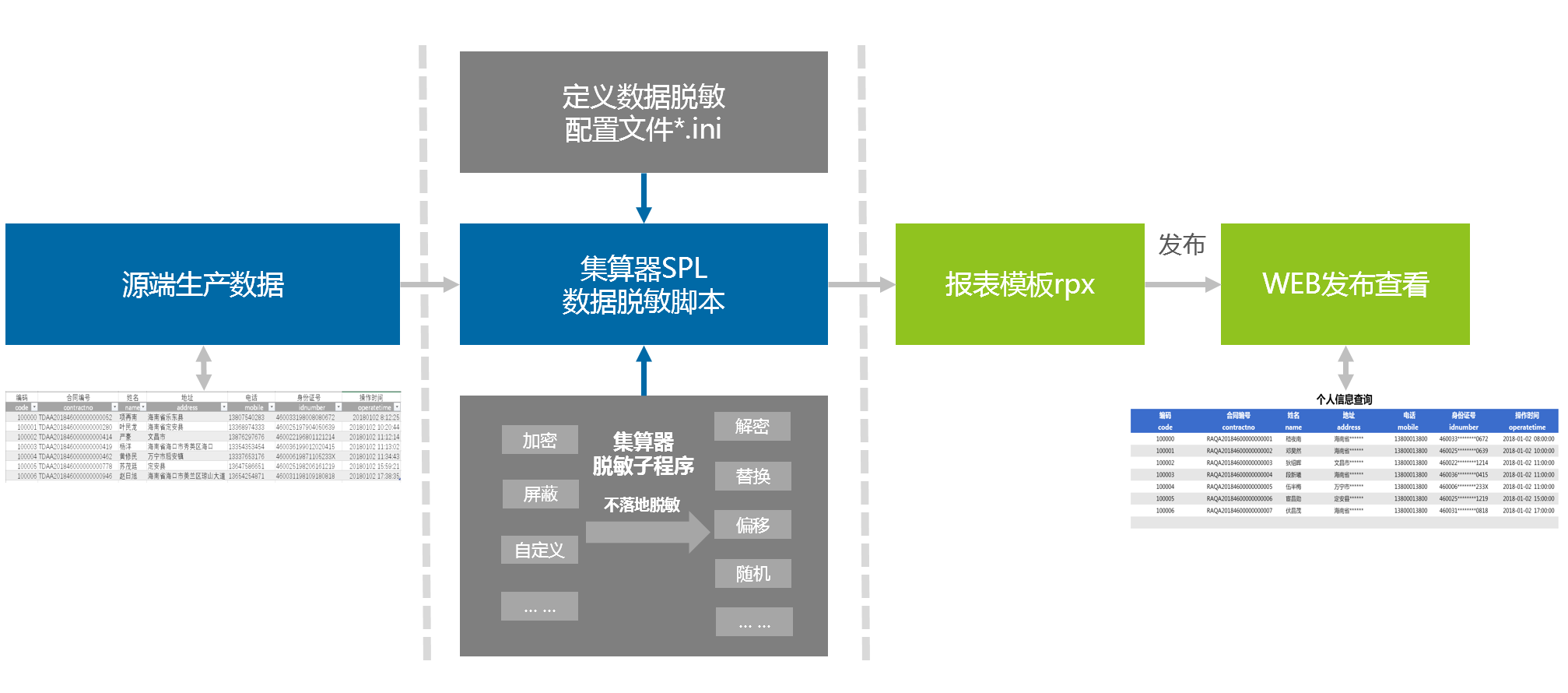
1.5.1 集算器数据脱敏 SPL 脚本准备
利用上面已有的"数据脱敏验证表.txt" 文本数据,实现脱敏数据报表查询,具体脚本如下:
A |
B |
C |
D |
|
1 |
=file("姓氏.txt").import@it() |
=file("名字.txt").import@it() |
/引入外部姓名字典表,用于随机组合生成姓名信息 |
|
2 |
func |
/调用配置文件中的数据脱敏规则进行数据脱敏 |
||
3 |
=file("数据脱敏规则配置.ini").property(A2(2)) |
|||
4 |
if type=="type2" |
=eval(B3,"A1","A1","B1","B1") |
/特殊规则的动态解析替换 "?" 值 |
|
5 |
=eval(B3,A2(1)) |
/通用规则的动态解析替换 "?" 值 |
||
6 |
return ${B3} |
|||
7 |
=file("数据脱敏验证表.txt").cursor@t() |
|||
8 |
if type!=0 |
= |
||
9 |
=A7.run(contractno=func(A2,[contractno,"type1"]),name=func(A2,[name,"type2"]),address=func(A2,[address,"type3"]), mobile=func(A2,[mobile,"type4"]),idnumber=func(A2,[idnumber,"type5"]),operatetime=func(A2,[operatetime,"type6"])) |
/按照脱敏规则进行数据表脱敏 |
||
10 |
return if(type!=0,B9,A7) |
/说明:参数 type 控制是否对数据进行脱敏 (0: 不脱敏) |
||
A1-B1:引入外部字典表“姓氏”和“名字”的文本数据,用于随机组合生成姓名信息。
A2:定义一个子程序。使用func函数定义一个通用的数据脱敏规则处理子程序,该子程序主要是调用配置文件中的数据脱敏规则进行数据脱敏。不同数据字段可以根据自身特点和业务要求进行规则复用。关于子程序的内容可以参考:集算器 -> 教程 -> 高级代码 ->子程序文档说明。
B3:读取数据脱敏规则配置文件信息。使用property()函数从“数据脱敏规则配置.ini”属性文件中读取 type 属性值。
B4-B5:使用动态解析并计算规则配置文件中的规则,实现对应字段的数据脱敏处理。其中,子程序中使用eval()函数动态解析并计算表达式,实现动态解析并替换脱敏规则配置文件(*.ini)中的 "?" 值,增加一个 type 值判断,将一般 type 中的 "?" 替换为调用 func 子程序主格的位置值,对引入外部数据字典表的 tpye2 规则,单独判断替换 "?" 值为外部字典所在单元格值,最终计算替换的表达式并执行对应字段的数据脱敏。
B6:使用宏动态计算表达式并返回运算结果,使用return函数将从属性配置文件中读取的 type 属性值通过“${}”宏替换并返回运算结果给被 B9 单元格调用的程序中。
A7:游标获取未脱敏的源端生产数据。
A8:通过传递的网格参数 type(type=0:不脱敏)值判断是否对数据脱敏,如果脱敏,则执行 B9 单元格的源端生产数据的脱敏处理。
B9:按照脱敏规则进行数据表脱敏,直接调用 A2 主格子程序 func 进行数据脱敏。
A10:根据 type 值返回对应的脱敏或未脱敏数据。
接下来,需要在集算器设计器的功能菜单“程序 -> 网格参数”中设置一个参数“type”,用于接收报表参数传递进行是否脱敏的数据权限控制。
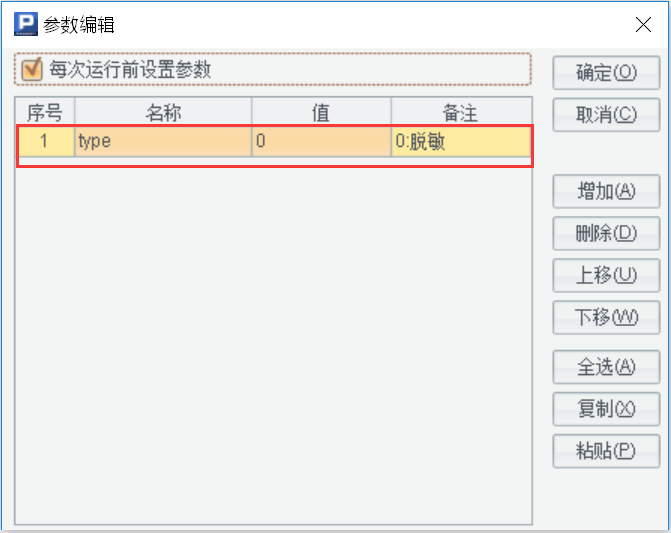
至此,集算器的 SPL 脚本编写和设置完成,下一步进行“数据脱敏规则配置.ini”文件的新建设置。
1.5.2 数据脱敏规则配置文件
文件“数据脱敏规则配置.ini”为集算器 SPL 脚本提供了对数据字段的脱敏规则配置,从而实现脱敏规则与脚本分离的设计,可以在不修改脚本的情况下自定义脱敏规则。当然,这个配置文件也可以数存储在数据库中,提供全局的脱敏规则配置管理。该配置文件的内容如下:

配置文件说明:#自定义配置脱敏规则,使用 eval() 函数实现动态解析替换解析 "?",通常 type 中的 "?" 是指固定调用 func 子程序的主格,这里 tpye2 规则特殊,需要单独判断替换 "?"。
【注意】这里仅是提供一种脱敏规则的配置思路,目的是可以最大限度的复用和灵活调用,相似的数据字段就不需要重复定义和编写脱敏规则了。实际应用中,程序员们可以根据需求自定义配置。
1.5.3 报表模板准备
使用最新版本的润乾报表 V2018 版本开发一张报表模板,并设置报表是否脱敏参数“type”(与集算器 SPL 脚本中的网格参数对应使用)。

设置集算器 SPL 脚本为报表的数据集“ds1”,选中对应的 dfx 脚本,并配置 type 参数表达式,具体如下:
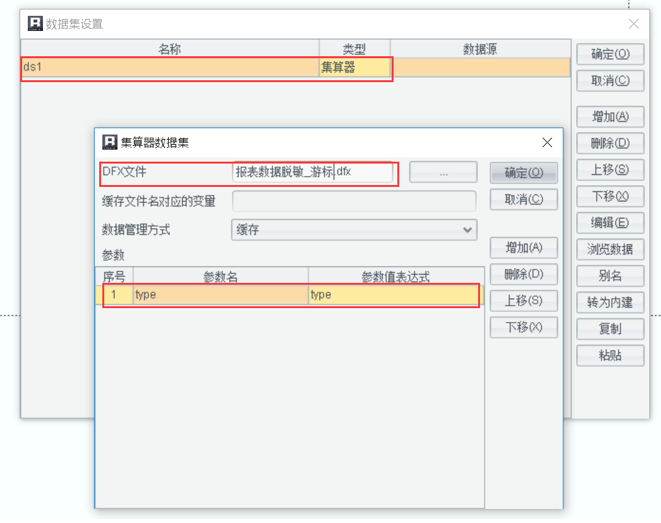
开发的报表模板“报表数据脱敏.rpx”如下:

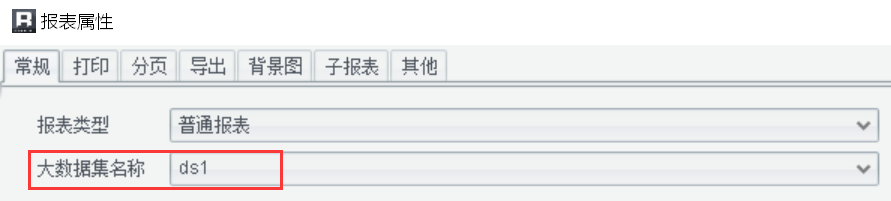
【注意】这里面调用的集算器数据集返回的是游标,需要在报表属性 -> 常规 设置集算器数据集为大数据集,并且该功能需要报表产品包含集算器授权。
1.5.4 脱敏数据报表发布
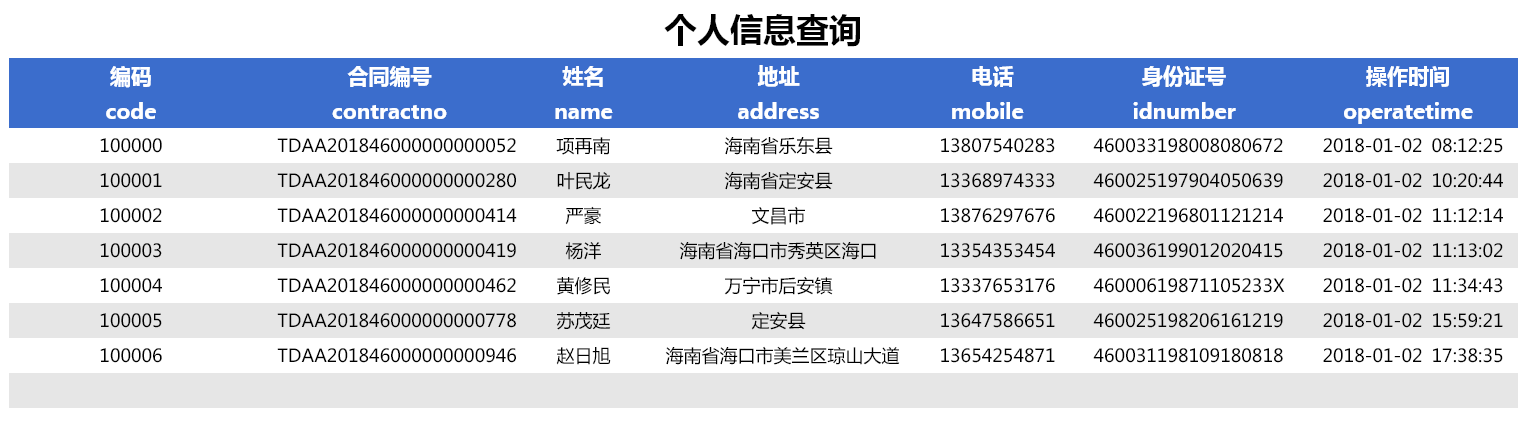
直接在报表设计器中启动 web 服务,使用浏览器浏览报表,当设置参数 type 值为“0”不脱敏时,报表展示数据如下:
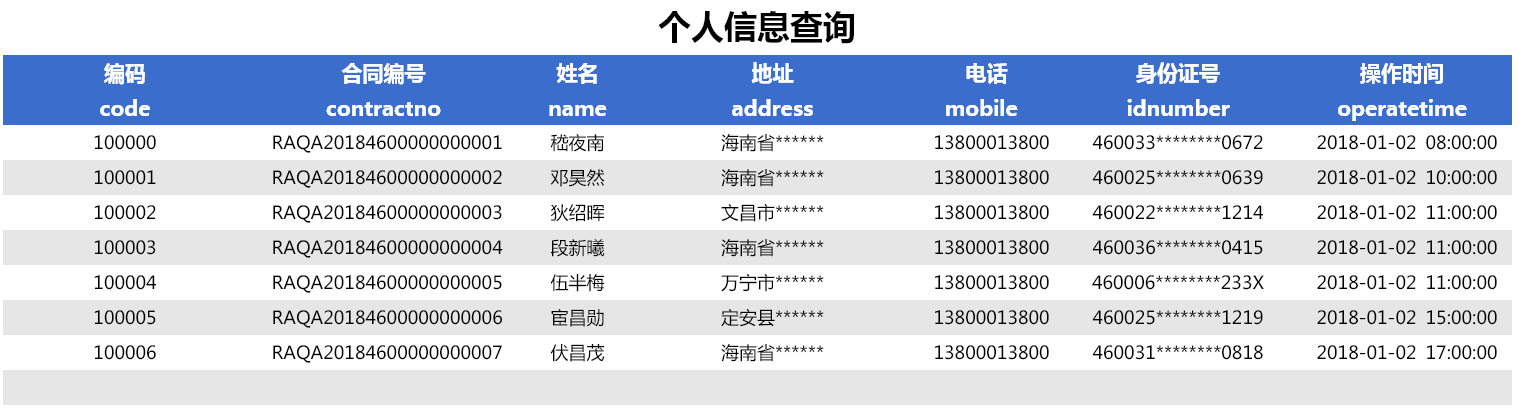
当参数 type 设置非“0”值时,报表展示数据如下:
1.5.5 脱敏数据报表查询总结
这个脱敏数据报表查询实例有以下四个特点:
l 1)直接对源数据脱敏后在报表 WEB 端进行数据查询和展示。
没有按常规数据脱敏的方式,先将脱敏数据进行分发入库或入文件,而是直接将数据使用集算器 SPL 脚本进行脱敏,配合报表的大数据集异步数据加载实现了大数据的即时脱敏数据查询展示。免去源数据脱敏 -> 目标入库 -> 数据展示的目标入库步骤。
l 2)免去新建数据脱敏库步骤,减少脱敏工作量。
为了应对一些老项目或特殊情况,比如脱敏的数据表都是明文显示,但是不能分发或新建脱敏后的数据库表,通过对明文数据直接抽取加密,免去新建脱密库步骤,减少整体脱敏工作量。
l 3)自定义配置数据脱敏规则。
可以灵活配置规则文件,满足不同的规则配置需求。
l 4)动态控制数据是否开启脱敏权限。
可以根据平台用户查看数据的权限,动态的传递参数值控制是否对数据进行脱敏显示,一方面防止数据的泄密,从底层保证数据安全,另一方面也为高权限客户提供查看敏感数据的途径。


你好,显示字段名为不能识别的表达式是怎么回事啊 =A1.run(idnumber=left(string(idnumber),6)+“********”+
right(string(idnumber),4)) 不能识别的表达式: idnumber 我换了我自己的字段名 然后 = 左边不加引号, 右边加双引号 不报错了 但是值没变 求教
验证了一下文章中的代码,应该是没错的,你再看看?