


10 行代码提取复杂 Excel 数据
【摘要】
把 Excel 文件导入关系数据库是数据分析业务中经常要做的事情,但许多 Excel 文件的格式并不规整,需要事先将其中的数据结构化后再用 SQL 语句写入数据库。而一般情况下,结构化的工作量会比较大,而且很难通用,每次都要针对文件格式进行分析后再进行开发。
集算器的 SPL 语言是一款高效、灵活的工具,它能够轻松读取 excel 数据,然后结构化成“序表”后导入数据库。使用 SPL 语言后,以往需要编写数千行代码才能完成的 Excel 数据结构化入库工作,现在只需要不到 10 行代码就可以胜任,简单情况下甚至只需要 2、3 行代码!真的这么神奇吗?让我们去乾学院看看这些高招吧:10 行代码提取复杂 Excel 数据
10行代码提取复杂Excel数据
下面我们将分情况讨论如何利用集算器将Excel数据进行结构化。文中用到的函数请参看集算器文档《函数参考》。
1. 普通行式
先看最简单的情况:如下图所示,Excel文件中第一行是列标题,从第二行开始,每行是一条数据记录。
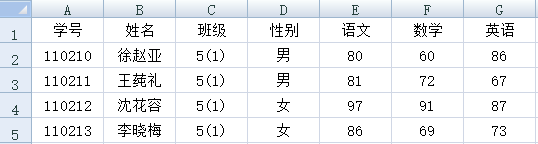
集算器处理这种文件也非常简单:
A |
|
1 |
=file( "学生成绩表.xlsx" ).xlsimport@t() |
2 |
=connect("demo") |
3 |
=A2.update(A1,xscj) |
A1 打开“学生成绩表.xlsx”文件并导入成序表,选项@t表示文件第一行是列标题
A2 连接demo数据库
A3 将A1中的序表存入到demo数据库的xscj表中,由于表中的列名和序表中的字段名一样,所以只需指定数据表名即可。update函数的更详细用法请查阅函数文档。
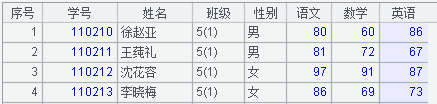
A1中得到的序表如下图所示:
A2、A3两步连接数据库和将序表存入数据库的方法是通用的,所以后面的例子中将不再写这两步,只关注于如何把Excel中的数据结构化成序表。
2. 多行表头行式
大多数时候,Excel文件都不会象上例那么简单,表头往往比较复杂,有表名、项目名、页码、填表人、填写日期等等。比如这个样子:

对于这种表,我们在读取时就要跳过表头,直接从数据行开始读。
A |
|
1 |
=file( "措施项目清单与计价表.xlsx" ).xlsimport(;1,5) |
2 |
=A1.rename(#1:序号,#2: 项目编码,#3: 项目名称,#4: 计量单位,#5: 数量,#6: 单价,#7: 合价 ) |
A1 打开文件并导入数据成序表,参数“1,5”表示读第一个 sheet,从第 5 行开始读,一直读到文件结尾
A2 将 A1 中读到的序表列名依次改为“序号、项目编码、项目名称、计量单位、数量、单价、合价”,即要存入的数据表的列名。
运行后 A2 中的序表如下:
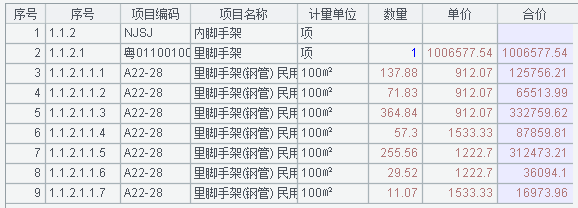
3. 自由格式
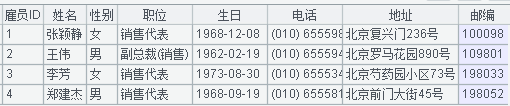
有时Excel文件的数据并不是网格式的规则表,而是字段名后紧跟着字段值的自由格式,如下图的雇员信息表:
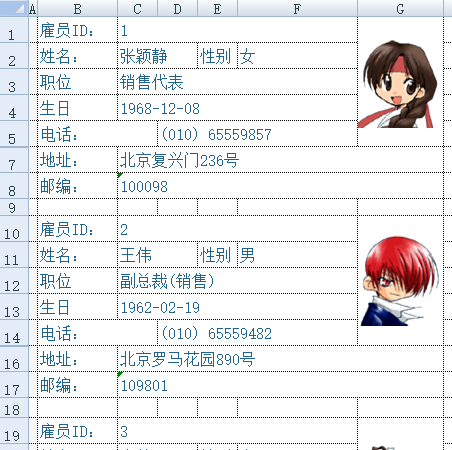
每个雇员信息占据9行,依次往下排列。对这种文件,该怎么结构化呢?请看:
A |
B |
C |
|
1 |
=create(雇员 ID, 姓名, 性别, 职位, 生日, 电话, 地址, 邮编 ) |
||
2 |
=file("雇员信息表.xlsx").xlsopen() |
||
3 |
[C,C,F,C,C,D,C,C] |
[1,2,2,3,4,5,7,8] |
|
4 |
for |
=A3.(~/B3(#)).(eval($[A2.xlscell(]/~/")")) |
|
5 |
if len(B4(1))==0 |
break |
|
6 |
>A1.record(B4) |
||
7 |
>B3=B3.(~+9) |
||
A1 创建列名为“雇员 ID, 姓名, 性别, 职位, 生日, 电话, 地址, 邮编”的空序表
A2 打开 Excel 数据文件
A3 定义雇员信息所在单元格列号序列
B3 定义雇员信息所在单元格行号序列
A4 用 for 循环读取每个雇员信息
B4 A3.(~/B3(#))先算出当前雇员单元格编号序列, 再读出这些单元格值组成雇员信息序列。第一次循环时为 [C1,C2,F2,C3,C4,D5,C7,C8],第二次循环时为[C10,C11,F11,C12,C13,D14,C16,C17]……每次行号加 9。$[A2.xlscell(] 与 "A2.xlscell(" 相同,都是表示一个字符串,它的好处是在 IDE 中编写程序时,如果 A2 单元格的编号发生了变化,$[A2.xlscell(]中的 A2 会自动变化,比如在 A2 前插入了一行,这个表达式就会变成 $[A3.xlscell(],而用引号的话,就不会自动变了。
B5 判断雇员 ID 值是否为空,为空则退出循环,结束运行
B6 将一条雇员信息存入 A1 序表尾
B7 让雇员信息的行号序列都加上 9,读取下一条雇员信息
运行后得到的 A1 序表如下:
4. 交叉表
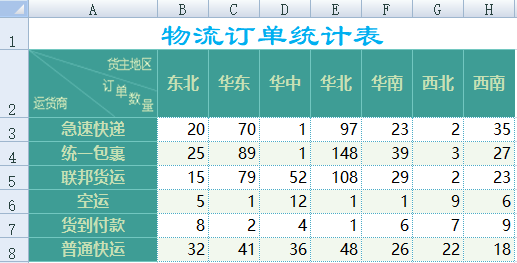
Excel中还有交叉表格式的数据,如下图:
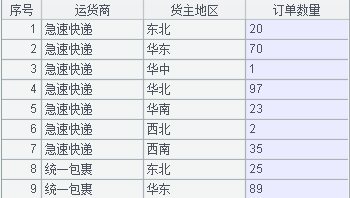
数据结构化程序如下:
A |
|
1 |
=file("交叉表.xlsx").xlsimport@t(;1,2) |
2 |
=A1.rename(#1:运货商) |
3 |
=A2.pivot@r(运货商;货主地区,订单数量) |
A1 打开文件并导入数据成序表,参数“1,2”表示读第一个 sheet,从第 2 行开始读,一直读到文件结尾。选项 @t 表示开始行是列标题。
A2 由于第二行第一个单元格是图片,读的数据为 null,第一列没有列标题,所以将第一列列名改为运货商。
A3 以运货商为分组,对序表数据进行行列转换,选项 @r 表示将列数据转换为行数据,转换后新的列名分别为“货主地区”、“订单数量”。
运行后得到的 A3 序表如下:
5. 主子表
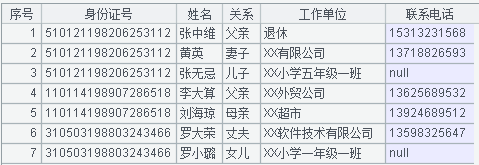
在下图所示的员工信息登记表中,除了有员工本人的信息外,还有他的家庭成员信息。每个 sheet 保存一个员工的相关信息,所以有多少员工,就有多少个 sheet。

对这种主子表结构的数据,需要创建两个序表分别保存主表和子表的数据,集算器程序如下:
A |
B |
C |
|
1 |
=create(身份证号,姓名,性别,出生日期,民族,手机号,部门,家庭地址,婚姻状况,入职时间) |
||
2 |
=create(身份证号,姓名,关系,工作单位,联系电话) |
||
3 |
[B4,B3,D3,F3,H3,F4,H4,B5,F5,H5] |
||
4 |
=file("员工信息表.xlsx").xlsopen() |
||
5 |
for A4 |
||
6 |
=A3.(A4.xlscell(~,A5.stname)) |
>A1.record(B6) |
|
7 |
=A4.xlsimport@t(家庭成员,姓名,关系,工作单位,联系电话;A5.stname,6) |
||
8 |
=B7.rename(家庭成员:身份证号) |
>B8.run(身份证号=B6(1)) |
|
9 |
>A2.insert@r(0:B8) |
||
A1 创建列名为“身份证号, 姓名, 性别, 出生日期, 民族, 手机号, 部门, 家庭地址, 婚姻状况, 入职时间”的空序表,用于保存主表员工信息
A2 创建列名为“身份证号, 姓名, 关系, 工作单位, 联系电话”的空序表,用于保存子表员工家庭成员信息
A3 定义主表员工信息所在单元格序列
A4 打开 Excel 数据文件
A5 循环读取 Excel 文件各 sheet 数据
B6 读取员工信息序列
C6 将 B6 读取的员工信息保存到序表 A1
B7 从第 6 行开始读取员工家庭成员信息,只读指定的“家庭成员, 姓名, 关系, 工作单位, 联系电话”5 列
B8 将 B7 序表的家庭成员列改名为身份证号
C8 为 B8 序表的身份证号列赋值为员工信息中的身份证号
B9 将 B8 中的员工家庭成员信息保存到序表 A2
程序运行后,序表 A1 如下图所示:

序表 A2 如下图所示:
上面这些情况基本罗列了常见的 Excel 数据格式,如果遇到更复杂的文件,也可以灵活使用例子中的技巧予以应对。简单总结一下,集算器提供了非常灵活的在 excel 文件中定位和读取数据的功能,既可以成片读取网格数据,也可以精确定位单元格进行读取。再结合特有的“序表”对象,以往需要编写数千行代码才能完成的 Excel 数据结构化入库工作,现在只需要不到 10 行代码就可以胜任,简单情况下甚至只需要 2、3 行代码!
相关文章:
例子程序:
Excel 去除重复数据
去除 csv 文件中的重复行
根据列名读入数据并变换
读入指定列
每隔 5 行做统计
两种分隔符
横向拼接多段组成
按列的位置取数


主子表:
单元格 B6 中有错误
xlscell:函数参数类型错误
文章写的时间有点久了,后来 SPL 程序有改动,这篇文章没有跟上修改
B6、B7 单元格已改正,谢谢!
另外可以阅读后来写的文章:http://c.raqsoft.com.cn/article/1631755223416